
猫狗识别
(一)、选题的背景
猫狗识别,项目要解决的问题实际是一个计算机视觉领域的图像分类问题,图像分类一般的工作模式为给定一张图片,判断其属于某个有限类别集合中的哪一类。这个领域不仅非常有趣,而且具有非常大的应用价值和商业价值
(二)、机器学习案例设计方案
1.本选题采用的机器学习案例(训练集与测试集)的来源描述
本选题采用的机器学习训练集来源于百度图片下载:
猫的图片原:
狗的图片原:
猫狗图片下载后储存于D:\WorkSpace\Dataset\cats-vs-dogs\data\train目录下并重新命名,一共25000张图片
 2.采用的机器学习框架描述
2.采用的机器学习框架描述
采用的机器学习框架为Google的TensorFlow,TensorFlow实现了所谓的数据流图,其中的批量数据(“tensors”)可以通过图描述的一系列算法进行处理。
3.涉及到的技术难点与解决思路
(1).类内变异
数据集中具有多种类型的猫和狗。猫可以是“中华田园猫”,“英国短毛猫”,“缅甸猫”,“布偶猫”,“蓝猫”等。狗可以是“中华田园犬”,“柴犬”,“金毛寻回犬”,“西伯利亚雪橇犬”,“贵宾犬”等。
解决方法:加强训练。
(2).图片的像素大小不同
解决方法:改变图片的大小,定为每个图片宽高都为208像素

(三)、机器学习的实现步骤
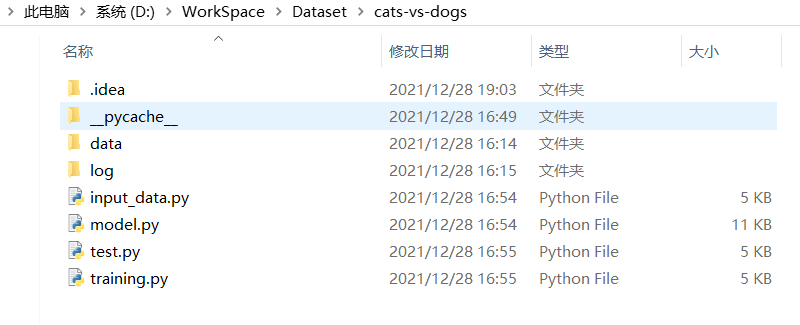
data文件夹:包含 test 测试集和 train 训练集
log文件夹:保存训练模型和参数
image文件夹: 存放训练图和预测结果图
input_data.py:负责实现读取数据,生成批次
model.py:负责实现神经网络模型
training.py:负责实现模型的训练以及评估
test.py: 从测试集中随机抽取一张图片, 进行预测是猫还是狗
先运行training.py来训练模型,训练完再运行test.py来测试图片进行预测猫或狗。
训练图(准确率与损失值):
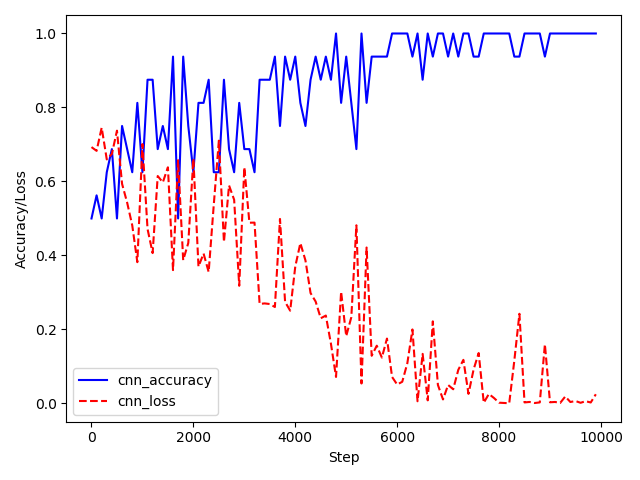
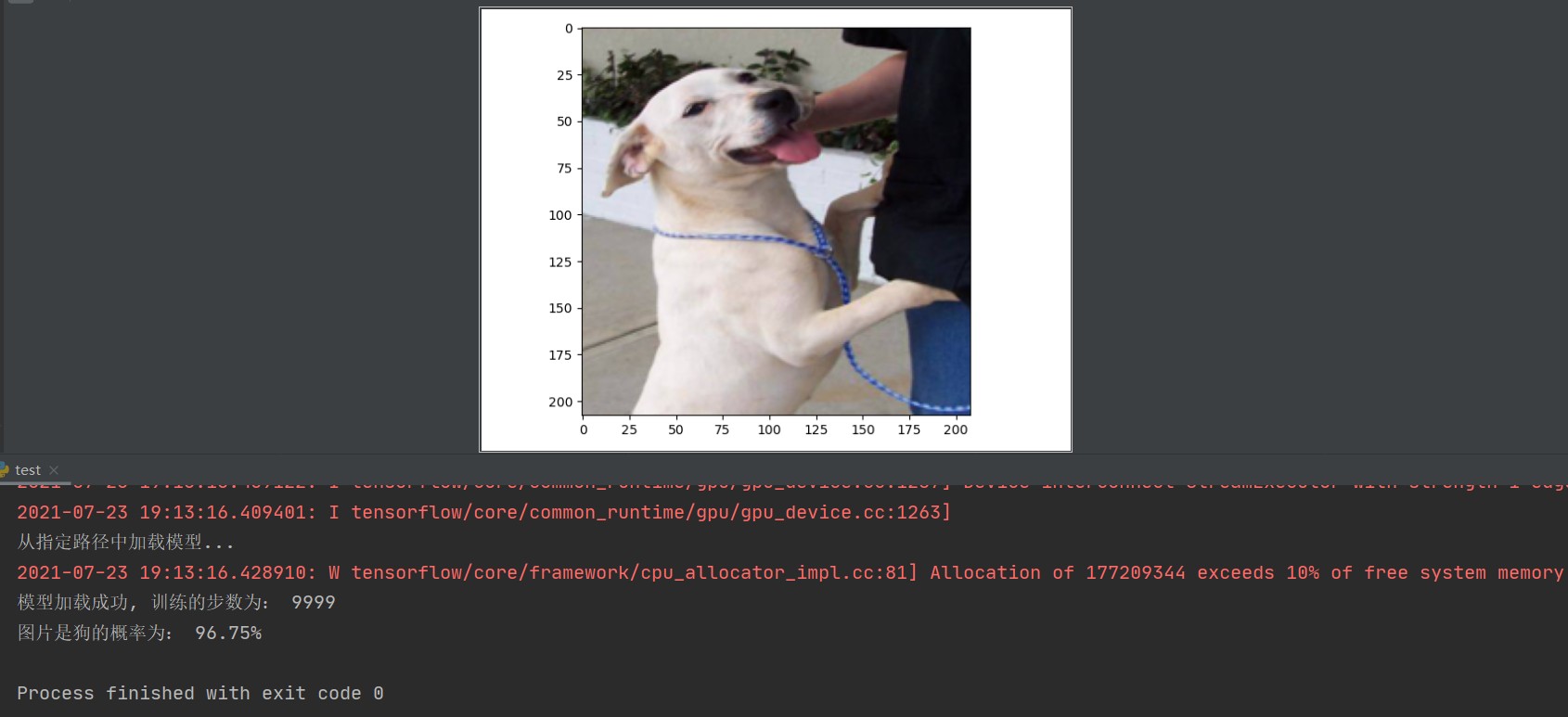
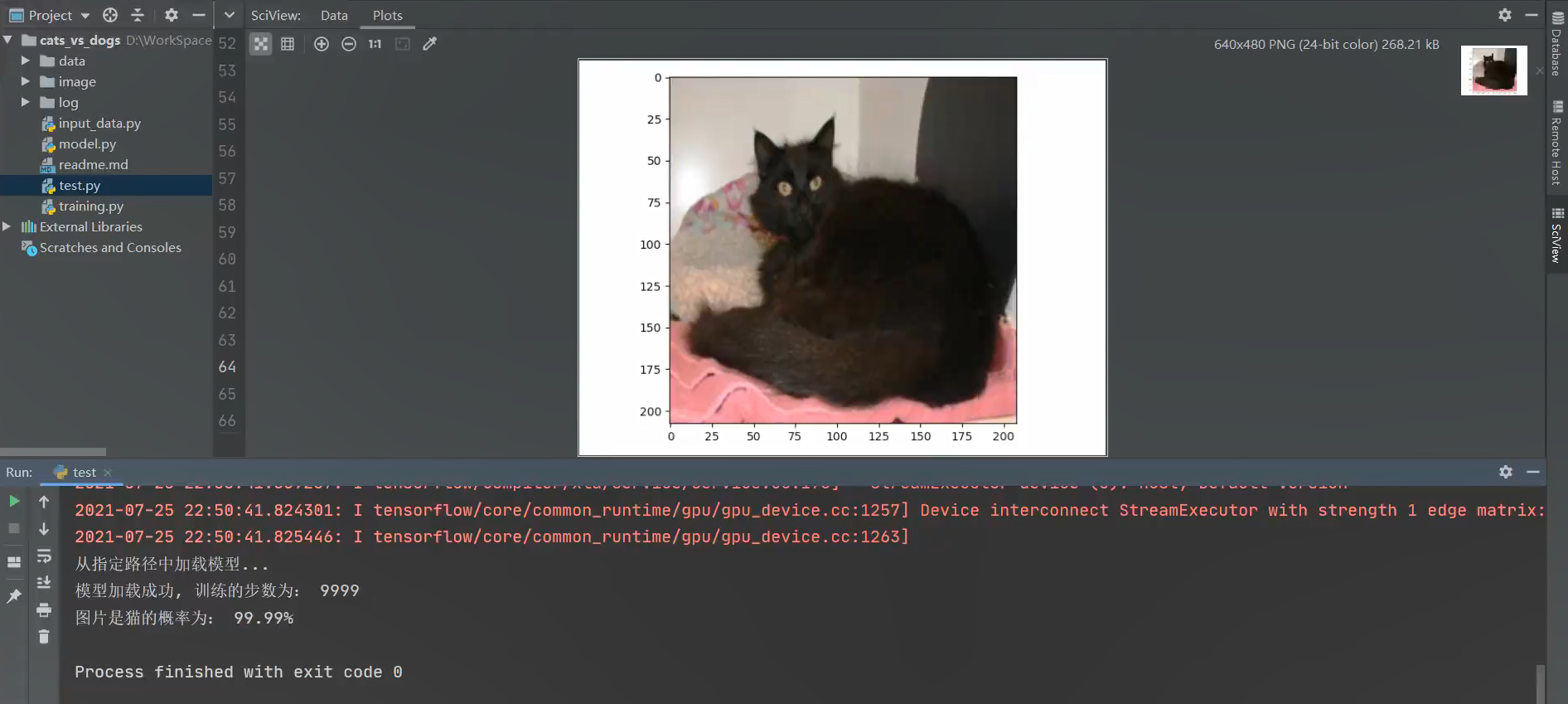
预测结果图:
input_data.py(读取训练数据)代码:
1 # import tensorflow as tf 2 import tensorflow.compat.v1 as tf 3 tf.disable_v2_behavior() 4 import numpy as np 5 import os 6 7 8 def get_files(file_dir): 9 """ 10 输入: 11 file_dir:存放训练图片的文件地址 12 返回: 13 image_list:乱序后的图片路径列表 14 label_list:乱序后的标签(相对应图片)列表 15 """ 16 # 建立空列表 17 cats = [] # 存放是猫的图片路径地址 18 label_cats = [] # 对应猫图片的标签 19 dogs = [] # 存放是猫的图片路径地址 20 label_dogs = [] # 对应狗图片的标签 21 22 # 从file_dir路径下读取数据,存入空列表中 23 for file in os.listdir(file_dir): # file就是要读取的图片带后缀的文件名 24 name = file.split(sep='.') # 图片格式是cat.1.jpg / dog.2.jpg, 处理后name为[cat, 1, jpg] 25 if name[0] == 'cat': # name[0]获取图片名 26 cats.append(file_dir + file) # 若是cat,则将该图片路径地址添加到cats数组里 27 label_cats.append(0) # 并且对应的label_cats添加0标签 (这里记作:0为猫,1为狗) 28 else: 29 dogs.append(file_dir + file) 30 label_dogs.append(1) # 注意:这里添加进的标签是字符串格式,后面会转成int类型 31 32 # print('There are %d cats\nThere are %d dogs' % (len(cats), len(dogs))) 33 34 image_list = np.hstack((cats, dogs)) # 在水平方向平铺合成一个行向量,即两个数组的拼接 35 label_list = np.hstack((label_cats, label_dogs)) # 这里把猫狗图片及标签合并分别存在image_list和label_list 36 temp = np.array([image_list, label_list]) # 生成一个2 X 25000的数组,即2行、25000列 37 temp = temp.transpose() # 转置向量,大小变成25000 