
第一次博客作业
第一次博客作业
字符串分析
调用官方包的Parse Mode。并使用NodeTree类的build方法,通过正则表达式来创建表达式树。
逻辑结构
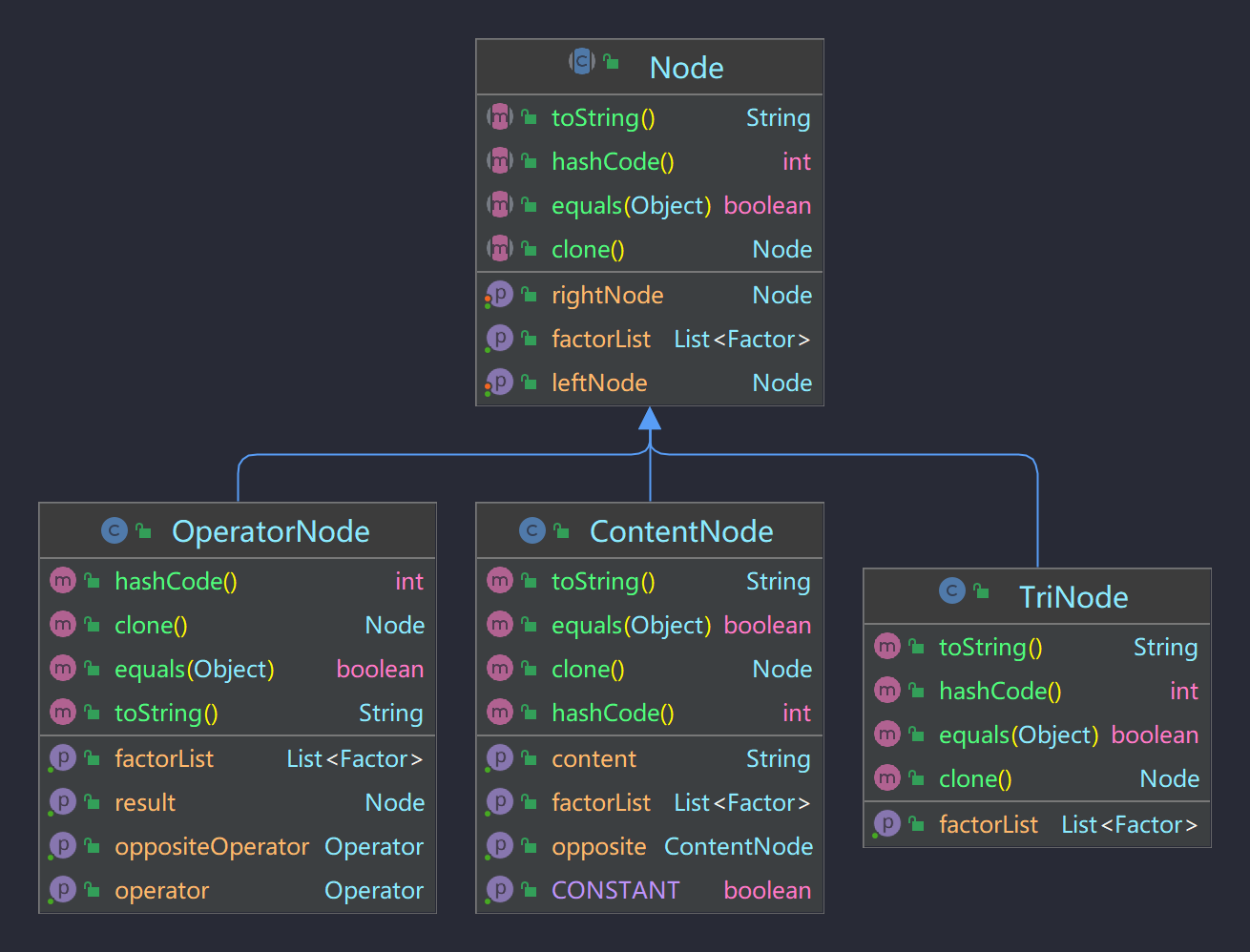
如图所示,我使用二叉树的形式来存储表达式。
Node
抽象类,实现了Cloneable接口,并且已经实现了左右子节点的get与set方法。且拓展类在继承Node类时,需要实现Node类的toString(), hashcode(), equals(), clone()方法。
toString()方法用于归一化输出;clone()方法用于归一化浅复制。
getFactorList()方法用于合并同类项。
OperatorNode
继承Node类,表示计算结点。存储符号枚举Operator。
Operator枚举如下图:
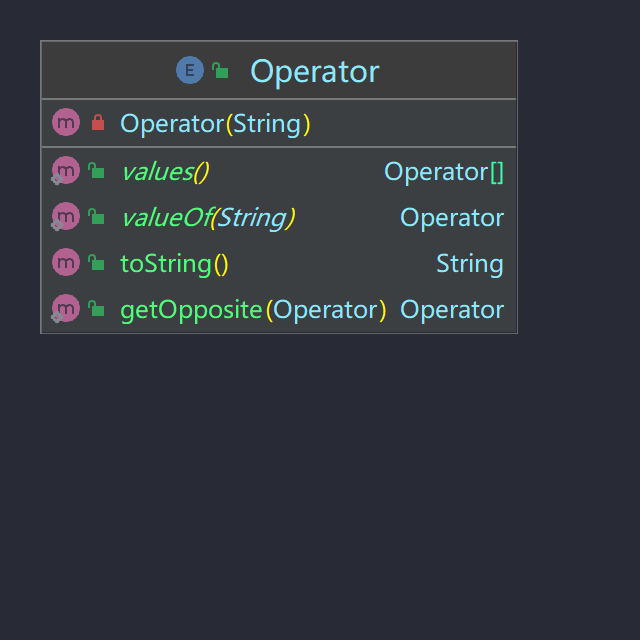
其中getOpposite()方法是针对加减号的互换的;若MUL、POW实现调用该方法会抛出异常。
ContentNode
继承Node类,表示常数或“x”。其中isContent()方法用于判断该结点是否为常数。
TriNode
继承Node类,表示三角函数,存储三角函数枚举TriType,分别为SIN与COS。要求TriNode只有右子节点。set或getTriNode的左子节点会抛出异常。
流程结构
public class Main {
public static void main(String[] args) throws Exception {
Node node = NodeTree.build(Inputer.getInputStrList());
node = PostOptimizer.optimize(node);
System.out.println(OutputOptimizer.optimize(node));
}
}
如代码所示,总的流程分为三个阶段:
Inputer.getInputStrList()
获取输入
NodeTree.build()
生成表达式树
PostOptimizer.optimize()
处理打开括号任务,其中直接在表达式树上进行操作。流程代码如下:
public static Node optimize(Node inputNode) throws Exception {
Node node = inputNode;
node = subEqualOptimize(node);
node = contentNegPosOptimize(node);
node = powOptimize(node);
node = bracketsOptimize(node);
node = mulZeroOptimize(node);
node = negOptimize(node);
return node;
}
OutputOptimizer.optimize()
调用表达式树的toString()方法,并将得到的字符串进行响应的优化。流程代码如下:
public static String optimize(Node node) {
String outputStr = node.toString();
outputStr = operatorOptimize(outputStr);
outputStr = firstZeroOptimize(outputStr);
return outputStr;
}
度量分析
方法复杂度
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| com.company.ContentNode.clone() | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.ContentNode.ContentNode(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.ContentNode.equals(Object) | 1.0 | 1.0 | 2.0 | 2.0 |
| com.company.ContentNode.getContent() | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.ContentNode.getFactorList() | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.ContentNode.getOpposite() | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.ContentNode.hashCode() | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.ContentNode.isConstant() | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.ContentNode.toString() | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.Factor.Factor(Operator, Node) | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.Factor.getCoefficient() | 3.0 | 2.0 | 3.0 | 3.0 |
