
python爬虫(8)——Xpath的应用实例:爬取腾讯招聘信息
上一篇文章,简单介绍了beautifulsoup这个解析器,下面来了解一个我非常喜欢的工具——Xpath。
Xpath是一门在XML文档中查找信息的语言,可用来在XML文档中对元素和属性进行遍历。推荐各位使用Google浏览器吧Chrome,安装一个插件工具Xpath Helper。文档传送门:http://www.w3school.com.cn/xpath/xpath_intro.asp


我们在chrome中打开Xpath Helper插件,右键检查元素,分析网页结构,我们可以用上图所示的方法提取到职位名称。但是提取不到类别和地址,经过分析后发现,隔行的class属性不一致。实际上在这里,我们可以爬下职位链接,然后进行深度爬取。
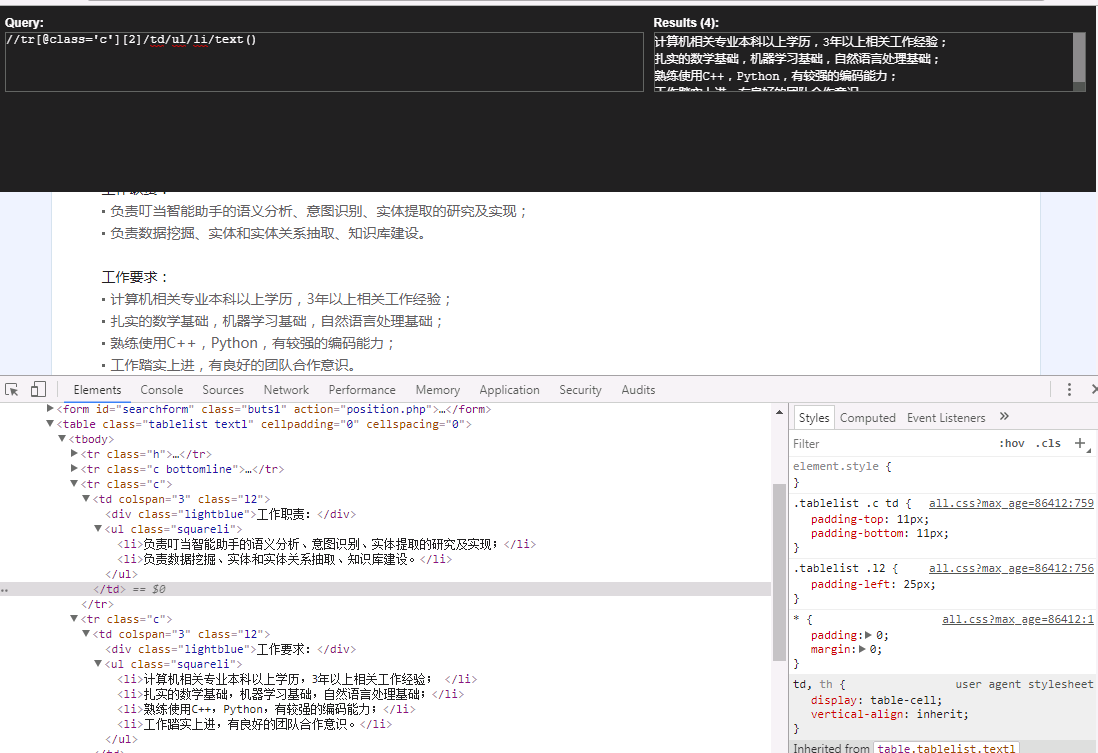
xpath提取时,要注意将网页转换成html文档,代码如下(未保存本地,只是显示在命令终端):
1 import requests 2 from lxml import etree 3 4 5 6 7 8 def get_info(page_url): 9 page_response=requests.get(page_url,headers=headers) 10 page_html=page_response.text 11 page_HTML=etree.HTML(page_html) 12 #利用xpath提取所需要的信息 13 position_name=page_HTML.xpath("//tr[@class='h']/td/text()") 14 position_duty=page_HTML.xpath("//tr[@class='c'][1]/td/ul/li/text()") 15 position_need=page_HTML.xpath("//tr[@class='c'][2]/td/ul/li/text()") 16 17 print("职位名:"+ "\n" + " "*4 , position_name) 18 print("岗位职责:"+ "\n" + " "*4 , position_duty) 19 print("能力需求:"+ "\n" + " "*4 , position_need,"\n"*3) 20 21 22 23 if __name__=="__main__": 24 page=int(input("请输入需要爬取的页数:")) 25 for item in range(0,page): 26 url="https://hr.tencent.com/position.php?lid=&tid=&keywords=python&start=" + "ietm*10" + "#a" 27 headers={"User-Agent":"Mozilla/5.0(Macintosh;U;IntelMacOSX10_6_8;en-us)AppleWebKit/534.50(KHTML,likeGecko)Version/5.1Safari/534.50"} 28 response=requests.get(url,headers=headers) 29 #利用lxml解析网页 30 html=response.text 31 HTML=etree.HTML(html) 32 33 positionLink=HTML.xpath('//td[1]/a/@href') 34 for index in range(len(positionLink)-1): 35 #爬取职位链接,进行深度提取信息 36 page_url="https://hr.tencent.com/" + positionLink[index] 37 #print(page_url) 38 get_info(page_url)
效果图如下
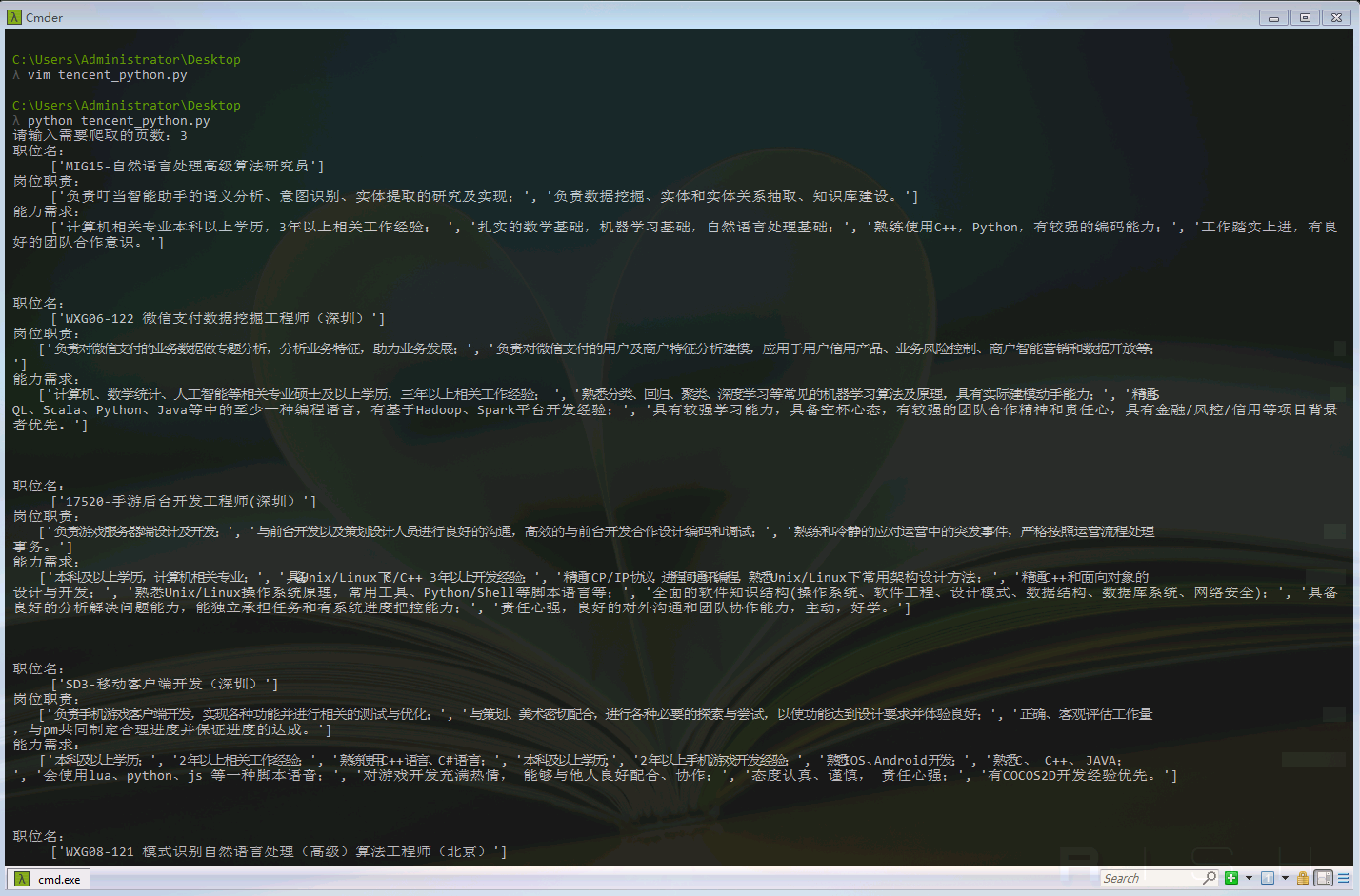
可以看到我们提取到了所需要的信息。xpath的使用要比正则表达式简单,虽然性能比不上正则,但是也是网页提取的一大利器。我们在后来的信息提取中可以很方便的直接使用它,而不需要安装依赖库。
版权声明:本文为博主原创文章,未经博主允许不得转载。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号