

《Graph Attention Networks》阅读笔记
Graph Attention Networks
来源: ICLR 2018
作者:Petar Velickovic, Guillem Cucurull, Arantxa Casanova, Yoshua Bengio
Abstract
针对图结构数据,本文提出了一种GAT(graph attention networks)网络。该网络使用masked self-attention层解决了之前基于图卷积(或其近似)的模型所存在的问题。在GAT中,图中的每个节点可以根据邻节点的特征,为其分配不同的权值。GAT的另一个优点在于,无需使用预先构建好的图。因此,GAT可以解决一些基于谱的图神经网络中所具有的问题。实验证明,GAT模型可以有效地适用于(基于图的)归纳学习问题与转导学习问题。
创新点:
- 引入masked self-attentional layers 来改进前面图卷积graph convolution的缺点
- 对不同的相邻节点分配相应的权重,既不需要矩阵运算,也不需要事先知道图结构
attention 引入目的
- 为每个节点分配不同权重
- 关注那些作用比较大的节点,而忽视一些作用较小的节点
- 在处理局部信息的时候同时能够关注整体的信息,不是用来给参与计算的各个节点进行加权的,而是表示一个全局的信息并参与计算
框架特点
- attention 计算机制高效,为每个节点和其每个邻近节点计算attention 可以并行进行
- 能够按照规则指定neighbor 不同的权重,不受邻居数目的影响
- 可直接应用到归纳推理问题中
Definition
- 归纳学习(Inductive Learning):先从训练样本中学习到一定的模式,然后利用其对测试样本进行预测(即首先从特殊到一般,然后再从一般到特殊),这类模型如常见的贝叶斯模型。
- 转导学习(Transductive Learning):先观察特定的训练样本,然后对特定的测试样本做出预测(从特殊到特殊),这类模型如k近邻、SVM等。
Related Work
谱方法 spectral approaches
GCN:
在每个节点周围对卷积核做一阶邻接近似。但是此方法也有一些缺点:
- 必须基于相应的图结构才能学到拉普拉斯矩阵L
- 对于一个图结构训练好的模型,不能运用于另一个图结构(所以此文称自己为半监督的方法)
非谱方法 non-spectral approaches
直接在图上(而不是在图的谱上)定义卷积。
MoNet(mixture model CNN),该方法可以有效地将CNN结构引入到图上。
GraphSAGE模型,该模型使用一种归纳的方法来计算节点表示。具体来说,该模型首先从每个节点的邻节点中抽取出固定数量的节点,然后再使用特定的方式来融合这些邻节点的信息(如直接对这些节点的特征向量求平均,或者将其输入到一个RNN中)
注意力机制 self-attention
优点:可以处理任意大小输入的问题,并且关注最具有影响能力的输入。
注意力机制再RNN与CNN之中,都取得了不错的效果,并且可以达到state of the art的性能。
Model
方法特性
针对每一个节点运算相应的隐藏信息,在运算其相邻节点的时候引入注意力机制:
- 高效:针对相邻的节点对,并且可以并行运算
- 灵活:针对有不同度(degree)的节点,可以运用任意大小的weight与之对应。(这里我们解释一个概念,节点的度degree:表示的是与这个节点相连接的节点的个数)
- 可移植:可以将模型应用于从未见过的图结构数据,不需要与训练集相同。
图注意层 Graph Attention layer
输入 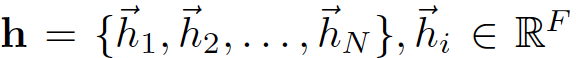 N为节点的个数,F为feature的个数,这表示输入为N个节点的每个节点的F个feature
N为节点的个数,F为feature的个数,这表示输入为N个节点的每个节点的F个feature