| com.company.Factor.getFactorMap(Matcher) | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.Factor.getFactorNode() | 1.0 | 1.0 | 2.0 | 2.0 |
| com.company.Factor.getOperator() | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.Factor.getTriNode(Map) | 7.0 | 1.0 | 4.0 | 4.0 |
| com.company.Factor.normalizeFactor(String) | 8.0 | 4.0 | 1.0 | 8.0 |
| com.company.Factor.setOperator(Operator) | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.Inputer.getInputStrList() | 1.0 | 1.0 | 2.0 | 2.0 |
| com.company.Main.main(String[]) | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.Node.getLeftNode() | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.Node.getRightNode() | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.Node.setLeftNode(Node) | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.Node.setRightNode(Node) | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.NodeTree.build(List) | 12.0 | 11.0 | 11.0 | 11.0 |
| com.company.NodeTree.PreOptimizer.optimize() | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.NodeTree.setNode(Map, String) | 2.0 | 2.0 | 2.0 | 2.0 |
| com.company.Operator.getOpposite(Operator) | 1.0 | 3.0 | 1.0 | 3.0 |
| com.company.Operator.Operator(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.Operator.toString() | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.OperatorNode.clone() | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.OperatorNode.equals(Object) | 1.0 | 1.0 | 4.0 | 4.0 |
| com.company.OperatorNode.getFactorList() | 3.0 | 1.0 | 5.0 | 5.0 |
| com.company.OperatorNode.getOperator() | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.OperatorNode.getOppositeOperator() | 1.0 | 3.0 | 1.0 | 3.0 |
| com.company.OperatorNode.getResult() | 5.0 | 6.0 | 9.0 | 9.0 |
| com.company.OperatorNode.hashCode() | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.OperatorNode.OperatorNode(Operator) | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.OperatorNode.OperatorNode(Operator, Node, Node) | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.OperatorNode.toString() | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.OutputOptimizer.firstZeroOptimize(String) | 1.0 | 1.0 | 2.0 | 2.0 |
