数据库必知必会:锁和事务
写在前面
这篇文章是在网络上看到其他作者的优秀博文,自己消化理解之后所做的记录。文章基于 MySQL 中的 InnoDB 存储引擎。
原博文地址:点我
锁
锁知识概览
我们先看一张锁的概览图,方便后续的讲述:
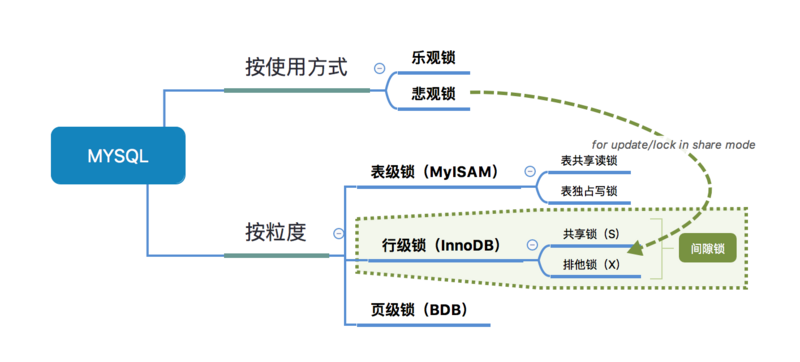
我们的程序在一般情况下还是可以跑得好好的。因为这些锁数据库隐式帮我们加了;只在某些特定的场景下,才需要程序员手动加锁。
-
在执行「查询语句」 SELECT 前,会自动给涉及的所有表加「表级锁」中的读锁;在执行「更新操作」 UPDATE、DELETE、INSERT 前,会自动给涉及的表加「表级锁」中的写锁
-
对于InnoDB,且使用了索引的「更新操作」 UPDATE、DELETE、INSERT 语句;这时 InnoDB 会将「表锁」转换成「行锁」,也就是会自动给涉及数据集加「行级锁」中的排他锁(X)
注意:InnoDB 只有通过「索引」检索数据才使用「行级锁」,否则,InnoDB将使用表锁;也就是说,InnoDB 的行锁基于索引。
一种特殊情况
如果我们对表中的某列加的是「普通索引」,那也就意味着:索引列属性可能重复。
对于普通索引,当重复率高时,MySQL 不会把这个普通索引当做索引,即会造成一个没有索引的SQL,从而形成表锁。
锁的分类
从上图中,以锁的粒度出发,我们可以看到锁分为「表级锁」和「行级锁」
-
『表锁』:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突概率高,并发度最低
-
『行锁』:开销大,加锁慢;会出现死锁;锁定粒度小,发生锁冲突的概率低,并发度高
同时,不同的存储引擎支持的锁粒度是不一样的:
-
MyISAM 只支持表锁
-
InnoDB 行锁和表锁都支持
下面我们分别看看「表锁」和「行锁」。
表锁
对于数据库,存在两种表锁:「表读锁」Table Read Lock和「表写锁」Table Write Lock
对于两种锁,他们存在如下阻塞情况:
-
读读不阻塞:当前用户在读数据,其他的用户也能够正常读数据,不会加锁
-
读写阻塞:当前用户在读数据,其他的用户不能修改当前用户正在读的数据,会加锁
-
写写阻塞:当前用户在修改数据,其他的用户不能修改当前用户正在修改的数据,会加锁
它们之间的兼容情况如下:

总结一下,对于表级锁:
-
读锁和写锁互斥
-
读写操作串行
行锁
前面提到,行锁是「InnoDB」独有的锁,我们使用 MySQL 一般也是使用「InnoDB」存储引擎的。
为什么一般使用 InnoDB
InnoDB 和 MyISAM 有两个本质的区别:
-
InnoDB 支持行锁
-
InnoDB 支持事务
「行锁」和「事务」允许我们以更小的粒度进行并发控制,正确的使用可以提高数据库的并发性。
InnoDB 支持下面两种「行锁」:
-
共享锁
也称为「读锁」或者「S锁」,是共享的,多个事务可以同时读取同一个资源,但不允许其他事务修改。
也就是说,对于同一行数据,可以同时存在多个读锁(所以可以同时读取);但写锁和读锁是互斥的,两者不能同时存在(所以读的时候不允许其他事务修改)。
-
排它锁
也称为「写锁」或者「X锁」,是排他的,写锁会阻塞其他的写锁和读锁,因此其他事务不能对持有写锁的数据进行读取或者写入。
另外,为了允许行锁和表锁共存,实现多粒度锁机制,InnoDB 还有两种内部使用的意向锁(Intention Locks),这两种意向锁都是表锁:
-
意向共享锁
IS:表示事务打算给数据行加行共享锁;事务在给一个数据行加共享锁前必须先取得该表的IS锁。 -
意向排他锁
IX:表示事务打算给数据行加行排他锁;事务在给一个数据行加排他锁前必须先取得该表的IX锁
对于这两种意向锁,MySQL 也会自动帮我们获取,不需要手动获取。
事务
『事务』,我们可以将它理解为一个不可分割的业务操作,例如银行的转账操作。我们希望提高 MySQL 的并发处理能力,本质上就是希望能够提高「事务」的并发处理能力。
本质上,事务的隔离级别就是通过锁的机制来实现,只不过隐藏了加锁细节。
事务的特性
为了保证事务能够正确的处理,我们规定事务需要有下面四种特性(ACID):
-
原子性
Atomic:事务的各步操作是不可分的,保证一系列的操作要么都完成,要么都不完成; -
一致性
Consistency:事务完成前后,数据库所处的状态和业务规则必须是一致的;比如a、b账户相互转账之后,两者的总余额不变; -