输出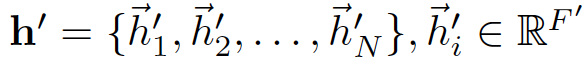 表示对这N个节点的 F' 个输出,输出位N个节点的每个节点的F'个feature
表示对这N个节点的 F' 个输出,输出位N个节点的每个节点的F'个feature
针对的是N个节点,按照其输入的feature预测输出的feature。
特征提取与注意力机制:
为了得到相应的输入与输出的转换,我们需要根据输入的feature至少一次线性变换得到输出的feature,所以我们需要对所有节点训练一个权值矩阵: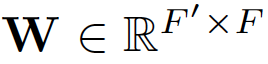 ,这个权值矩阵就是输入与输出的F个feature与输出的F'个feature之间的关系。
,这个权值矩阵就是输入与输出的F个feature与输出的F'个feature之间的关系。
We then perform self-attention on the nodes—a shared attentional mechanism,
针对每个节点实行self-attention的注意力机制,机制为 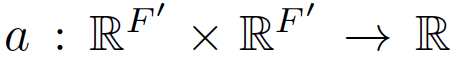
注意力互相关系数为attention coefficients: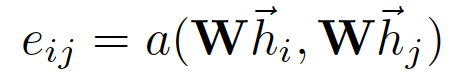
- 这个公式表示的节点 j 对于节点 i 的重要性,而不去考虑图结构性的信息
- 向量h就是 feature向量
- 下标i,j表示第i个节点和第j个节点
通过masked attention将这个注意力机制引入图结构之中 ( masked attention的含义 :只计算节点 i 的相邻的节点 j )
节点 j 为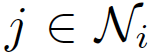 ,其中 \(N_i\) 为 节点 i 的所有相邻节点。为了使得互相关系数更容易计算和便于比较,引入了\(softmax\) 对所有的 i 的相邻节点 j 进行正则化:
,其中 \(N_i\) 为 节点 i 的所有相邻节点。为了使得互相关系数更容易计算和便于比较,引入了\(softmax\) 对所有的 i 的相邻节点 j 进行正则化: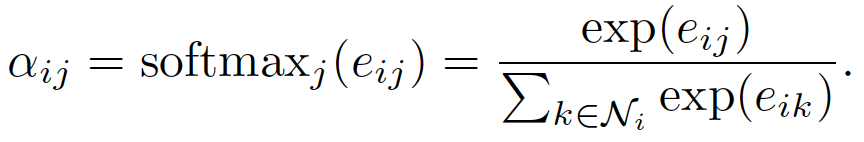
实验之中,注意力机制a是一个单层的前馈神经网络,通过权值向量来确定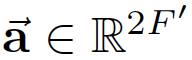 ,并且加入了 LeakyRelu的非线性激活,这里小于零斜率为0.2。
,并且加入了 LeakyRelu的非线性激活,这里小于零斜率为0.2。
注意力机制如下:
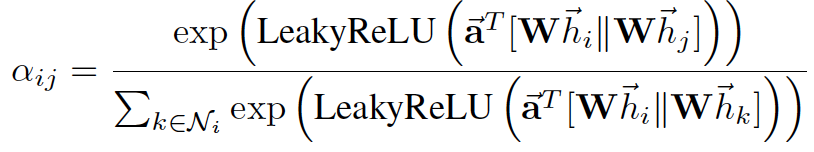 ,
,
注意力互相关系数

在模型中应用相互注意机制\(a(Wh_i,Wh_j)\),通过权重向量 a 参数化,应用 LeakyReLU 激活
- 模型权重为
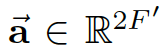
- 转置表示为T
- concatenation 用 || 表示
- 公式含义就是权值矩阵与F'个特征相乘,然后节点相乘后并列在一起,与权重相乘,LRelu激活后指数操作得到softmax的分子
Output features
通过上面,运算得到了正则化后的不同节点之间的注意力互相关系数normalized attention coefficients,可以用来预测每个节点的output feature: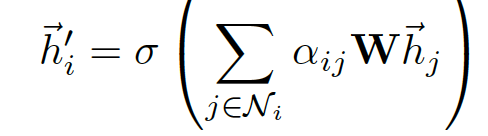
- 我们再回顾一下含义,W为与feature相乘的权值矩阵
- \(a_{ij}\)为前面算得的注意力互相关系数
- sigma为非线性激活
- 遍历的 j 表示所有与 i 相邻的节点
- 这个公式表示就是,该节点的输出feature与与之相邻的所有节点有关,是他们的线性和的非线性激活
- 这个线性和的线性系数是前面求得的注意力互相关系数