X 2 38 np.random.shuffle(temp) # 乱序,打乱这25000行排列的顺序 39 40 image_list = list(temp[:, 0]) # 所有行,列=0(选中所有猫狗图片路径地址),即重新存入乱序后的猫狗图片路径 41 label_list = list(temp[:, 1]) # 所有行,列=1(选中所有猫狗图片对应的标签),即重新存入乱序后的对应标签 42 label_list = [int(float(i)) for i in label_list] # 把标签列表转化为int类型(用列表解析式迭代,相当于精简的for循环) 43 44 return image_list, label_list 45 46 47 def get_batch(image, label, image_W, image_H, batch_size, capacity): 48 """ 49 输入: 50 image,label:要生成batch的图像和标签 51 image_W,image_H: 图像的宽度和高度 52 batch_size: 每个batch(小批次)有多少张图片数据 53 capacity: 队列的最大容量 54 返回: 55 image_batch: 4D tensor [batch_size, width, height, 3], dtype=tf.float32 56 label_batch: 1D tensor [batch_size], dtype=tf.int32 57 """ 58 image = tf.cast(image, tf.string) # 将列表转换成tf能够识别的格式 59 label = tf.cast(label, tf.int32) 60 61 # 队列的理解: 62 # 每次训练时,从队列中取一个batch送到网络进行训练,然后又有新的图片从训练库中注入队列,这样循环往复。 63 # 队列相当于起到了训练库到网络模型间数据管道的作用,训练数据通过队列送入网络。 64 input_queue = tf.train.slice_input_producer([image, label]) # 生成队列(牵扯到线程概念,便于batch训练), 将image和label传入 65 # input_queue = tf.optimizers.slice_input_producer([image, label]) # Tensorflow 2.0版本 66 67 label = input_queue[1] 68 image_contents = tf.read_file(input_queue[0]) # 图像的读取需要tf.read_file(), 标签则可以直接赋值。 69 image = tf.image.decode_jpeg(image_contents, channels=3) # 使用JPEG的格式解码从而得到图像对应的三维矩阵。 70 # 注意:这里image解码出来的数据类型是uint8, 之后模型卷积层里面conv2d()要求传入数据为float32类型 71 72 # 图片数据预处理:统一图片大小(缩小图片) + 标准化处理 73 # ResizeMethod.NEAREST_NEIGHBOR:最近邻插值法,将变换后的图像中的原像素点最邻近像素的灰度值赋给原像素点的方法,返回图像张量dtype与所传入的相同。 74 image = tf.image.resize_images(image, [image_H, image_W], method=tf.image.ResizeMethod.NEAREST_NEIGHBOR) 75 image = tf.cast(image, tf.float32) # 将image转换成float32类型 76 image = tf.image.per_image_standardization(image) # 图片标准化处理,加速神经网络的训练 77 78 # 按顺序读取队列中的数据 79 image_batch, label_batch = tf.train.batch([image, label], # 进队列的tensor列表数据 80 batch_size=batch_size, # 设置每次从队列中获取出队数据的数量 81 num_threads=64, # 涉及到线程,配合队列 82 capacity=capacity) # 用来设置队列中元素的最大数量 83 84 return image_batch, label_batch
model.py(CNN神经网络模型)代码:
