【论文翻译】Neural Architectures for Named Entity Recognition
Abstract
处于领先水平的命名实体识别系统严重依赖于人工设计的特征与特定领域的知识,从而更高效地学习小型、带标记的语料库 。在这篇论文里我们介绍了两种神经结构——一种结构是基于双向LSTM与条件随机场,另一种结构是通过一种基于转换、Shift-Reduce解析的算法构造并标记了单词。我们的模型依赖于单词信息的两个来源:一是从带监督语料库中学习的基于单字的词表示,二是从无注释语料库中学习的非监督词表示。对于NER(命名实体识别),在使用四种语言且没有任何术语资源(比如Gazetteers,斯坦福开源的地名数据库)的前提下,我们的模型表现出了较好的性能。
1 Introduction
NER 是一个具有挑战性的学习问题。一方面,在大多数的语言和领域中可获取的监督训练数据都是很少的。另一方面,对于可以命名的单词种类限制很少,所以很难从这么小的数据集中泛化出好的模型。因此精心构造的词素特征和术语资源,比如Gazetteers(地名数据库),被广泛用于解决本次任务。不幸地是,在新语言与新领域的发展过程中术语资源与特征是很昂贵的,这给新语言与新领域的发展带来了挑战。利用无注释语料库进行的无监督学习提供了一个可替代策略,以便于即使学习的是小规模的监督数据集,也有较好的泛化能力。然而,甚至那些广泛依赖于无监督特征的系统(Collobert et al., 2011; Turian et al., 2010;Lin and Wu, 2009; Ando and Zhang, 2005b, in-ter alia) 已经使用这些去扩充,而不是代替人工设计的特征(例如关于特定语言的大写模式和特征类别的知识)和专业知识的资源(例如地名录)。
在这个文章中,对于NER,我们提出了一种的神经结构,它不依赖术语资源或者特征,而仅仅依赖小规模的监督训练数据与未注释的语料库。我们设计的模型直观解释有两个。第一,由于一个名称通常由多个词条组成,因此对任意一个标记的词性标注决策进行联合推理是很重要的。在这里我们对比了两种模型,一种是具有序列条件随机层的双向LSTM(LSTM-CRF,详见2),另一种是新模型,利用Stack LSTM表示状态并进行Shift-Reduce解析的基于转换的算法,构造和标记大量输入句子(S-LSTM,详见3)。第二,被作为一个名称的含词条等级的词包括了词的构成形式(被词性标记为一个名称的词通畅是什么样子的?)和词的语料库中的上下文信息(在语料库中,被标记的词通常位于哪里?)。为了得到词素的敏感性,我们使用基于单字的单词代表模型(LIng et al.,2015b)从而得到词素在语料库中分布的敏感性,我们将前者与在语料库中分布的敏感性结合起来看(Mikolov et al., 2013b)。我们的单词代表模型将这两者结合起来,而dropout正则化训练学习被用来改进该模型从而考虑到两者来源对模型的贡献(详见4)。
英语,荷兰语,德语和西班牙语的实验表明,在没有任何人工处理的特征或地名录的前提下(详见5),我们能够在荷兰语,德语和西班牙语中的LSTM-CRF模型获得了优异的NER性能,并且在英语中也获得了较好的NER性能。基于转换的算法同样以几种语言超过了以前公布的最好结果,尽管它的表现不如LSTM-CRF模型好。
2 LSTM-CRF Model
在简介中我们提到了LSTM与CRF,并提出了一种混合的词性标注结构。这个结构与之前Col-lobert et al. (2011) 和 Huang et al. (2015)提出的一种结构是相似的。
2.1 LSTM
递归神经网络是神经网络的一种,它用于处理序列化的数据。设输入的向量序列为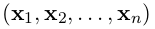 ,将输出另一个序列
,将输出另一个序列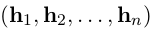 ,它代表输入序列每一步的某些信息。虽然理论上RNN也可以学习序列的长期依赖关系,但实际上它们并不能这么做而是倾向于学习最新输入的序列(Bengio et al.,1994)。长短时记忆网络被设计成增加缓存单元以解决该问题,并已经被证明可以学习到序列的长期依赖关系。它利用一些“门”来控制输入到缓存单元的比例,以及遗忘先前状态的比例。(Hochreiter and Schmidhuber, 1997)。我们使用以下实现:
,它代表输入序列每一步的某些信息。虽然理论上RNN也可以学习序列的长期依赖关系,但实际上它们并不能这么做而是倾向于学习最新输入的序列(Bengio et al.,1994)。长短时记忆网络被设计成增加缓存单元以解决该问题,并已经被证明可以学习到序列的长期依赖关系。它利用一些“门”来控制输入到缓存单元的比例,以及遗忘先前状态的比例。(Hochreiter and Schmidhuber, 1997)。我们使用以下实现:
