
SQLServer一次性删除重复的数据
delete from [GCPCore].[GCP.Product].[CityMall] where AreaID in(select AreaID from [GCPCore].[GCP.Product].[CityMall]
group by AreaID
having count(AreaID) > 1)
以上是删除所有重复数据,如果要删除重复数据并且保留一条,则:
假设数据库表结构如下图:
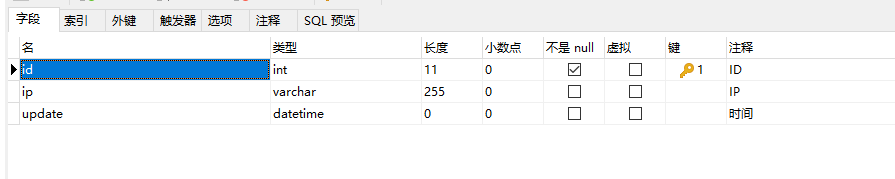
保留id较小的数据:
//根据IP相同,保留ID较小的一条数据,删除其它重复数据
DELETE t1 FROM err t1, err t2
WHERE t1.ip = t2.ip AND t1.id > t2.id
保留id较大的数据:
//根据IP相同,保留ID较大的一条数据,删除其它重复数据
DELETE t1 FROM err t1, err t2
WHERE t1.ip = t2.ip AND t1.id < t2.id
还有另外一个思路方法相对来说效率用时更快,就是用插入新表的方式:
INSERT INTO err(ip, update)
SELECT DISTINCT ip FROM student
第二种方法所需时间更短,但是方法二当主键为uuid时,需要处理一下,可将把主键设置为int自增,然后执行下面的sql就可以:
UPDATE err SET id = uuid()
人说,如果你很想要一样东西,就放它走 。如果它回来找你,那么它永远都是你的。要是它没有回来,那么不用再等了,因为它根本就不是你的。
——伊恩·麦克尤恩

 浙公网安备 33010602011771号
浙公网安备 33010602011771号