1 # import tensorflow as tf 2 import tensorflow.compat.v1 as tf 3 tf.disable_v2_behavior() 4 5 6 def cnn_inference(images, batch_size, n_classes): 7 """ 8 输入: 9 images:队列中取的一批图片, 具体为:4D tensor [batch_size, width, height, 3] 10 batch_size:每个批次的大小 11 n_classes:n分类(这里是二分类,猫或狗) 12 返回: 13 softmax_linear:表示图片列表中的每张图片分别是猫或狗的预测概率(即:神经网络计算得到的输出值)。 14 例如: [[0.459, 0.541], ..., [0.892, 0.108]], 15 一个数值代表属于猫的概率,一个数值代表属于狗的概率,两者的和为1。 16 """ 17 18 # TensorFlow中的变量作用域机制: 19 # tf.variable_scope(<scope_name>): 指定命名空间 20 # tf.get_variable(<name>, <shape>, <dtype>, <initializer>): 创建一个变量 21 22 # 第一层的卷积层conv1,卷积核(weights)的大小是 3*3, 输入的channel(管道数/深度)为3, 共有16个 23 with tf.variable_scope('conv1') as scope: 24 # tf.truncated_normal_initializer():weights初始化生成截断正态分布的随机数,stddev标准差 25 weights = tf.get_variable('weights', 26 shape=[3, 3, 3, 16], 27 dtype=tf.float32, 28 initializer=tf.truncated_normal_initializer(stddev=0.1, dtype=tf.float32)) 29 biases = tf.get_variable('biases', 30 shape=[16], 31 dtype=tf.float32, 32 initializer=tf.constant_initializer(0.1)) # 初始化为常数,通常偏置项biases就是用它初始化的 33 34 # strides = [1, y_movement, x_movement, 1], 每个维度的滑动窗口的步幅,一般首末位置固定都为1 35 # padding = 'SAME', 是考虑边界, 不足时用0去填充周围 36 # padding = 'VALID', 不考虑边界, 不足时舍弃不填充周围 37 # 参考:https://blog.csdn.net/qq_36201400/article/details/108454066 38 # 输入的images是[16,208,208,3], 即16张 208*208 大小的图片, 图像通道数是3 39 # weights(卷积核)的大小是 3*3, 数量为16 40 # strides(滑动步长)是[1,1,1,], 即卷积核在图片上卷积时分别向x、y方向移动为1个单位 41 # 由于padding='SAME'考虑边界,最后得到16张图且每张图得到16个 208*208 的feature map(特征图) 42 # conv(最后输出的结果)是shape为[16,208,208,16]的4维张量(矩阵/向量) 43 # 用weights卷积核对images图片进行卷积 44 conv = tf.nn.conv2d(images, weights, strides=[1, 1, 1, 1], padding='SAME') 45 pre_activation = tf.nn.bias_add(conv, biases) # 加入偏差,biases向量与矩阵的每一行进行相加, shape不变 46 conv1 = tf.nn.relu(pre_activation, name='conv1') # 在conv1的命名空间里,用relu激活函数非线性化处理 47 48 # 第一层的池化层pool1和规范化norm1(特征缩放) 49 with tf.variable_scope('pooling1_lrn') as scope: 50 # 对conv1池化得到feature map 51 52 pool1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], 53 padding='SAME', name='pooling1') 54 # lrn():局部响应归一化, 一种防止过拟合的方法, 增强了模型的泛化能力, 55 norm1 = tf.nn.lrn(pool1, depth_radius=4, bias=1.0, alpha=0.001/9.0, 56 beta=0.75, name='norm1') 57 58 # 第二层的卷积层cov2,卷积核(weights)的大小是 3*3, 输入的channel(管道数/深度)为16, 共有16个 59 with tf.variable_scope('conv2') as scope: 60 weights = tf.get_variable('weights', 61 