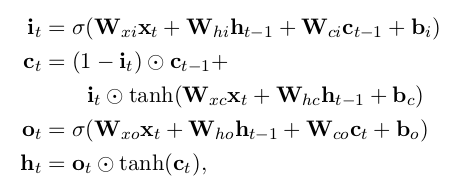
这里的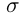 指的是sigmoid函数,
指的是sigmoid函数, 指的是向量元素积,即Hadamard积。
指的是向量元素积,即Hadamard积。
对于一个给定包含n个词的句子,每一个都被表示为为一个d维向量,LSTM计算了句子下文每t个词的一个输出值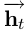 。当然,也有特指上文的输出值
。当然,也有特指上文的输出值 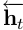 ,这可以利用LSTM读句子的反向序列实现。我们将前者称为正向LSTM,后者称为反向LSTM。他们是两个截然不同的具有不同参数的网络。正向LSTM与反向LSTM统称为双向LSTM(Gravesand Schmidhuber, 2005)。使用该模型时的词表示是通过该单词的上下文得到的,即
,这可以利用LSTM读句子的反向序列实现。我们将前者称为正向LSTM,后者称为反向LSTM。他们是两个截然不同的具有不同参数的网络。正向LSTM与反向LSTM统称为双向LSTM(Gravesand Schmidhuber, 2005)。使用该模型时的词表示是通过该单词的上下文得到的,即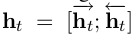 。这些表征有效包括了上下文中的单词表征,这对于许多词性标注应用都很有用。
。这些表征有效包括了上下文中的单词表征,这对于许多词性标注应用都很有用。
2.2 CRF Tagging Models
一个相当简单但是极其有效的词性标记系统是使用 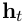 作为特征为每一个输出
作为特征为每一个输出 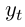 做出独立的词性标记决策(Ling et al.,2015b)。尽管这个模型成功解决了类似 POS tagging 这样简单的问题,但是当需要输出标签之间存在有很强的依赖关系时,它的独立分类决策仍会受到限制。而NER就是这样的一个任务,因为对带多标签的序列进行表征的语法施加了许多强约束(比如,I-PER不能遵循B-LOC;详见2.4),这样的话,模型一开始的独立性假设就不满足了。
做出独立的词性标记决策(Ling et al.,2015b)。尽管这个模型成功解决了类似 POS tagging 这样简单的问题,但是当需要输出标签之间存在有很强的依赖关系时,它的独立分类决策仍会受到限制。而NER就是这样的一个任务,因为对带多标签的序列进行表征的语法施加了许多强约束(比如,I-PER不能遵循B-LOC;详见2.4),这样的话,模型一开始的独立性假设就不满足了。
因此,我们的模型不是独立地词性标记决策,而是使用条件随机场对它们进行联合建模(Lafferty et al., 2001)。对于这么一个输入句子
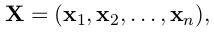
我们认为![]() 是双向LSTM输出的评分矩阵。
是双向LSTM输出的评分矩阵。![]() 的规模是
的规模是 ![]() ,这里的 k 是不同标签的数量,而
,这里的 k 是不同标签的数量,而 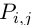 对应句子中第 i 个词的第 j 各标签的评分。对于一个预测的序列
对应句子中第 i 个词的第 j 各标签的评分。对于一个预测的序列
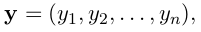
我们定义它的评分为
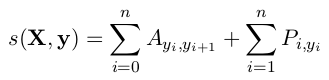
这里的![]() 是一个转换分数的矩阵,使得
是一个转换分数的矩阵,使得 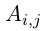 表示为从标签 i 到标签 j 转换的分数。
表示为从标签 i 到标签 j 转换的分数。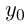 和
和 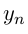 是一个句子的起始标签与尾标签,我们将它们添加到一个可能标签的集合里。因此
