MySql入门
一、MySQL 数据库
1.1 数据库的基本概念
-
数据库的英文单词
DateBase 简称:DB
-
什么是数据库?
- 用于存储和管理数据的仓库
-
数据库的特点
- 持久化存储数据的。其实数据库就是一个文件系统
- 方便存储和管理数据
- 使用了统一的方式操作数据库 -- SQL
1.2 MySQL 数据库
1.2.1 MySQL 目录结构
-
MySQL 安装目录
- 配置文件 my.ini
-
MySQL 数据目录
- 数据库:文件夹
- 表:文件
- 数据:文件中的数据
1.2.2 启动MySQL 服务
-
图形界面方式
-
命令行方式:
管理员身份运行:net start/stop mysql
1.2.3 MySQL用户登录/登出
-
MySQL 登录
- mysql (-h host地址) -u 用户名 -p
- mysql (--host=host地址) --user=用户名 --password=
-
MySQL 登出
- quit
- exit
1.2.4 备份/还原MySQL数据库
-
备份
mysqldump -u 用户名 -p 密码 数据库名 > 保存文件(需写明路径)
-
还原
- 登录数据库
- 创建数据库
- 使用数据库
- 执行MySQL备份文件
二、SQL
每一种数据库存在不一样的地方,称为“方言”。
2.1 SQL概念
- 什么是SQL?
Structed Query Language:结构化查询语言(其实就是定义了操作所有关系型数据库的规则)
-
SQL 通用语法
- SQL 语句可以分成单行或是多行书写,以分号
;结尾。 - 可以使用空格或缩进来增强语句的可读性。
- MySQL 数据库语句不区分大小写,但关键字建议大写。
- 注释方式
- 单行注释:
-- 注释内容或是#注释内容(后者为MySQL 特有) - 多行注释:
/* 注释 */
- 单行注释:
- SQL 语句可以分成单行或是多行书写,以分号
-
SQL 分类
-
DDL(Date Definition Language)数据定义语言
用于定义数据库对象:数据库、表、列等;
关键字:create, drop, alter等
-
DQL(Data Query language)数据查询语言
用于查询数据库中表的记录(数据);
关键字:select, where等
-
DML(Date Manipulation Language)数据操作语言
用于对数据库中表的数据进行增删改;
关键字:insert, delete, update等
-
DCL(Data Control Language)数据控制语言(了解)
用于定义数据库的访问权限和安全级别,及创建用户;
关键字:GRANT, REVOKE等
-
2.2 DDL-数据库定义语言:操作数据库、表
对数据库中各种对象进行结构上的操作(CRUD等)。
DDL 的关键字如下:
| 操作 | 创建 | 查询 | 更新 | 删除 |
|---|---|---|---|---|
| 关键字 | CREATE | SHOW | ALTER | DROP |
2.2.1. 操作数据库:CRUD
-
C(Create):创建
-
创建数据库
CREATE DATABASE 数据库名 -
创建数据库(仅在目标不存在时才创建)
CREATE DATABASE IF NOT EXISTS 数据库名; -
创建数据库且指定字符集
CREATE DATABASE 数据库名 CHARACTER SET 字符集名; -
e.g.创建字符集为gbk的数据库db1,若已存在则跳过
CREATE DATABASE IF NOT EXISTS db1 CHARACTER SET gbk;
-
-
R(Retrieve):查询
-
查询所有数据库名称
SHOW DATABASES; -
查询某个数据库的字符集
SHOW CREATE DATABASE 数据库名;
-
-
U(Update):修改
-
修改数据库字符集
ALTER DATABASE 数据库名 CHARACTER SET 字符集名;
-
-
D(Delete):删除
-
删除数据库
DROP DATABASE 数据库名; -
删除数据库(仅在目标存在时才删除)
DROP DATABASE IF EXISTS 数据库名;
-
-
使用数据库
-
查询当前正在使用的数据库名称
SELECT DATABASE(); -