shape=[3, 3, 16, 16], # 这里的第三位数字16需要等于上一层的tensor维度 62 dtype=tf.float32, 63 initializer=tf.truncated_normal_initializer(stddev=0.1, dtype=tf.float32)) 64 biases = tf.get_variable('biases', 65 shape=[16], 66 dtype=tf.float32, 67 initializer=tf.constant_initializer(0.1)) 68 conv = tf.nn.conv2d(norm1, weights, strides=[1, 1, 1, 1], padding='SAME') 69 pre_activation = tf.nn.bias_add(conv, biases) 70 conv2 = tf.nn.relu(pre_activation, name='conv2') 71 72 # 第二层的池化层pool2和规范化norm2(特征缩放) 73 with tf.variable_scope('pooling2_lrn') as scope: 74 # 这里选择了先规范化再池化 75 norm2 = tf.nn.lrn(conv2, depth_radius=4, bias=1.0, alpha=0.001/9.0, 76 beta=0.75, name='norm2') 77 pool2 = tf.nn.max_pool(norm2, ksize=[1, 2, 2, 1], strides=[1, 1, 1, 1], 78 padding='SAME', name='pooling2') 79 80 # 第三层为全连接层local3 81 # 连接所有的特征, 将输出值给分类器 (将特征映射到样本标记空间), 该层映射出256个输出 82 with tf.variable_scope('local3') as scope: 83 # 将pool2张量铺平, 再把维度调整成shape(shape里的-1, 程序运行时会自动计算填充) 84 # 参考:https://blog.csdn.net/csdn0006/article/details/106238909/ 85 reshape = tf.reshape(pool2, shape=[batch_size, -1]) 86 87 dim = reshape.get_shape()[1].value # 获取reshape后的列数 88 weights = tf.get_variable('weights', 89 shape=[dim, 256], # 连接256个神经元 90 dtype=tf.float32, 91 initializer=tf.truncated_normal_initializer(stddev=0.005, dtype=tf.float32)) 92 biases = tf.get_variable('biases', 93 shape=[256], 94 dtype=tf.float32, 95 initializer=tf.constant_initializer(0.1)) 96 # 矩阵相乘再加上biases,用relu激活函数非线性化处理 97 local3 = tf.nn.relu(tf.matmul(reshape, weights) + biases, name='local3') 98 99 # 第四层为全连接层local4 100 # 连接所有的特征, 将输出值给分类器 (将特征映射到样本标记空间), 该层映射出512个输出 101 with tf.variable_scope('local4') as scope: 102 weights = tf.get_variable('weights', 103 shape=[256, 512], # 再连接512个神经元 104 dtype=tf.float32, 105 initializer=tf.truncated_normal_initializer(stddev=0.005, dtype=tf.float32)) 106 biases = tf.get_variable('biases', 107 shape=[512], 108 dtype=tf.float32, 109 initializer=tf.constant_initializer(0.1)) 110 # 矩阵相乘再加上biases,用relu激活函数非线性化处理 111 local4 = tf.nn.relu(tf.matmul(local3, weights) + biases, name='local4') 112 113 # 第五层为输出层(回归层): softmax_linear 114 # 将前面的全连接层的输出,做一个线性回归,计算出每一类的得分,在这里是2类,所以这个层输出的是两个得分。 