| com.company.OutputOptimizer.operatorOptimize(String) | 9.0 | 1.0 | 2.0 | 5.0 |
| com.company.OutputOptimizer.optimize(Node) | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.OutputOptimizer.powOneOptimize(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.PostOptimizer.bracketsOptimize(Node) | 11.0 | 1.0 | 6.0 | 6.0 |
| com.company.PostOptimizer.contentNegPosOptimize(Node) | 42.0 | 1.0 | 22.0 | 23.0 |
| com.company.PostOptimizer.getBracketBrokenNode(Node, Node, Node) | 2.0 | 2.0 | 2.0 | 2.0 |
| com.company.PostOptimizer.getBracketBrokenNode(Node, Position) | 1.0 | 3.0 | 3.0 | 3.0 |
| com.company.PostOptimizer.isAddNode(Node) | 1.0 | 1.0 | 2.0 | 2.0 |
| com.company.PostOptimizer.isEqual(Node, Node) | 1.0 | 1.0 | 3.0 | 3.0 |
| com.company.PostOptimizer.isMulNode(Node) | 1.0 | 1.0 | 2.0 | 2.0 |
| com.company.PostOptimizer.isPowNode(Node) | 1.0 | 1.0 | 2.0 | 2.0 |
| com.company.PostOptimizer.isSubNode(Node) | 1.0 | 1.0 | 2.0 | 2.0 |
| com.company.PostOptimizer.isZeroNode(Node) | 1.0 | 1.0 | 2.0 | 2.0 |
| com.company.PostOptimizer.mulZeroOptimize(Node) | 21.0 | 1.0 | 15.0 | 15.0 |
| com.company.PostOptimizer.needBreakBracket(Node, Node) | 2.0 | 1.0 | 3.0 | 3.0 |
| com.company.PostOptimizer.negOptimize(Node) | 14.0 | 1.0 | 7.0 | 7.0 |
| com.company.PostOptimizer.optimize(Node) | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.PostOptimizer.powOptimize(Node) | 24.0 | 5.0 | 9.0 | 9.0 |
| com.company.PostOptimizer.subEqualOptimize(Node) | 13.0 | 1.0 | 5.0 | 6.0 |
| com.company.TermMerger.canGetMergeResult(Node) | 1.0 | 1.0 | 4.0 | 4.0 |
| com.company.TermMerger.getMergeMap(Node) | 8.0 | 2.0 | 4.0 | 4.0 |
| com.company.TermMerger.merge(Node) | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.TermMerger.mergeResult(Node) | 10.0 | 1.0 | 4.0 | 4.0 |
| com.company.TermMerger.mergeSimilarities(Node) | 1.0 | 1.0 | 2.0 | 2.0 |
| com.company.TermMerger.PostMergeOptimizer.optimize(Node) | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.TermMerger.PostMergeOptimizer.optimizeMul(Node) | 20.0 | 1.0 | 9.0 | 9.0 |
| com.company.TermMerger.PostMergeOptimizer.optimizePow(Node) | 19.0 | 1.0 | 7.0 | 8.0 |