隔离性
Isolation:操作中的事务相互隔离;这表明事务必须是独立的,不应以任何方式依赖或影响其他事务; -
持久性
Durability:表示事务对数据处理结束后,对数据更改必须持久化;不管是事务成功还是回滚,事务日志都能够保持事务的永久性。
事务的隔离级别
隔离级别描述了事务被隔离的程度,隔离级别越高,受其他事物干扰越少,并发性能越差;相对的,高的隔离级别能够保证更高的安全性。
事务一般有四种隔离级别,隔离程度从低到高,如下:
-
『Read Uncommitted』:读未提交;会出现脏读,不可重复读,幻读
-
『Read Committed』:读已提交;会出现不可重复读,幻读
-
『Repeatable Read』:重复读;会出现幻读(MySQL 中配合间隙锁
GPA避免幻读) -
『Serializable』:串行;不会出现以上问题,但此时事务只能一个接一个地顺序执行
观察可以发现,较高隔离级别的事务存在的问题也会出现在低隔离级别的事务上,下面我们从低到高地分析不同隔离级别存在的问题,再看看较高级别的情况下是如何解决这些问题的。
默认情况下,『MySQL』的默认隔离级别为「Repeatable Reable」;『Oracle』的默认隔离级别为「Read Committed」。
「Read Uncommitted」与「脏读」
脏读:指一个事务读取到另外一个事务未提交的数据
例如:A 打算向 B 转账,执行转账的事务,但是还没有提交,而同时 B 读取数据,就发现自己账户的余额变多了,B 便通知 A 说「我已经收到钱了」;假设这时 A 执行rollback操作,回滚事务,那 B 再次查看账户余额,会发现钱并没有变多。
我们将 B 在中间读取到自己余额变多的数据称为脏数据,也就是这个数据只是一个中间状态的数据,最终可能会转换成另一种情况,并不干净有效;这种可能读取到「脏」数据的情况我们便称为脏读。
为什么出现「脏读」
B 在读取数据的时候,没有对数据加「共享锁」,导致可以读出被「排它锁」锁住的数据。
我们看看上面的脏读过程:
-
B 查看自己余额,得知当前余额为 x。
-
A 执行转账,也就是修改 A 和 B 的账户余额(加了写锁,但是并没有 commit,也就是数据仍锁着),假设转了 50 给 B。
-
B 查看自己余额,可以发现收到来自 A 的转账(没有加读锁,所以会读取到 A 中进行的改动),现在读取到的余额为 x + 50。
-
A 回滚转账事务,这时 A 和 B 账户余额恢复到转账之前
-
B 查看自己余额,发现自己的余额又变回去了(A 回滚了转账操作,B 的余额又变成 x 了)。
可以看到,在这种情况下,我们会读取到其他事务未提交的数据,也就是「读未提交」Read Uncommitted。
在其他隔离级别的情况下,我们可以避免脏读的发生。但在了解如何避免之前,我们需要先了解数据库的「MVCC」。
MVCC(Multi-Version Concurrency Control):多版本并发控制
前面提到「脏读」的问题,本质上,就是在并发读写数据库时,读操作可能会读取到不一致的数据。
为了避免这种情况,需要实现数据库的并发访问控制,最简单的方式就是「加锁访问」。由于,加锁会将读写操作串行化,所以不会出现不一致的状态。但是,读操作会被写操作阻塞,大幅降低读性能。
在 Java concurrent 包中,有「copyonwrite」系列的类,专门用于优化读远大于写的情况。而其优化的手段就是,在进行写操作时,将数据copy一份,不会影响原有数据,然后进行修改,修改完成后原子替换掉旧的数据,而读操作只会读取原有数据。通过这种方式实现写操作不会阻塞读操作,从而优化读效率。而写操作之间是要互斥的,并且每次写操作都会有一次copy,所以只适合读大于写的情况。
什么是 MVCC
「MVCC」的原理与「copyonwrite」类似:
在MVCC协议下,为每个「读操作」会生成一个一致性的快照snapshot,并用这个快照来提供一定级别(语句级或事务级)的一致性读取。从用户的角度来看,好像是数据库可以提供同一数据的多个版本。可以实现非阻塞的读。可以将 MVCC 认为升级版的行级锁。
MVCC允许数据具有多个版本,这个版本可以依据时间戳或者是全局递增的事务ID,在同一个时间点,不同的事务看到的数据是不同的。
联系前文的「copyonwrite」和「MVCC」,我们可以如何解决「脏读」问题呢?
