快速排序的介绍以及其两大坑点
前言
学完冒泡排序之后,我们会发现冒泡排序虽然比桶排序的空间效率要高,但是冒泡排序的执行效率却是很低的,它的时间复杂度达到O(N^2)。假设电脑一秒可运行10亿次,那么对一亿个数进行排序的话,桶排序需要0.1秒,而冒泡排序需要1千万秒,相当于115天,是不是很可怕?有没有什么双赢的算法呢?有的,就是快速排序。
步骤
假设给出一个数列 6 1 2 7 9 3 4 5 10 8,输出 1 2 3 4 5 6 7 8 9 10。我们利用快速排序的解法去做
1.设一个基准数(也称中枢元素,起对照作用),譬如设头元素6
2.把比基准数小的都排在左边,把比基准数大的都排在右边,譬如3 1 2 5 4 6 9 7 10 8
3.对左边的数列 3 1 2 5 4 再进行步骤 1 步骤 2 的操作
4.子数列排序成了 2 1 3 5 4
5.再对它的子数列进行步骤 1 2 的操作
6.最终将得到10个单元素数列 1 , 2 , 3, 4, 5, 6, 7, 8, 9, 10
第一轮快排的卡通版过程图如下(源于《啊哈!算法》):

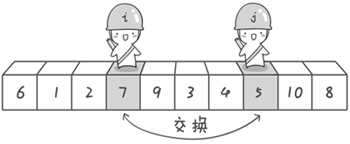

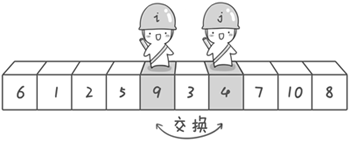

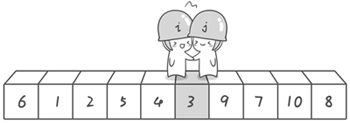

全部的流程图如下:

代码实现
void quickSort (int *a, int left, int right) { int centerIndex; int i, j, temp; centerIndex = a[left]; i = left; j = right; if (i >= j) {return;} // prevent the ocurrence "left > j-1" while (i < j) { while ((a[j] >= centerIndex) && (i < j)) { // j is first --j; } while ((a[i] <= centerIndex) && (i < j)) { ++i; } temp = a[i]; a[i] = a[j]; a[j] = temp; } temp = a[j]; //exchange real centerIndex a[j] = a[left]; a[left] = temp; quickSort(a, left, j-1); quickSort(a, j+1, right); }
或者使用这个更可读性更好的 C++ 版本,能解决 Leetcode 912. Sort an Array,做了最基本的优化,遇到已排序的数组就不用再排序了
class Solution { public: vector<int> sortArray(vector<int>& nums) { if (nums.size() <= 1) return nums; // 快排的最坏时间复杂度是 O(n^2),过不去 case,需要对最坏情况(排好序或倒序)进行额外处理 if (std::is_sorted(nums.begin(), nums.end())) { return nums; } if (std::is_sorted(nums.begin(), nums.end(), std::greater<int>())) { std::reverse(nums.begin(), nums.end()); return nums; } qsort(nums, 0, nums.size() - 1); return nums; } private: void qsort(vector<int>& nums, int left, int right) { // std::cout << "left: " << left << ", right: " << right << std::endl; if (left >= right) return; int pivot = partition(nums, left, right); qsort(nums, left, pivot - 1); qsort(nums, pivot + 1, right); } int partition(vector<int>& nums, int left, int right) { int pivot = left; while (left < right) { while (left < right && nums[right] >= nums[pivot]) --right; while (left < right && nums[left] <= nums[pivot]) ++left; if (left != right) std::swap(nums[left], nums[right]); } if (pivot != right) std::swap(nums[pivot], nums[right]); return right; } };
两大坑点
第一个坑点:每次扫描时必须先保证哨兵 j 先动,然后哨兵 i 再动,而且在扫描时时刻保持 i<j 。
这个设计思路是为了应对当子序列已经是排序好的情况,此时只能交换的数字只能是中枢元素本本身,不应把基准数与其他数字再交换而破坏了原子序列。举个例子,当子序列为 1 2 3 4 ,设基准数是 1 ,如果此时i 先走,最终 i = 1, j = 1,a[i] = 2,a[j] = 2,交换基准数与 a[j] ,子序列变为 2 1 3 4 ,原子序列被破坏。
第二个坑点是递归的出口需考虑哨兵 j 越界的情况,结束递归的条件是 left > =right 而不是 left == right。
我一开始也认为递归出口设置为 left == right 就万事大吉了,因为它可以表示当前子序列只有一个元素,那么就不用进行快排了。但是漏考虑了在子序列已经排序好的情况时 进行扫描的话,会出现 j - 1 < left 的越界问题。举个例子,当子序列为 3 7 9 6 ,基准数是 3 ,最终经过扫描后 j = 0,a[j] = 0,此时 (j-1) = -1,你将把 j-1 作为 right 传入函数中,而此时 left = 0,下次的分治会出现 left > right ,出现逻辑问题。
时间复杂度以及空间复杂度分析
平均情况下,划分需要时间 O(n),而递归深度O(lgn) ,所以时间复杂度是 O(nlgn),最坏情况是输入有序串,导致 O(n^2) ,如果采用随机化算法,时间复杂度为O(nlgn)
由于需要递归调用,所以空间复杂度是 O(lgn)
总结
总的来说,快排的操作是这样的:快速排序有两个方向,当 a[i] <= a[center_index],左边的i下标一直往右走,其中 center_index 是中枢元素的数组下标,一般取为数组第0个元素。而当 a[j] > a[center_index],右边的j下标一直往左走。如果i和j都走不动了,i <= j, 交换a[i]和a[j],重复上面的过程,直到i>j。交换 a[j] 和 a[center_index],完成一趟快速排序。
快速排序办法之所以快速,是因为相比于冒泡排序,每次交换都是跳跃式的。每次排序的时候都设置一个基准点,小的放左边,大的放右边,这样就不会像冒泡排序那样只在相邻的数之间进行交换,交换的距离就大得多了。当然,在最坏的情况下,仍可能是相邻的两个数进行交换。因此,快排的最差时间复杂度仍是O(N^2),它的平均时间复杂度为O(NlogN)。这种方法基于“二分”思想,涉及到了分治法(不断分割成子数列,然后分别处理)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号