
Pandas的数据初步探索(学习笔记)
Pandas数据结构
与R语言一样,python也常用于数据分析。除了常用的科学计算库Numpy和绘图库matplotlib之外,pandas也给python提供了强大助力。
首先要认识pandas的两种强大的数据结构Series和DataFrame。其中Series就是序列,类似一维数组,索引在左边,值在右边;而DataFrame则是类似于二维数组。
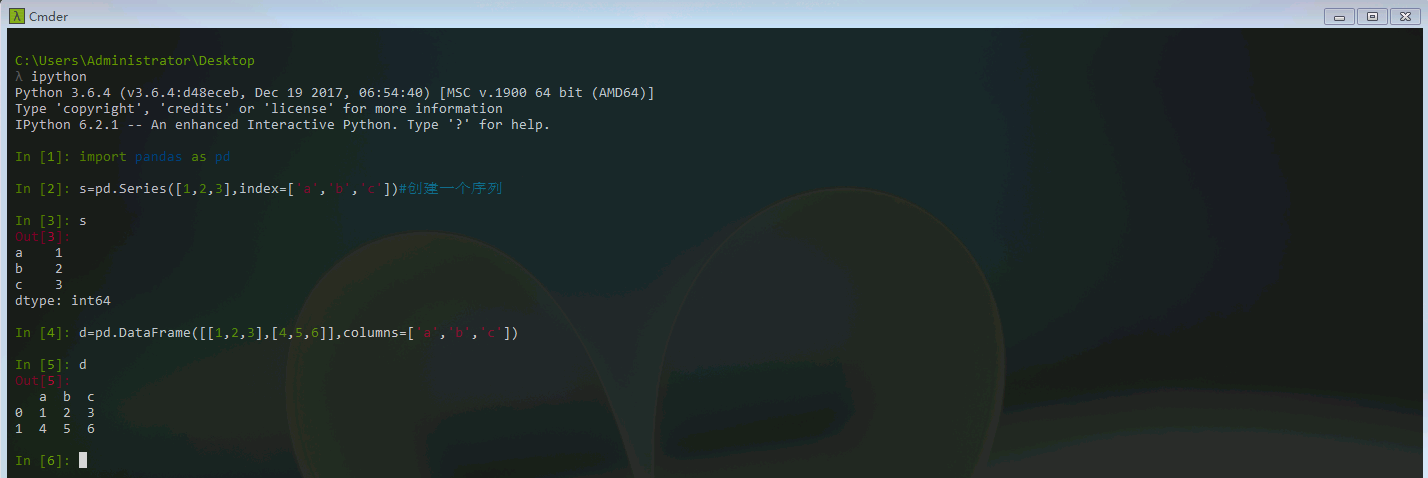
创建的Series进行numpy计算,都会保留值与索引之间的链接。可以知道Series的数据结构跟python的字典非常类似,可以用字典来直接创建Series:obj=pd.Series(dict)。DataFrame也有索引功能,可以用read_excel()函数打开表格,进行常见的数据统计。
数据质量分析
在拿到数据之后,我们通常先需要先进行数据质量分析。数据质量分析就是检查原始数据中,是否存在不符合要求以及不能进行分析的数据。脏数据包括:
1、缺失值
a、删除缺失记录
b、对缺失值插补
c、不处理
2、异常值
a、简单统计量分析,如最大最小值描述
b、如果服从正态分布,利用3δ原则。异常值被定义为一组测定值中与平均值的偏差超过三倍标准差的值
c、箱型图分析(对数据没有任何要求)
3、不一致的值
4、重复数据以及含有特殊符号
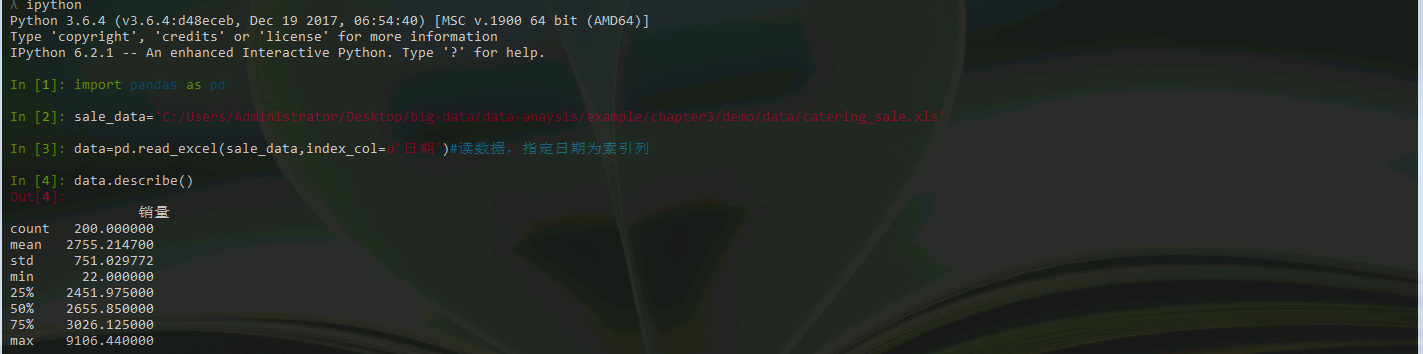
箱型图在数据异常检测方面有着非常好的稳定性。
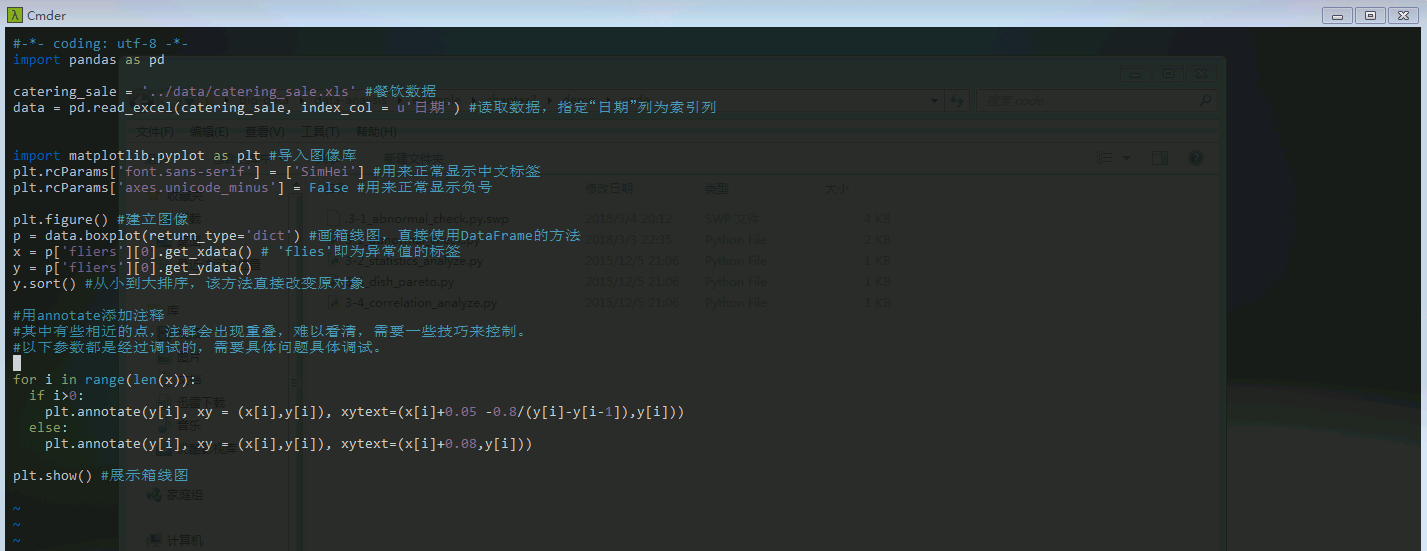
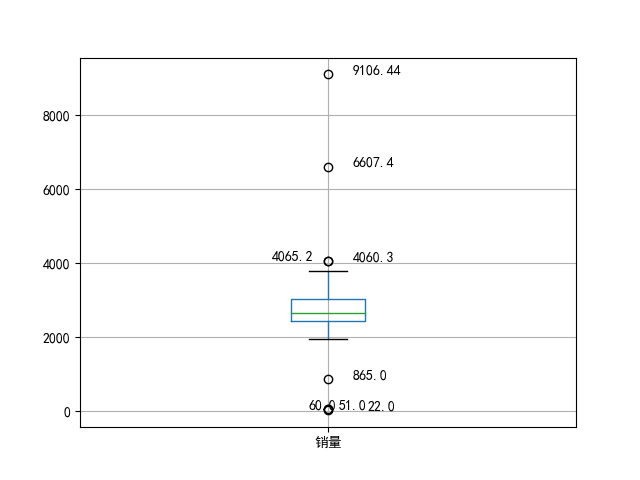
上图可以分析出22、51、60、6607.4、9106.44为异常值。然后就可以拟定过滤规则:
日销量在400以下5000以上为异常数据。编写程序过滤即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号