同样地,我们可以在修改数据时创建一份数据的拷贝,再修改完成(也就是事务提交)之后,再原子替换旧数据和它版本号;这样一来,在事务提交之前,读取到的数据始终是不变的(因为修改的是拷贝的数据),而在事务提交之后,我们又可以读取到新的数据(修改完成后会更新版本号,我们可以每次读取最新版本号的数据)。这也是「Read Committed」解决「脏读」的方法。
「Read Committed」和「不可重复读」
前面已经提到「Read Committed」如何避免脏读:
事务只有在commit只有,才会把数据写入并更新版本号;读操作总是读取最新版本号的数据。
那么,「Read Committed」的并发事务访问过程也很清楚了,我们按照转账的例子再走一遍:
-
B 查看自己余额,得知当前余额为 x。
-
A 执行转账,也就是修改 A 和 B 的账户余额(加了写锁,但是并没有 commit,也就是数据仍锁着),假设转了 50 给 B。
-
B 查看自己余额,读取到的余额不变(因为 B 事务还没有提交),为 x。
-
A 提交转账事务,更新 B 余额的版本号。
-
B 查看自己余额,可以发现自己的余额为 x + 50(最新版本号的余额为 x + 50)。
「Read Committed」虽然解决了「脏读」的问题,但是它仍存在相应的问题。
不可重复读
「不可重复读」,顾名思义,也就是不能重复读取到一致的数据。在一个事务 B 中,不管当前事务 B 有没有结束,其他事务 A 都能够修改 B 涉及的数据,那 B 之前查询得到的数据就没有意义了。
在前面转账例子中,B 在一个查询事务中对自己的余额进行两次查询,却因为其他事务的修改导致查询结果不一致,也就是 B 事务出现了「不可重复读」的问题。
为什么会出现「不可重复读」
数据库对当前读取数据的语句获得了读取锁,但读完之后就解锁,不管当前事务有没有结束,这样就容许其他事务修改本事务正在读取的数据,导致不可重复读。
因此,我们称「Read Committed」为语句级别的快照(只对读取数据的语句加读锁)。在数据库更高一层的隔离级别「Repeatable Read」中能够避免这种问题。
「Repeatable Read」和「幻读」
上面说到,我们希望在同一个事务中读取的数据不被其他事务的修改影响,再联想之前的快照snapshot;我们只需要在事务开启的时候保存一个版本号快照,在这个事务中每次只读取对应版本的数据就可以了。
实际上,「Repeatable Read」就是对涉及到的数据行加锁,并且这个锁直到事务结束才释放,这样便能够能保证正在被本事务操作的数据不被其他事务修改,也就不会出现「不可重复读」的情况了。
也因为它对数据加的锁持有时间是以事务为级别的,所以「Repeated Read」被称为事务级别的快照。
这里摘抄博文中关于 InnoDB 如何实现 MVCC 的节选:


幻读
最后,我们要知道,「Repeatable Read」对涉及到的数据行加锁,这也意味着,在事务 A 操纵表中部分数据的情况下,其他事务仍可以在提交新的数据到这个表,这会导致事务 A 两次统计的结果不一致,就像产生了幻觉一样,这就是「幻读」。
下面我们用两个个例子来说明「幻读」:
一、事务在插入已经检查过不存在的记录时,惊奇的发现这些数据已经存在了,之前的检测获取到的数据如同幻觉一般。
假设两个事务 A 和 B,开启之后,它们都查询 user 表中是否存在id = 1的用户(id 为 user 表主键):
-- A 和 B同时执行
SELECT * FROM user WHERE id = 1;
这里假设 user 表为空,因此这里 A 和 B 都查询不到这个用户的存在,所以 A 和 B 都插入一个id = 1的用户数据到 user 表中,我们假设 A 事务先执行,B 事务后执行:
-- A 先执行,B 后执行
INSERT INTO user(id, name) VALUE(1, '张三');