115 with tf.variable_scope('softmax_linear') as scope: 116 weights = tf.get_variable('weights', 117 shape=[512, n_classes], 118 dtype=tf.float32, 119 initializer=tf.truncated_normal_initializer(stddev=0.005, dtype=tf.float32)) 120 biases = tf.get_variable('biases', 121 shape=[n_classes], 122 dtype=tf.float32, 123 initializer=tf.constant_initializer(0.1)) 124 125 # softmax_linear的行数=local4的行数,列数=weights的列数=bias的行数=需要分类的个数 126 # 经过softmax函数用于分类过程中,它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解 127 # 这里local4与weights矩阵相乘,再矩阵相加biases 128 softmax_linear = tf.add(tf.matmul(local4, weights), biases, name='softmax_linear') 129 130 # 这里没做归一化和交叉熵。真正的softmax函数放在下面的losses()里面和交叉熵结合在一起了,这样可以提高运算速度。 131 # 图片列表中的每张图片分别被每个分类取到的概率, 132 return softmax_linear 133 134 135 def losses(logits, labels): 136 """ 137 输入: 138 logits: 经过cnn_inference得到的神经网络输出值(图片列表中每张图片分别是猫或狗的预测概率) 139 labels: 图片对应的标签(即:真实值。用于与logits预测值进行对比得到loss) 140 返回: 141 loss: 损失值(label真实值与神经网络输出预测值之间的误差) 142 """ 143 with tf.variable_scope('loss') as scope: 144 # label与神经网络输出层的输出结果做对比,得到损失值(这做了归一化和交叉熵处理) 145 cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=labels, name='loss_per_eg') 146 loss = tf.reduce_mean(cross_entropy, name='loss') # 求得batch的平均loss(每批有16张图) 147 return loss 148 149 150 def training(loss, learning_rate): 151 """ 152 输入: 153 loss: 训练中得到的损失值 154 learning_rate:学习率 155 返回: 156 train_op: 训练的最优值。训练op,这个参数要输入sess.run中让模型去训练。 157 """ 158 with tf.name_scope('optimizer'): 159 # tf.train.AdamOptimizer(): 160 # 除了利用反向传播算法对权重和偏置项进行修正外,也在运行中不断修正学习率。 161 # 根据其损失量学习自适应,损失量大则学习率越大,进行修正的幅度也越大; 162 # 损失量小则学习率越小,进行修正的幅度也越小,但是不会超过自己所设定的学习率。 163 optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate) # 使用AdamOptimizer优化器来使loss朝着变小的方向优化 164 165 global_step = tf.Variable(0, name='global_step', trainable=False) # 全局步数赋值为0 166 167 # loss:即最小化的目标变量,一般就是训练的目标函数,均方差或者交叉熵 168 # global_step:梯度下降一次加1,一般用于记录迭代优化的次数,主要用于参数输出和保存 169 train_op = optimizer.minimize(loss, global_step=global_step) # 以最大限度地最小化loss 170 171 return train_op 172 173 174 def evaluation(logits, labels): 175 """ 176 输入: 177 logits: 经过cnn_inference得到的神经网络输出值(图片列表中每张图片分别是猫或狗的预测概率) 178 labels: 图片对应的标签(真实值,0或1) 179 返回: 180 accuracy:准确率(当前step的平均准确率。即:这些batch中多少张图片被正确分类了) 181 """ 182 with tf.variable_scope('accuracy') as scope: 183 correct = tf.nn.in_top_k(logits, labels, 1) 184 correct = tf.cast(correct, tf.float16) # 转换格式为浮点数 185 accuracy = tf.reduce_mean(correct) # 计算当前批的平均准确率 186 return accuracy