是一个句子的起始标签与尾标签,我们将它们添加到一个可能标签的集合里。因此 ![]() 是一个规模为
是一个规模为 ![]() 的方阵。
的方阵。
对于所有可能的标签序列,一个 softmax 产生序列 ![]() 的概率是:
的概率是:
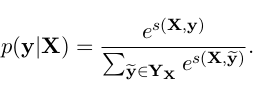
在训练过程中,我们将预测正确的标签序列的对数概率最大化:
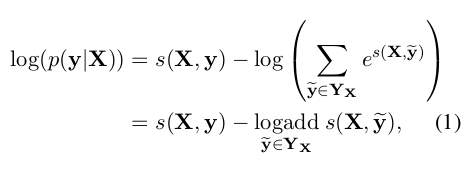
注意,这里的 logadd 十分突兀,译者觉得应该是 python 中 numpy 类的 logaddexp 方法。
关于 numpy.logaddexp 链接如下:
https://docs.scipy.org/doc/numpy/reference/generated/numpy.logaddexp.html
回到原文。这里的 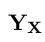 指的是对于一个句子
指的是对于一个句子 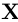 所有可能的标签序列(甚至有些还没有验证为 IOB 格式)。对于上面的数学公式,很明显我们鼓励我们的网络输出一个有效的标签序列。当解码时,我们利用下面的式子:
所有可能的标签序列(甚至有些还没有验证为 IOB 格式)。对于上面的数学公式,很明显我们鼓励我们的网络输出一个有效的标签序列。当解码时,我们利用下面的式子:
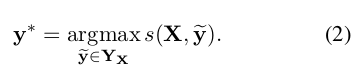
获得最大评分从而预测出输出序列。
因为我们只根据各输出之间的二元关系进行建模,所以可以用动态规划思想解决等式(1)中求和与等式(2)中的最大化y*。
2.3 Parameterization and Training
与每个词条(即 ![]() )的每个词性标注决策相关的评分是由双向LSTM计算的输出(每个词的向量)和二元语法的转移评分(即
)的每个词性标注决策相关的评分是由双向LSTM计算的输出(每个词的向量)和二元语法的转移评分(即 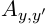 )一起计算出来的。结构示意图如 Figure 1 。圆圈代表观测变量,菱形代表其父母的确定性函数,双圆圈代表随机变量。
)一起计算出来的。结构示意图如 Figure 1 。圆圈代表观测变量,菱形代表其父母的确定性函数,双圆圈代表随机变量。
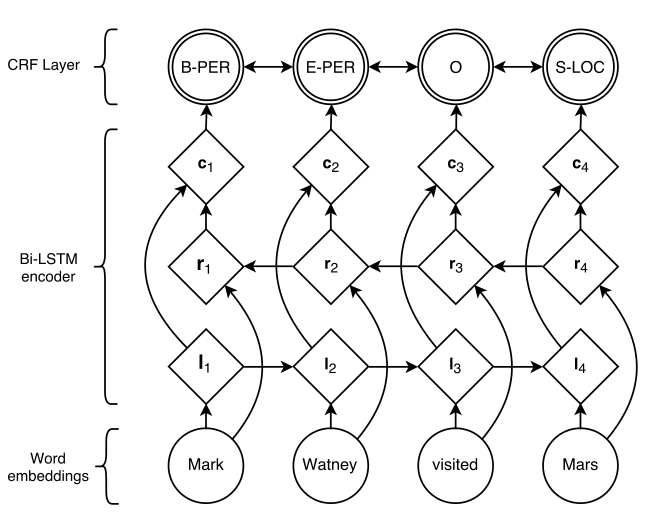
Figure 1:网络的主要结构。词向量输入到BILSTM,li 代表单词 i 与它的上文,ri 代表单词 i 与它的下文,把这两者联系起来,用 ci 代表单词i与它的上下文。
因此,该模型的参数是二元语法模型的转移分数矩阵![]() ,而产生评分矩阵
,而产生评分矩阵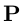 的参数即双向LSTM的参数——线性的特征权重与词向量。如 2.2 部分所述,令
的参数即双向LSTM的参数——线性的特征权重与词向量。如 2.2 部分所述,令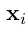 为句子中每个单词的词向量序列,
为句子中每个单词的词向量序列,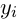 为它们相关联的标签。我们将在第4部分分析如何对进行建模。词向量序列作为双向LSTM的输入,而后双向LSTM模型返回每个单词的上下文表示,如2.1。
为它们相关联的标签。我们将在第4部分分析如何对进行建模。词向量序列作为双向LSTM的输入,而后双向LSTM模型返回每个单词的上下文表示,如2.1。
这些表示可以在 ci 中被联系起来并被线性投影到一个尺寸等于独立标签数量的层上。我们不使用 softmax 作为该层的输出,而是使用之前说过的CRF以考虑到相邻标签的相关性,从而产生每一个词的最终预测 。另外,我们观察到在 ci 和CRF层之间添加一个隐含层可以稍稍改进我们的结果。所以本论文所有模型的实验也都加入了隐含层。给出观察的词,对于一个已注释语料库中的NER标签观测序列,这些参数通过训练将其对应的等式(1)最大化。
2.4 Tagging Schemes