那么在顺序执行的时候,很明显,A 能够成功插入,但 B 插入的时候会产生主键冲突,我们宏观来看是可以理解的,因为 A 已经插入了id = 1的数据;但对于 B 来说,它之前的SELECT语句明明表示不存在,但现在插入的时候却提示已经存在id = 1的数据了,仿佛之前的查询结果是幻觉一样,这就称为「幻读」。
二、同样的条件下,第1次和第2次读出来的表记录数不一样。
假设当前工资为 1000 的有 10 人,事务 1 读取当前工资为 1000 的员工数目,得出结果10条:
-- 结果为 10
SELECT COUNT(*) FROM employee WHERE salary = 1000;
这时事务 2 向员工表中插入一个工资为 1000 的员工信息,并提交:
INSERT INTO employee(name, salary) VALUE('newEmployee', 1000);
COMMIT;
这时事务 2 再次读取员工数目,会得出结果为 11:
-- 结果为 11
SELECT COUNT(*) FROM employee WHERE salary = 1000;
这也就是出现了「幻读」。
怎么解决「幻读」
最简单的解决方式便是让事务「串行」执行,每次同时只能执行一个事务,但这种情况下,我们就无法并行操作事务了。而在「Repeatable Read」的情况下,我们可以给读取的数据加上间隙锁GAP来处理幻读的情况。
间隙锁 GAP
当我们用范围条件检索数据而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合范围条件的已有数据记录的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做「间隙(GAP)」。InnoDB也会对这个间隙加锁,这种锁机制就是所谓的「间隙锁」。
例子:假如emp表中只有101条记录,其empid的值分别是1,2,...,100,101:
SELECT * FROM emp WHERE empid > 100 for UPDATE;
上面是一个范围查询,InnoDB不仅会对符合条件的empid值为101的记录加锁,也会对empid大于101(这些记录并不存在)的「间隙」加锁。
InnoDB使用间隙锁的目的有两个:
-
为了防止幻读(上面也说了,「Repeatable Read」隔离级别下再通过GAP锁即可避免了幻读)
-
满足恢复和复制的需要:
MySQL的恢复机制要求:在一个事务未提交前,其他并发事务不能插入满足其锁定条件的任何记录,也就是不允许出现幻读
值得注意的是:间隙锁只会在「Repeatable Read」隔离级别下使用
乐观锁和悲观锁
我们可以发现,之前的数据库隔离级别,都是为了解决读写冲突问题,我们在默认的「Repeatable Read」的情况下考虑一个问题:
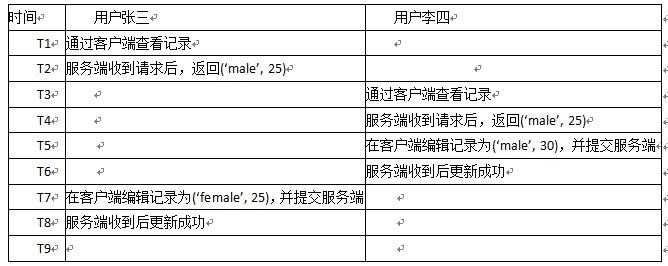
上面我们假设,T1T2时间,张三完成一个查询事务;T3T6,李四完成一个更新事务;在后序时间段,张三基于上一次的查询进行一个更新事务。在这种情况下,李四的更新就被张三的更新覆盖了,也就是发生了更新丢失。
我们可以通过以下方法解决这个问题:
-
使用
Serializable隔离级别,这时事务是串行执行的 -
乐观锁
-
悲观锁
乐观锁
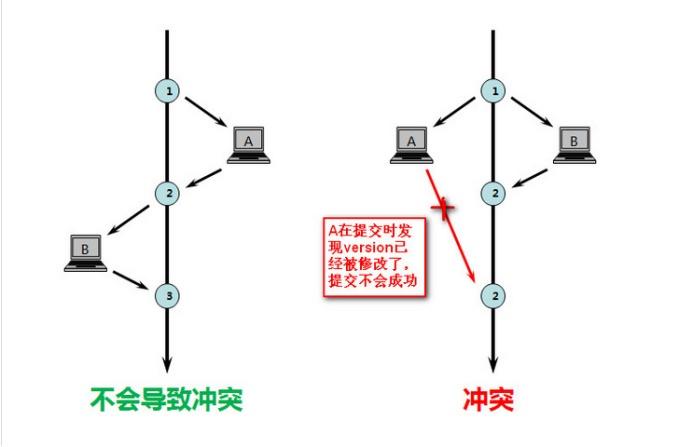
「乐观锁」是一种思想,不是数据库层面上的锁,是需要自己手动去加的锁。具体实现是,表中有一个版本字段,第一次读的时候,获取到这个字段。处理完业务逻辑开始更新的时候,需要再次查看该字段的值是否和第一次的一样;如果一样,则更新,并同步更新版本字段;反之拒绝。
之所以叫乐观,因为这个模式没有从数据库加锁,等到更新的时候再判断是否可以更新。
具体过程是这样的:
张三select * from table --->会查询出记录出来,同时会有一个version字段

李四select * from table --->会查询出记录出来,同时会有一个version字段
