
Hadoop学习篇 2 初识 Hadoop
在一个全配置的集群上,运行Hadoop意味着在网络分布的不同服务器上运行一组守护进程 (daemons),这些守护进程或运行在单个服务器上,或运行与多个服务器上,他们包括:
(1) NameNode(名字节点)
(2) DataNode(数据节点)
(3) Secondary NameNode (次名节点)
(4) JobTracker (作业跟踪节点)
(5) TaskTracker (任务跟踪节点)
NameNode
被认为是Hadoop守护进程中最重要的一个,可以说,NameNode就是一个大脑。

运行NameNode会消耗掉大量的内存和I/O资源,因此,为了减轻机器的负载,驻留NameNode的服务器一般不会负责MapReduce的计算、存储用户数据。这也意味着,NameNode不会和JobTracker\TashTracker存在于同一台服务器上。一旦NameNode服务器出现宕机,造成的影响一般会比较严重。
DataNode
每个集群的从节点上都会驻留一个DataNode的守护进程,来执行分布式文件系统的繁重工作——将HDFS数据快读取或写入到本地文件系统的实际文件中。当希望对HDFS文件进行读写时,文件被分割为多个块,有NameNode告知客户端每个数据块驻留在那个DataNode。客户端直接与DataNode守护进程进行通信,来处理与数据块对相对应的本地文件。DataNode与DataNode节点直接也可以直接进行通信,用于完成数据的复制。

上图解释了NameNode和DataNode节点的作用,NameNode指明了数据存放的名称和位置,分别为/user/chuck/data1 下的1、2、3文件和存储在 /user/james/data2下的
4、5文件。四个DataNode实现了1、2、3、4、5文件的复制。确保了任何一个DataNode节点失败后任然可以正常工作。DataNode会不断的向NameNode节点报告,将当前节点存储的数据块告知NameNode,为之提供本地修改的相关信息,同时接受指令的创建、移动或删除本地磁盘上的数据块。
Secondary NameNode

JobTracker
jobtracker守护进程是Hadoop和应用程序之间的纽带,一旦代码提交到集群上,JobTracker就会执行确定的任务,包括决定处理哪些文件,为不同的任务分配节点以及监控所有任务的运行,如果任务失败,jobTracker将会自动重启任务,但是所分配的节点可能会不同。
每个Hadoop集群只有一个JobTracker守护进程,他通常运行在服务器的主节点上。
TaskTracker

下面的图形描述了一个Hadoop集群的拓扑结构,这是一个主/从结构,特点是主节点上运行NameNode和JobTracker,而从节点上运行DataNode和TaskTracker。并使用独立的节点运行SSN,以防止主节点运行失败。
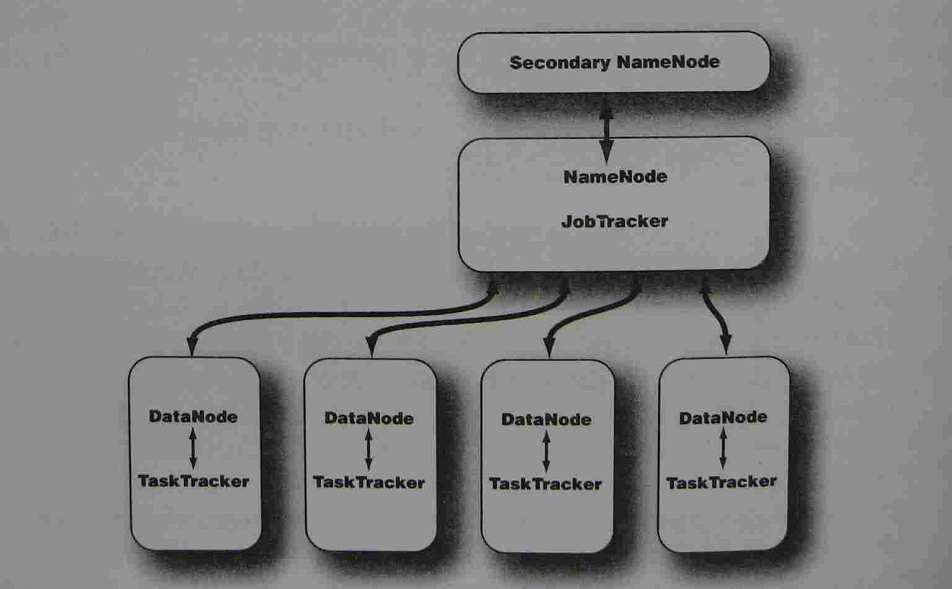
了解了以上信息,我们来关注一下Hadoop的NameNode和JobTracker究竟分别执行什么样的功能?
1、从存储角度来理解:集群是由一个Namenode和若干datanode组成,而secondary作为Namenode的一个备份

 浙公网安备 33010602011771号
浙公网安备 33010602011771号