命名实体识别的任务是给句子中的每一个词都分配一个命名实体标签。一个命名实体可以标记句子中的多个词条。句子通常以 IOB 格式(Inside, Outside, Beginning)表示,如果词条是一个命名实体的开始那么就标记其为 B 标签,同理 I 标签指词条在一个命名实体的内部,而 O 标签指词条在一个命名实体的外部。然而在这里我们使用的是命名实体识别更常用的 IOBES 词性标注方案,它是 IOB 的一种变体,用 S 标签标记词条是一个命名实体的开始,E 标签标记词条是一个命名实体的结束。使用这种办法能够以高置信度将标注为 I 标签的词的后续单词的词性选项缩小为 I 标签或者是 E 标签,而 IOB 方案仅仅能够确定后续单词是不是在命名实体内部。 Ratinov 、 Roth(2009)与 Dai et al.(2015)提出使用 IOBES 方案可以改善模型的性能。
3 Transition-Based Chunking Model
...
3.1 Chunking Algorithm
...
3.2 Represening Labeled Chunks
...
4 Input Word Embeddings
...
4.1 Character-based models of words
...
4.2 Pretrained embeddings
...
4.3 Dropout training
...
5 Experiments
...
5.1 Training
...
5.2 Data Sets
...
5.3 Results
...
5.4 Network Architectures
...
6 Related Work
...
7 Conclusion
...
Acknowledgments
...
References
Rie Kubota Ando and Tong Zhang. 2005a. A framework
for learning predictive structures from multiple tasks
and unlabeled data. The Journal of Machine Learning
Research, 6:1817–1853.
Rie Kubota Ando and Tong Zhang. 2005b. Learning
predictive structures. JMLR, 6:1817–1853.
Miguel Ballesteros, Chris Dyer, and Noah A. Smith.
2015. Improved transition-based dependency parsing
by modeling characters instead of words with LSTMs.
In Proceedings of EMNLP.
Miguel Ballesteros, Yoav Golderg, Chris Dyer, and
Noah A. Smith.2016.Training with Explo-
ration Improves a Greedy Stack-LSTM Parser. In
arXiv:1603.03793.
Yoshua Bengio, Patrice Simard, and Paolo Frasconi.
1994. Learning long-term dependencies with gradient
descent is difficult. Neural Networks, IEEE Transac-
tions on, 5(2):157–166.
Chris Biemann, Gerhard Heyer, Uwe Quasthoff, and
Matthias Richter.2007.The leipzig corporacollection-monolingual
corpora of standard size. Pro-
ceedings of Corpus Linguistic.
Chris Callison-Burch, Philipp Koehn, Christof Monz,
Kay Peterson, Mark Przybocki, and Omar F Zaidan.
2010. Findings of the 2010 joint workshop on sta-
tistical machine translation and metrics for machine
translation. In Proceedings of the Joint Fifth Workshop
on Statistical Machine Translation and MetricsMATR,
pages 17–53. Association for Computational Linguis-
tics.
Xavier Carreras, Lluı́s Màrquez, and Lluı́s Padró. 2002.