李四对这条记录做修改: update A set Name=lisi,version=version+1 where ID=#{id} and version=#{version},判断之前查询到的version与现在的数据的version进行比较,同时会更新version字段
此时数据库记录如下:

张三也对这条记录修改: update A set Name=lisi,version=version+1 where ID=#{id} and version=#{version},但失败了!因为当前数据库中的版本跟查询出来的版本不一致!
悲观锁
「悲观锁」是数据库层面加锁,所有更新操作都会阻塞去等待锁。
我们在语句后加FOR UPDATE,即可使用悲观锁:
SELECT * FROM xxx FOR UPDATE
FOR UPDATE等于对选中的行加了「排它锁」,加了写锁之后,其他事务就不能对它进行访问和修改了,这也就保证了不会出现更新丢失的情况。
如何选择乐观锁或悲观锁
两种锁各有优缺点,不可认为一种好于另一种,像「乐观锁」适用于写比较少的情况下,即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果经常产生冲突,上层应用会不断的进行retry,这样反倒是降低了性能,所以这种情况下用悲观锁就比较合适。
死锁
并发的问题就少不了死锁,在MySQL中同样会存在死锁的问题。
但一般来说MySQL通过回滚帮我们解决了不少死锁的问题了,但死锁是无法完全避免的,可以通过以下的经验参考,来尽可能少遇到死锁:
-
以固定的顺序访问表和行。比如对两个job批量更新的情形,简单方法是对id列表先排序,后执行,这样就避免了交叉等待锁的情形;将两个事务的sql顺序调整为一致,也能避免死锁。
-
大事务拆小。大事务更倾向于死锁,如果业务允许,将大事务拆小。
-
在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁概率。
-
降低隔离级别。如果业务允许,将隔离级别调低也是较好的选择,比如将隔离级别从RR调整为RC,可以避免掉很多因为gap锁造成的死锁。
-
为表添加合理的索引。可以看到如果不走索引将会为表的每一行记录添加上锁,死锁的概率大大增大。
总结
上面说了一大堆关于MySQL数据库锁的东西,现在来简单总结一下。
表锁其实我们程序员是很少关心它的:
-
在MyISAM存储引擎中,当执行SQL语句的时候是自动加的。
-
在InnoDB存储引擎中,如果没有使用索引,表锁也是自动加的。
现在我们大多数使用MySQL都是使用InnoDB,InnoDB支持行锁:
-
共享锁--读锁--S锁
-
排它锁--写锁--X锁
在默认的情况下,select是不加任何行锁的。我们可以通过以下语句显示给记录集加共享锁或排他锁。
-
共享锁(S):
SELECT * FROM table_name WHERE ... LOCK IN SHARE MODE。 -
排他锁(X):
SELECT * FROM table_name WHERE ... FOR UPDATE。
InnoDB基于行锁还实现了MVCC多版本并发控制,MVCC在隔离级别下的Read committed和Repeatable read下工作。MVCC能够实现读写不阻塞!
InnoDB实现的Repeatable read隔离级别配合GAP间隙锁已经避免了幻读。
对于悲观锁和乐观锁,我们也归纳如下:
-
乐观锁其实是一种思想,正如其名:认为不会锁定的情况下去更新数据,如果发现不对劲,才不更新(回滚)。在数据库中往往添加一个version字段来实现。
-
悲观锁用的就是数据库的行锁,认为数据库会发生并发冲突,直接上来就把数据锁住,其他事务不能修改,直至提交了当前事务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号