使用指定数据库
USE 数据库名;
-
2.2.2. 操作表
-
C(Create):创建
-
语法:
CREATE TABLE 表名( 列名1 数据类型1, 列名2 数据类型2, ... 列名n 数据类型n ); -- 注意,最后一列不加逗号, #创建表的一个例子 CREATE TABLE student( id int, name varchar(32), score double(4,1), -- 表示总长度为4,小数点保留一位 birthday date, insert_time timestamp ); -
复制一个已存在的表
CREATE TABLE 表名 LIKE 被复制的表名;
-
-
R(Retrieve):查询
-
查询当前数据库中所有表的名称
SHOW TABLES; -
查询表结构
DESC(DESCRIBE) 表名; -
查询某个表的字符集
SHOW CREATE TABLE 表名;
-
-
U(Update):修改
-
修改表名
ALTER TABLE 表名 RENAME TO 新的表名; -
修改表的字符集
ALTER TABLE 表名 CHARACTER SET 字符集名; -
添加一列
ALTER TABLE 表名 ADD 列名 数据类型; -
修改列的名称、类型:
-
同时修改列名和数据类型
使用CHANGE:
ALTER TABLE 表名 CHANGE 列名 新列名 新数据类型; -
修改某列数据类型
使用MODIFY:
ALTER TABLE 表名 MODIFY 列名 新数据类型;
-
-
删除列
ALTER TABLE 表名 DROP 列名;
-
-
D(Delete):删除
-
删除表
DROP TABLE 表名; -
删除表(仅在目标存在时才删除)
DROP TABLE IF EXISTS 表名;
-
2.3 DML-数据操纵语言:增删改表中数据
对具体的数据(也就是存储在表中的数据)进行操纵
| 操作 | 插入 | 更新 | 删除 |
|---|---|---|---|
| 关键字 | INSERT | UPDATE | DELETE |
2.3.1. 增加数据
-
语法
INSERT INTO 表名(列名1,列名2,...,列名n) VALUES(值1,值2,...,值n);
注意:如果表名后不指定列名,则默认给所有类添加值;除数字类型外,其他类型需要用引号('或"都行)括起来。
2.3.2. 删除数据
-
语法
DELETE FROM 表名 [WHERE 条件];
注意
- 如果不加条件,则默认删除表中所有记录
- 当要删除表中所有记录(将表设为空表时)
- 不推荐使用上述DELETE语句;(这样有多少条记录就会执行多少次删除操作,效率低且耗时)
- 推荐使用
TRUNCATE TABLE 表名;(即先删除这个表再创建一个一样的空表)
2.3.3. 修改数据
-
语法
UPDATE 表名 SET 列名1 = 值1, 列名2 = 值2, ... [WHERE 条件];
注意:如果没有加条件限定,则该操作会同时影响整列而不是影响特定元祖。
2.4 DQL-数据查询语言:查询表中的记录
查询具体的数据
2.4.1 语法
下述为SQL语句常用关键字,注意下列关键字顺序不可颠倒
SELECT
字段列表
FROM
标明列表
WHERE
条件列表
GROUP BY
分组字段
HAVING
分组之后的条件
ORDER BY
排序
LIMIT
分页限定
2.4.2. 基础查询
-
查询多个字段
SELECT 字段名1, -- 注释 字段名2, ... FROM 表名; -- 查询所有字段可以使用*代替字段列表 -
结果集去重(使用DISTINCT关键字)
SELECT DISTINCT -- 即使查询多个字段,也只需出现一次;限定所有字段的组合不重复 字段名1, ... FROM 表名; -
对指定列的值进行计算(一般进行数值型的四则运算)
SELECT math + english FROM student; -- 如果参与计算的列含NULL,则计算结果一定为NULL /* 可以使用IFNULL语句避免这种情况 */ SELECT math + IFNULL(english, 0) -- 在语句执行时,如果english成绩为NULL,当作0处理 FROM student; -
对结果集中的列起别名