Named entity extraction using adaboost, proceedings
of the 6th conference on natural language learning.
August, 31:1–4.
Jason PC Chiu and Eric Nichols. 2015. Named en-
tity recognition with bidirectional lstm-cnns. arXiv
preprint arXiv:1511.08308.
Ronan Collobert, Jason Weston, Léon Bottou, Michael
Karlen, Koray Kavukcuoglu, and Pavel Kuksa. 2011.
Natural language processing (almost) from scratch.
The Journal of Machine Learning Research, 12:2493–
2537.
Silviu Cucerzan and David Yarowsky. 1999. Language
independent named entity recognition combining mor-
phological and contextual evidence. In Proceedings of
the 1999 Joint SIGDAT Conference on EMNLP and
VLC, pages 90–99.
Silviu Cucerzan and David Yarowsky. 2002. Language
independent ner using a unified model of internal and
contextual evidence. In proceedings of the 6th confer-
ence on Natural language learning-Volume 20, pages
1–4. Association for Computational Linguistics.
Hong-Jie Dai, Po-Ting Lai, Yung-Chun Chang, and
Richard Tzong-Han Tsai. 2015. Enhancing of chem-
ical compound and drug name recognition using rep-
resentative tag scheme and fine-grained tokenization.
Journal of cheminformatics, 7(Suppl 1):S14.
Chris Dyer, Miguel Ballesteros, Wang Ling, Austin
Matthews, and Noah A. Smith. 2015. Transition-
based dependency parsing with stack long short-term
memory. In Proc. ACL.
Jacob Eisenstein, Tae Yano, William W Cohen, Noah A
Smith, and Eric P Xing. 2011. Structured databases
of named entities from bayesian nonparametrics. In
Proceedings of the First Workshop on Unsupervised
Learning in NLP, pages 2–12. Association for Com-
putational Linguistics.
Radu Florian, Abe Ittycheriah, Hongyan Jing, and Tong
Zhang. 2003. Named entity recognition through clas-
sifier combination. In Proceedings of the seventh con-
ference on Natural language learning at HLT-NAACL
2003-Volume 4, pages 168–171. Association for Com-
putational Linguistics.
Dan Gillick, Cliff Brunk, Oriol Vinyals, and Amarnag
Subramanya. 2015. Multilingual language processing
from bytes. arXiv preprint arXiv:1512.00103.
David Graff. 2011. Spanish gigaword third edition
(ldc2011t12). Linguistic Data Consortium, Univer-
sity of Pennsylvania, Philadelphia, PA.
Alex Graves and Jürgen Schmidhuber. 2005. Framewise
phoneme classification with bidirectional LSTM net-
works. In Proc. IJCNN.
Geoffrey E Hinton, Nitish Srivastava, Alex Krizhevsky,
Ilya Sutskever, and Ruslan R Salakhutdinov. 2012.
Improving neural networks by preventing co-
adaptation of feature detectors.
arXiv preprint
arXiv:1207.0580.
Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long
short-term memory. Neural Computation, 9(8):1735–
1780.
Johannes Hoffart, Mohamed Amir Yosef, Ilaria Bordino,
Hagen Fürstenau, Manfred Pinkal, Marc Spaniol,
Bilyana Taneva, Stefan Thater, and Gerhard Weikum.
2011. Robust disambiguation of named entities in text.
In Proceedings of the Conference on Empirical Meth-
ods in Natural Language Processing, pages 782–792.
Association for Computational Linguistics.
Zhiheng Huang, Wei Xu, and Kai Yu. 2015. Bidi-
rectional LSTM-CRF models for sequence tagging.
CoRR, abs/1508.01991.
Yoon Kim, Yacine Jernite, David Sontag, and Alexan-
der M. Rush. 2015. Character-aware neural language
models. CoRR, abs/1508.06615.
Diederik Kingma and Jimmy Ba. 2014. Adam: A
method for stochastic optimization. arXiv preprint
arXiv:1412.6980.
John Lafferty, Andrew McCallum, and Fernando CN
Pereira. 2001. Conditional random fields: Probabilis-
tic models for segmenting and labeling sequence data.
In Proc. ICML.