test.py(用训练好的模型对随机一张图片进行猫狗预测)代码:
1 # import tensorflow as tf 2 import tensorflow.compat.v1 as tf 3 tf.disable_v2_behavior() 4 from PIL import Image 5 import matplotlib.pyplot as plt 6 import input_data 7 import model 8 import numpy as np 9 10 11 def get_one_image(img_list): 12 """ 13 输入: 14 img_list:图片路径列表 15 返回: 16 image:从图片路径列表中随机挑选的一张图片 17 """ 18 n = len(img_list) # 获取文件夹下图片的总数 19 ind = np.random.randint(0, n) # 从 0~n 中随机选取下标 20 img_dir = img_list[ind] # 根据下标得到一张随机图片的路径 21 22 image = Image.open(img_dir) # 打开img_dir路径下的图片 23 image = image.resize([208, 208]) # 改变图片的大小,定为宽高都为208像素 24 image = np.array(image) # 转成多维数组,向量的格式 25 return image 26 27 28 def evaluate_one_image(): 29 # 修改成自己测试集的文件夹路径 30 test_dir = 'D:/WorkSpace/work_to_pycharm/cats_vs_dogs/data/test/' 31 # test_dir = '/home/user/Dataset/cats_vs_dogs/test/' 32 33 test_img = input_data.get_files(test_dir)[0] # 获取测试集的图片路径列表 34 image_array = get_one_image(test_img) # 从测试集中随机选取一张图片 35 36 # 将这个图设置为默认图,会话设置成默认对话,这样在with语句外面也能使用这个会话执行。 37 with tf.Graph().as_default(): 38 BATCH_SIZE = 1 # 这里我们要输入的是一张图(预测这张随机图) 39 N_CLASSES = 2 # 还是二分类(猫或狗) 40 41 image = tf.cast(image_array, tf.float32) # 将列表转换成tf能够识别的格式 42 image = tf.image.per_image_standardization(image) # 图片标准化处理 43 image = tf.reshape(image, [1, 208, 208, 3]) # 改变图片的形状 44 logit = model.cnn_inference(image, BATCH_SIZE, N_CLASSES) # 得到神经网络输出层的预测结果 45 logit = tf.nn.softmax(logit) # 进行归一化处理(使得预测概率之和为1) 46 47 x = tf.placeholder(tf.float32, shape=[208, 208, 3]) # x变量用于占位,输入的数据要满足这里定的shape 48 49 # 修改成自己训练好的模型路径 50 logs_train_dir = 'D:/WorkSpace/work_to_pycharm/cats_vs_dogs/log/' 51 52 saver = tf.train.Saver() 53 54 with tf.Session() as sess: 55 print("从指定路径中加载模型...") 56 ckpt = tf.train.get_checkpoint_state(logs_train_dir) # 读取路径下的checkpoint 57 # 载入模型,不需要提供模型的名字,会通过 checkpoint 文件定位到最新保存的模型 58 if ckpt and ckpt.model_checkpoint_path: # checkpoint存在且其存放的变量不为空 59 global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1] # 通过切割获取ckpt变量中的步长 60 saver.restore(sess, ckpt.model_checkpoint_path) # 当前会话中,恢复该路径下模型的所有参数(即调用训练好的模型) 61 print('模型加载成功, 训练的步数为: %s' % global_step) 62 else: 63 print('模型加载失败,checkpoint文件没找到!') 