SELECT math + IFNULL(english, 0) AS 别名 -- AS可省略 FROM student;
2.4.3. 条件查询
在WHERE和HAVEING字句后接条件以按条件查询
WHERE和HAVING的区别
-
WHERE在分组(GROUP BY)之前限定,不满足WHERE条件则不参与分组;
HAVING在分组之后进行限定,不满足HAVING条件则不会出现在结果集。
-
WHERE字句用于行的过滤(逐行进行判断),故WHERE后不可以跟聚集函数;
HAVING字句用于分组的过滤(逐分组进行判断),故HAVING后可以进行聚集函数的判断。
比较运算符
| 运算符 | 说明 |
|---|---|
| >、<、<=、>=、<> | <>在SQL中表示不等于(mysql中也可以使用!=) |
| BETWEEN...AND | 设定条件闭区间,如BETWEEN 100 AND 200; 表示条件在[100, 200]区间中,等价于BETWEEN 100 AND 30 |
| IN(限定值集合) | 集合表示多个值,值之间使用逗号,分隔;age IN (22, 18)等价于 age = 22 AND age = 18 |
| LIKE '张%' | 模糊查询;_(单个任意字符),%(多个任意字符) |
| IS NULL | 某一列值为NULL,注意不能使用 == NULL(同理,不为NULL使用IS NOT NULL) |
逻辑运算符
| 逻辑运算符 | 说明 |
|---|---|
| AND | 与 |
| OR | 或 |
| NOT | 非 |
2.4.4 聚集函数
将一列数据作为一个整体,进行纵向的计算
| 聚集函数 | 作用 |
|---|---|
| COUNT | 计算个数(一般选择非空的列--主键) |
| MAX | 计算最大值 |
| MIN | 计算最小值 |
| SUM | 计算和 |
| AVG | 计算平均值 |
在mysql 5之后,我们可以在聚集函数中指定参数:
- ALL(默认): 对所有行执行计算
- DISTINCT: 只包含不同值;不允许使用COUNT(DISTINCT)
-- 使用AVG函数,返回特定供货商提供产品的平均价格(只考虑不同的价格)
SELECT AVG(DISTINCT prod_price) AS avg_price
FROM products
WHERE vend_id = 1003;
注意
- 聚合函数在计算时,会自动忽略NULL值(可以使用IFNULL函数来设置该语句中NULL的执行时默认值)
- WHERE字句后不能进行聚集函数的判断
2.4.5 分组查询
将具有相同特征的数据当作一个整体进行操作
-
语法: GROUP BY 字句
-- 依照性别分组,查询平均数学成绩和id SELECT sex, AVG(math), COUNT(id) FROM student GROUP BY sex;执行结果
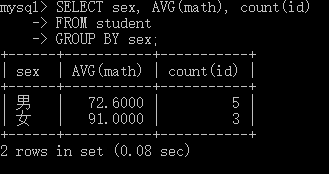
使用GROUP BY字句的重要规定
- 除聚集计算字句外,SELECT语句中每个列都必须在GROUP BY字句中给出。
- 如果分组列中有NULL值,则NULL将作为一个分组返回。
- GROUP BY字句必须出现在WHERE字句之后,HAVING字句之前。
2.4.6 排序查询
-
语法: ORDER BY 字句
-- 若存在多个排序条件,则优先满足前面的排序条件 SELECT * FROM student ORDER BY 排序字段1 排序方式1, 排序字段2 排序方式2... -
排序方式
- ASC(默认方式): 升序(即从小到大)
- DESC: 降序
2.4.6 分页查询
查看部分查询结果
-
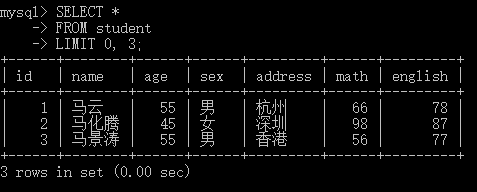
语法: LIMIT 开始索引, 本次分页查询条数(LIMIT关键字是mysql方言,其他SQL语言中关键字不同,但仍有分页操作)
-- 本次查询结果页从结果集的第1个数据开始,查询3个数据 SELECT * FROM student LIMIT 0, 3;执行结果截图
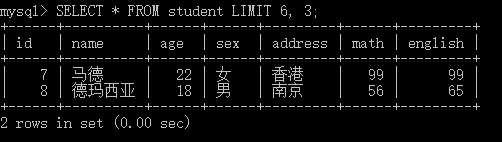
如果查询时剩余数据不足,则只会显示剩余的数据(下图即是,仅显示了两个数据)
2.5 约束
-
概念
对表中的数据进行限定,保证数据的正确性、有效性和完整性