Dekang Lin and Xiaoyun Wu. 2009. Phrase clustering
for discriminative learning. In Proceedings of the Joint
Conference of the 47th Annual Meeting of the ACL and
the 4th International Joint Conference on Natural Lan-
guage Processing of the AFNLP: Volume 2-Volume 2,
pages 1030–1038. Association for Computational Lin-
guistics.
Wang Ling, Lin Chu-Cheng, Yulia Tsvetkov, Silvio Amir,
Rámon Fernandez Astudillo, Chris Dyer, Alan W
Black, and Isabel Trancoso. 2015a. Not all contexts
are created equal: Better word representations with
variable attention. In Proc. EMNLP.
Wang Ling, Tiago Luı́s, Luı́s Marujo, Ramón Fernandez
Astudillo, Silvio Amir, Chris Dyer, Alan W Black, and
Isabel Trancoso. 2015b. Finding function in form:
Compositional character models for open vocabulary
word representation. In Proceedings of the Conference
on Empirical Methods in Natural Language Process-
ing (EMNLP).
Gang Luo, Xiaojiang Huang, Chin-Yew Lin, and Zaiqing
Nie. 2015. Joint named entity recognition and disam-
biguation. In Proc. EMNLP.
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey
Dean. 2013a. Efficient estimation of word representa-
tions in vector space. arXiv preprint arXiv:1301.3781.
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Cor-
rado, and Jeff Dean. 2013b. Distributed representa-
tions of words and phrases and their compositionality.
In Proc. NIPS.
Joakim Nivre. 2004. Incrementality in deterministic de-
pendency parsing. In Proceedings of the Workshop on
Incremental Parsing: Bringing Engineering and Cog-
nition Together.
Joel Nothman, Nicky Ringland, Will Radford, Tara Mur-
phy, and James R Curran. 2013. Learning multilin-
gual named entity recognition from wikipedia. Artifi-
cial Intelligence, 194:151–175.
Robert Parker, David Graff, Junbo Kong, Ke Chen, and
Kazuaki Maeda. 2009. English gigaword fourth
edition (ldc2009t13). Linguistic Data Consortium,
Univer-sity of Pennsylvania, Philadelphia, PA.
Alexandre Passos, Vineet Kumar, and Andrew Mc-
Callum. 2014. Lexicon infused phrase embed-
dings for named entity resolution. arXiv preprint
arXiv:1404.5367.
Yanjun Qi, Ronan Collobert, Pavel Kuksa, Koray
Kavukcuoglu, and Jason Weston. 2009. Combining
labeled and unlabeled data with word-class distribu-
tion learning. In Proceedings of the 18th ACM con-
ference on Information and knowledge management,
pages 1737–1740. ACM.
Lev Ratinov and Dan Roth. 2009. Design challenges
and misconceptions in named entity recognition. In
Proceedings of the Thirteenth Conference on Compu-
tational Natural Language Learning, pages 147–155.
Association for Computational Linguistics.
Cicero Nogueira dos Santos and Victor Guimarães. 2015.
Boosting named entity recognition with neural charac-
ter embeddings. arXiv preprint arXiv:1505.05008.
Erik F. Tjong Kim Sang and Fien De Meulder. 2003. In-
troduction to the conll-2003 shared task: Language-
independent named entity recognition.
In Proc.
CoNLL.
Erik F. Tjong Kim Sang. 2002. Introduction to the conll-
2002 shared task: Language-independent named entity
recognition. In Proc. CoNLL.
Joseph Turian, Lev Ratinov, and Yoshua Bengio. 2010.
Word representations: A simple and general method
for semi-supervised learning. In Proc. ACL.
Matthew D Zeiler. 2012. Adadelta: An adaptive learning
rate method. arXiv preprint arXiv:1212.5701.
Yue Zhang and Stephen Clark. 2011. Syntactic process-
ing using the generalized perceptron and beam search.
Computational Linguistics, 37(1).
Xiang Zhang, Junbo Zhao, and Yann LeCun. 2015.
Character-level convolutional networks for text classi-
fication. In Advances in Neural Information Process-
ing Systems, pages 649–657.
Jie Zhou and Wei Xu. 2015. End-to-end learning of se-
mantic role labeling using recurrent neural networks.
In Proceedings of the Annual Meeting of the Associa-
tion for Computational Linguistics.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号