64 65 # 通过saver.restore()恢复了训练模型的参数(即:神经网络中的权重值),这样logit才能得到想要的预测结果 66 # 执行sess.run()才能运行,并返回结果数据 67 prediction = sess.run(logit, feed_dict={x: image_array}) # 输入随机抽取的那张图片数据,得到预测值 68 max_index = np.argmax(prediction) # 获取输出结果中最大概率的索引(下标) 69 if max_index == 0: 70 pre = prediction[:, 0][0] * 100 71 print('图片是猫的概率为: {:.2f}%'.format(pre)) # 下标为0,则为猫,并打印是猫的概率 72 else: 73 pre = prediction[:, 1][0] * 100 74 print('图片是狗的概率为: {:.2f}%'.format(pre)) # 下标为1,则为狗,并打印是狗的概率 75 76 plt.imshow(image_array) # 接受图片并处理 77 plt.show() # 显示图片 78 79 80 if __name__ == '__main__': 81 # 调用方法,开始测试 82 evaluate_one_image()
training.py(模型的训练及评估)代码:
1 # import tensorflow as tf 2 import tensorflow.compat.v1 as tf 3 tf.disable_v2_behavior() 4 import os 5 import numpy as np 6 import matplotlib.pyplot as plt 7 import input_data 8 import model 9 10 11 N_CLASSES = 2 # 分类数,猫和狗 12 IMG_W = 208 # resize图片宽高,太大的话训练时间久 13 IMG_H = 208 14 BATCH_SIZE = 16 # 每批次读取数据的数量 15 CAPACITY = 2000 # 队列最大容量 16 MAX_STEP = 10000 # 训练最大步数,一般5K~10k 17 learning_rate = 0.0001 # 学习率,一般小于0.0001 18 19 # train_dir = 'D:/WorkSpace/Dataset/cats_vs_dogs/data/train/' # 训练集的文件夹路径 20 # logs_train_dir = 'D:/WorkSpace/work_to_pycharm/cats_vs_dogs/log/' # 记录训练过程与保存模型的路径 21 train_dir = '/home/user/Dataset/cats_vs_dogs/train/' # 训练集的文件夹路径 22 logs_train_dir = '/home/dujunjie/PycharmProjects/cats_vs_dogs/log/' # 记录训练过程与保存模型的路径 23 24 # 获取要训练的图片和对应的图片标签, 这里返回的train_img是存放猫狗图片路径的列表,train_label是存放对train对应标签的列表(0是猫,1是狗) 25 train_img, train_label = input_data.get_files(train_dir) 26 27 # 读取队列中的数据 28 train_batch, train_label_batch = input_data.get_batch(train_img, train_label, IMG_W, IMG_H, BATCH_SIZE, CAPACITY) 29 30 # 调用model方法得到返回值, 进行变量赋值 31 train_logits = model.cnn_inference(train_batch, BATCH_SIZE, N_CLASSES) 32 train_loss = model.losses(train_logits, train_label_batch) 33 train_op = model.training(train_loss, learning_rate) 34 train_acc = model.evaluation(train_logits, train_label_batch) 35 36 summary_op = tf.summary.merge_all() # 