-
分类
- 非空约束:NOT NULL
- 唯一约束:UNIQUE(MySQL中,一个列含有多个NULL值也满足唯一约束)
- 主键约束:PRIMARY KEY
- 外键约束:FOREIGN KEY
需要特别注意,删除各个约束的语法可能不同
2.5.1 非空约束
-
创建表时提供非空约束
CREATE TABLE stu { id INT, name VARCHAR(20) NOT NULL -- NAME不允许为空 }; -
对已存在的表添加非空约束
ALTER TABLE stu MODIFY name VARCHAR(20) NOT NULL; -
删除name的非空约束
ALTER TABLE stu MODIFY name VARCHAR(20);
2.5.2 唯一约束(也称唯一索引)
-
创建表时提供唯一约束G
CREATE TABLE stu ( id INT, phone_number VARCHAR(20) UNIQUE -- phone_number不允许重复 ); -
对已存在的表添加唯一约束
ALTER TABLE stu MODIFY phone_number VARCHAR(20) UNIQUE; -
删除phone_number的唯一约束
ALTER TABLE stu DROP INDEX phone_number;
2.5.3 主键约束
-
概念
- 主键,又称主码(候选码之一),要求能够唯一标识一个元组(也就是行,也称为记录)。
- 主键要求非空且唯一。
- 一张表只能有一个字段为主键。
-
创建表时提供非空约束
一个列作为主键
CREATE TABLE stu ( id INT PRIMARY KEY, -- 给id添加主键约束 name VARCHAR(20) NOT NULL -- NAME不允许为空 );多个列作为主键(联合主键)
CREATE TABLE schedule ( student_id INT, course_id INT, PRIMARY KEY(student_id, course_id) -- 将学号和课程号一同作为主键 ); -
对已存在的表添加非空约束
ALTER TABLE stu MODIFY id INT PRIMARY KEY; -
删除stu表的主键约束
ALTER TABLE stu DROP PRIMARY KEY;
2.5.4 自动增长(AUTO_INCREMENT)
AUTO_INCREMENT关键字可以让数值型的列在插入为NULL时自动增长,一般对主键使用(插入时也可以认为指定数值,增长时从该列目前最大值开始增长)
-
对数值类型主键使用AUTO_INCREMENT令其自动增长
CREATE TABLE stu( id INT PRIMARY KEY AUTO_INCREMENT, -- name VARCHAR(20) NOT NULL );这样我们在插入数据时即使没有给定主键,mysql也会自动补全主键
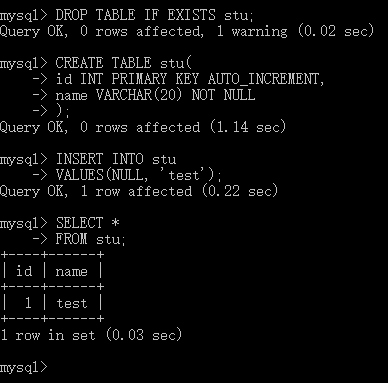
可以看到,即使我们在插入数据时将主键id设为NULL,他也没有报错且自动增长为1了
-
删除AUTO_INCREMENT关键字
ALTER TABLE stu MODIFY id INT;可以发现,自动增长和非空约束的删除语句语法是相同的,也就是说,AUTO_INCREMENT和NOT NULL是相冲突的;同样的,如果删除主键约束的语法和删除非空约束语法相同的话,那么它会和前述语句发生冲突。
-
对已存在的表中的一列设置自动增长
ALTER TABLE stu MODIFY id INT AUTO_INCREMENT;
2.5.5 外键约束
让表与表之间产生联系,保证数据的正确性。
-
在创建表时添加外键
CREATE TABLE 表名( ... , CONSTRAINT 外键名称 -- CONSTRAINT 外键名称这一字段可以省略,系统会自动创建一个外键名称 FOREIGN KEY(外键列名称) REFERENCES 主表名称(主表列名称) ); -
对已存在的表添加外键
ALTER TABLE 表名 ADD CONSTRAIN 外键名称 FOREIGN KEY(外键列名称) REFERENCES 主表名称(主表列名称); -
删除外键
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;