multi-head attention
output feature加入计算multi-head的运算公式:
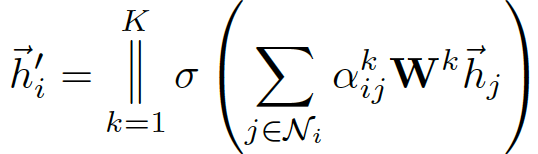
- concat 操作为 \(||\)
- 第k个注意力机制为
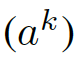
- 共k注意力机制需要考虑
- 输入特征的线性变换表示为
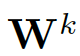
- 最终的输出为h' 共由KF' 个特征影响
例如,K=3时候,结构如下

例如此图,节点1在邻域中具有多端注意机制,不同的箭头样式表示独立的注意力计算,通过连接或平均每个head获取 h1
对于最终的输出,concat操作可能不那么敏感了,所以我们直接用K平均来取代concate操作,得到最终的公式:
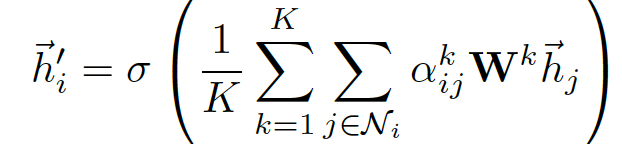
对比
更好的效率
GAT运算得到F'个特征需要的算法复杂度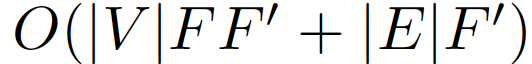
- F':为输出特征的个数
- F:为输入特征的个数
- |V| :节点的个数
- |E|:节点之间连接的个数
并且引入K之后,对于每个head的运算都独立并且可以并行
更好鲁棒性
与GCN的不同在于,GAT针对不同的相邻节点的重要性进行预测,模型具有更好的性能并且对于扰动更加鲁棒。
不需要整张Graph
引入注意力机制之后,只与相邻节点有关,即共享边的节点有关,无需得到整张graph的信息。
- 即使丢失了i,j之间的链接,则不计算
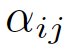 即可
即可 - 可以将模型运用于inductive learning,更好解释性,即使graph不完全,也可以运行训练过程
与GraphSAGE相比
最新的归纳学习方法(GraphSAGE)通过从每个节点的邻居中抽取固定数量的节点,从而保证其计算的一致性。这意味着,在执行推断时,我们无法访问所有的邻居。然而,本文所提出的模型是建立在所有邻节点上的,而且无需假设任何节点顺序。
Experiments
数据集

半监督学习transductive learning
-
两层 GAT
-
在Cora 数据集上优化网络结构的超参数,应用到Citeseer 数据集
-
第一层 8 head, F`=8 ELU 作为非线性函数
-
第二层为分类层,一个 attention head 特征数C,后跟 softmax 函数
-
- 为了应对小训练集,正则化(L2)
-
两层都采用 0.6 的dropout
-
- 相当于计算每个node位置的卷积时都是随机的选取了一部分近邻节点参与卷积
在transductive的任务中,比较平均分类准确度。为了公平的评估注意力机制的优势,作者进一步评估了一个计算64个隐含特征的GCN模型,并同时尝试了ReLU和ELU激活。由表1,GAT方法在数据集Cora、Citeseer的分类准确度比GCNs高1.5%和1.6%。这说明,将不同的权重分配给邻域内不同的邻居能够有效提高模型表达能力。
归纳学习inductive learning
- 三层GAT 模型
- 前两层 K=4, F1=256 ELU作为非线性函数
- 最后一层用来分类 K=6, F`=121 后跟logistics sigmoid 激活函数
- 该任务中,训练集足够大不需要使用 正则化 和 dropout
对于Inductive任务,取两个模型从未见过的graph测试,比较节点的F1-score。在PPI数据集上,GAT模型的表现比GraphSAGE的最好成绩还要高20.5%,GAT模型具有良好的inductive setting运用潜力。
Conclusion
引用了注意力机制,并且模型性能达到state of the art.
运算相邻节点,更加具有鲁棒性,不需要整张图。
更具有可解释性,公式也更直观。