将所有summary全部保存到磁盘,以便tensorboard显示 37 38 accuracy_list = [] # 记录准确率(每50步存一次) 39 loss_list = [] # 记录损失值(每50步存一次) 40 step_list = [] # 记录训练步数(每50步存一次) 41 42 43 with tf.Session() as sess: 44 sess.run(tf.global_variables_initializer()) # 变量初始化,如果存在变量则是必不可少的操作 45 46 train_writer = tf.summary.FileWriter(logs_train_dir, sess.graph) # 用于向logs_train_dir写入summary(训练)的目标文件 47 saver = tf.train.Saver() # 用于存储训练好的模型 48 49 # 队列监控(训练的batch数据用到了队列) 50 coord = tf.train.Coordinator() # 创建线程协调器 51 threads = tf.train.start_queue_runners(sess=sess, coord=coord) 52 53 try: 54 # 执行MAX_STEP步的训练,一步一个batch 55 for step in np.arange(MAX_STEP): 56 if coord.should_stop(): # 队列中的所有数据已被读出,无数据可读时终止训练 57 break 58 59 _op, tra_loss, tra_acc = sess.run([train_op, train_loss, train_acc]) # 在会话中才能读取tensorflow的变量值 60 61 # 每隔50步打印一次当前的loss以及acc,同时记录log,写入writer 62 if step % 50 == 0: 63 print('Step %d, train loss = %.2f, train accuracy = %.2f%%' % (step, tra_loss, tra_acc * 100.0)) 64 summary_train = sess.run(summary_op) # 调用sess.run(),生成的训练数据 65 train_writer.add_summary(summary_train, step) # 将训练过程及训练步数保存 66 67 # 每隔100步画图,记录训练的准确率和损失值的结点 68 if step % 100 == 0: 69 accuracy_list.append(tra_acc) 70 loss_list.append(tra_loss) 71 step_list.append(step) 72 73 # 每隔5000步,保存一次训练好的模型(即:训练好的模型的参数保存下来) 74 if step % 5000 == 0 or (step + 1) == MAX_STEP: 75 # ckpt文件是一个二进制文件,它把变量名映射到对应的tensor值 76 checkpoint_path = os.path.join(logs_train_dir, 'model.ckpt') 77 saver.save(sess, checkpoint_path, global_step=step) 78 79 plt.figure() # 建立可视化图像框 80 plt.plot(step_list, accuracy_list, color='b', label='cnn_accuracy') # 蓝线为准确率 81 plt.plot(step_list, loss_list, color='r', label='cnn_loss', linestyle='dashed') # 红虚线为损失值 82 plt.xlabel("Step") # x轴取名 83 plt.ylabel("Accuracy/Loss") # y轴取名 84 plt.legend() # 给图加上图例 85 plt.show() # 显示图片 86 87 except tf.errors.OutOfRangeError: 88 print('Done training -- epoch limit reached') 89 finally: 90 coord.request_stop() # 停止所有线程 91 92 coord.join(threads) # 等待所有线程结束 93 sess.close() # 关闭会话
(四)、总结
最终的模型和结果在这个猫狗分类问题上是符合期望的。在项目实施过程中有一点令我印象深刻,那就是任何机器学习问题,都免不了数据预处理、模型构建、模型训练、测试与验证等步骤;但预处理与模型调参可能会占用大部分时间和精力,数据组织方式也会对模型有较大影响。
通过该案例的运行和分析,学会了一些数据处理的基本操作,包括对文件的处理。对Python和TensorFlow和CNN的使用更加熟练。