2.5.6 级联:CASCADE
级联包括级联更新和级联删除,可以分别进行设置或者同时进行设置。能够让不同表中级联的两个列的数据同步的进行更新/删除。
-
语法
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY 外键列名称 REFERENCES 主表名称(主表列名称) ON UPDATE CASCADE -- 设置级联更新 ON DELETE CASCADE; -- 设置级联删除 -- 此处同时设置了级联更新和级联删除,也可以单独设置某一种级联
在实际开发中应谨慎的使用级联,防止在多个表相关联时,对过多的数据同时操作。
2.6 DCL-数据控制语言:管理用户、授权
2.6.1 管理用户
-
添加用户
-- 创建用户 CREATE USER '用户名'@'主机名' IDENTIFYED BY '密码'; -
删除用户
-- 删除用户 DROP USER '用户名'@'主机名'; -
修改用户密码
-- 方式一(修改mysql数据库的user表) UPDATE uesr SET PASSWORD = PASSWARD('新密码') WHERE USER = '用户名'; -- 方式二 SET PASSWORD FOR '用户名'@'主机名' = PASSWORD('新密码'); -
查询用户
-- 1. 切换到mysql数据库 USE mysql; -- 2. 查询user表 SELECT * FROM user; -- 通配符%:表示这一用户可以在任意主机登录数据库 -
忘记root用户密码
最好去MySQL官网搜索
reset password,然后选择对应MySQL版本的解决方案。
2.6.2 授权
-
查询账户当前拥有的权限
SHOW GRANTS FOR '用户名'@'主机名'; -
授予权限
GRANT 权限列表 ON 数据库名.表名 TO '用户名'@'主机名'; -- 为某一用户授予所有数据库所有表的所有权限 GRANT ALL ON *.* TO '用户名'@'主机名'; -
撤销权限:REVOKE
REVOKE 权限列表 ON 数据库名.表名 FROM '用户名'@'主机名'; REVOKE ALL ON *.* FROM '用户名'@'主机名'; -- 删除一个用户的所有权限类似于授予所有权限
三、数据库的设计表之间的关系
3.1 表之间的关系
-
一对一
实现方式:在任意一方添加唯一的外键(添加UNIQUE约束)指向另一方的主键
-
一对多
实现方式:在多的一方建立外键,指向一的一方的主键
-
多对多
实现方式:借助第三张中间表,中间表至少包含两个字段,作为中间表的外键,分别指向两张表的主键
3.2 范式(数据库设计的准则)
设计数据库时不同的规范要求被称为不同的范式,各种范式称递次规范,越高的范式数据库冗余越小。
高范式必须满足低范式的要求。
目前关系型数据库共有六种方式:
第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。
在日常开发中,我们一般希望设计的数据库可以达到BCNF。
3.2.1 函数依赖和码
函数依赖
若A\(\rightarrow\)B,即可以通过A唯一确定B的值,则称B依赖于A。
-
完全/部分函数依赖
-
完全函数依赖
若A\(\rightarrow\)B,且A是一个属性组(由一或多个属性组成);B属性值的确定依赖于A属性组中所有的属性值,则称B完全依赖于A(故当A只有一个属性时,B一定完全依赖于A)。
例如:(学号, 课程号)\(\rightarrow\)分数
-
部分函数依赖(不完全函数依赖)
类似于完全函数依赖,如果只需A属性组中的部分值便能唯一确定B的值,则为部分函数依赖(A的子集能推出B)。
例如:(学号,课程号)\(\rightarrow\)姓名
-
-
平凡/非平凡函数依赖
-
平凡函数依赖
若A\(\rightarrow\)B, B\(\in\)A,则称B平凡函数依赖于A(B是A的子集)。
例如:(学号, 课程号)\(\rightarrow\)学号
-
非平凡函数依赖
类似的,只要满足X\(\rightarrow\)Y,Y\(\notin\)X,则称Y非平凡函数依赖于X。
-
-
传递函数依赖
A\(\rightarrow\)B,B\(\rightarrow\)C,则称C函数传递依赖于A。
例如:学号\(\rightarrow\)系编号,系编号\(\rightarrow\)系名;系名函数传递依赖于学号
码
如果在一张表中,一个属性/属性组被其余所有属性完全依赖,则称这个属性/属性组为码。
-
候选码
若一个属性组的值能够唯一标识一个元组,而其子集不能(即不能有冗余的属性),则称该属性组为候选码。
一个关系(在SQL中就是表)可能存在多个候选码
-
主码
若一个关系有多个候选码,则选定其中一个为主码(若只有一个,则主码为唯一的候选码)。
-
主/非主属性
-
主属性
候选码中的每个属性都是主属性。
-
非主属性
也称非码属性,不包含在任何候选码中的属性被称为非主属性。
-
3.2.2 范式的划分依据
-
第一范式(1NF)
每一项都是不可分割的原子项数据;即每一项都是不可再细分的数据。
-
第二范式(2NF)
每一个非主属性完全依赖于候选码;每个候选码各自组中的所有元素加起来恰好能推出所有非主属性。
如果只是在推出部分非主属性有冗余(即存在某一候选码的子集推出的非主属性有重复,但也有不重复的非主属性)则2NF不成立,但仍是候选码;如果推出所有的非主属性都有冗余,这就代表这一候选码属性组的子集便可以推出所有非主属性,能够唯一表示一个元组,那么这组候选码不满足候选码的定义。
-
第三范式(3NF)
不存在非主属性对码的传递依赖(非主属性之间不存在函数依赖)。
-
巴斯-科德范式(BCNF)
不存在主属性对码的部分依赖(主属性以外的码不能推出主属性)。
四. 多表查询
如果直接对多个表用*通配符进行查询,则会产生很多无用的冗余数据(查询结果为笛卡尔积)
SELECT *
FROM student, course;
我们实际使用中,笛卡尔积通常不是我们需要的数据。我们可以使用下面几种方法来消除冗余数据:
- 内连接查询
- 外连接查询
- 子查询
4.1 内连接查询
分为隐式和显式,在条件相同的情况下, 两种内连接查询是等价的。
但我们应优先使用显示外连接(也就是INNER JOIN语法),这样能确保不忘记联结条件,有时也能提高性能。
4.1.1 隐式内连接
-
语法
SELECT 字段列表 FROM 表名1, 表名2, ... WHERE 条件;
4.1.2 显式内连接
-
语法
SELECT 字段列表 FROM 表名1 (INNER) JOIN 表名2 ON 条件;
4.2 外连接查询
4.2.1 左外连接
查询左表所有数据以及右表和左表的交集(如存在左表有而右表没有的行,则右表部分用NULL表示)。
-
语法
SELECT 字段列表 FROM 表名1 LEFT (OUTER) JOIN 表名2 ON 条件;
4.2.2 右外连接
类似左外连接,查询右表所有数据以及左表和右表的交集。
-
语法
SELECT 字段列表 FROM 表名1 RIGHT (OUTER) JOIN 表名2 ON 条件;
4.3 子查询
在查询语句中嵌套的查询被称作子查询。
子查询拥有三种不同情况:
- 子查询结果集为单行单列。
- 子查询结果集为多行单列。
- 子查询结果集为多行多列。
4.3.1 子查询结果集为单行单列
使用比较运算符进行判断。
-- 查询工资高于平均水平的员工信息
SELECT *
FROM employee
WHERE salary > (SELECT AVG(salary)
FROM employee);
4.3.2 子查询结果集为多行单列
使用操作符IN进行判断。
-- 查询数计院和经管院学生的信息
SELECT *
FROM student
WHERE department_id IN (SELECT department_id
FROM department
WHERE name = '数计院' OR name = '经管院');
4.3.3 子查询结果集为多行多列
将子查询结果集当作一张虚拟表参与查询
-- 查询19年之后入职员工的个人信息及其部门信息
SELECT *
FROM department AS t1, (SELECT *
FROM employee
WHERE employee.join_date > '2019-01-01') AS t2
WHERE t1.id = t2.dept_id;
其实上述情况也可以通过使用内连接来解决,而且代码会更加简洁。
后续还有视图操作,等有时间了再更新

 浙公网安备 33010602011771号
浙公网安备 33010602011771号