| com.company.TriNode.clone() | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.TriNode.equals(Object) | 1.0 | 1.0 | 3.0 | 3.0 |
| com.company.TriNode.getFactorList() | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.TriNode.hashCode() | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.TriNode.toString() | 3.0 | 1.0 | 3.0 | 3.0 |
| com.company.TriNode.TriNode(TriType, Node) | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.TriType.toString() | 0.0 | 1.0 | 1.0 | 1.0 |
| com.company.TriType.TriType(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Total | 255.0 | 107.0 | 209.0 | 226.0 |
| Average | 3.4 | 1.4266666666666667 | 2.7866666666666666 | 3.013333333333333 |
由表格可知,NodeTree.build()方法是基本复杂度最高的方法,该方法主要用于生成表达式树,该方法的代码如下:
public static Node build(List<String> exprs) throws Exception {
Node rootNode = null;
Map<String, Node> nodeMap = new HashMap<>();
for (String expr : exprs) {
String label;
Node node;
Matcher noneMatcher = Pattern.compile(NONE_EXP).matcher(expr);
Matcher addMatcher = Pattern.compile(ADD_EXP).matcher(expr);
Matcher subMatcher = Pattern.compile(SUB_EXP).matcher(expr);
Matcher posMatcher = Pattern.compile(POS_EXP).matcher(expr);
Matcher negMatcher = Pattern.compile(NEG_EXP).matcher(expr);
Matcher mulMatcher = Pattern.compile(MUL_EXP).matcher(expr);
Matcher powMatcher = Pattern.compile(POW_EXP).matcher(expr);
Matcher sinMatcher = Pattern.compile(SIN_EXP).matcher(expr);
Matcher cosMatcher = Pattern.compile(COS_EXP).matcher(expr);
if (noneMatcher.find()) {
label = noneMatcher.group("label");
node = new ContentNode(noneMatcher.group("rightNode"));
} else if (addMatcher.find()) {
label = addMatcher.group("label");
node = new OperatorNode(Operator.ADD,
setNode(nodeMap, addMatcher.group("leftNode")),
setNode(nodeMap, addMatcher.group("rightNode")));
} else if (subMatcher.find()) {
label = subMatcher.group("label");
node = new OperatorNode(Operator.SUB,
setNode(nodeMap, subMatcher.group("leftNode")),
setNode(nodeMap, subMatcher.group("rightNode")));
} else if (posMatcher.find()) {
label = posMatcher.group("label");
node = new OperatorNode(Operator.ADD, new ContentNode("0"),
setNode(nodeMap, posMatcher.group("rightNode")));
} else if (negMatcher.find()) {
label = negMatcher.group("label");
node = new OperatorNode(Operator.SUB, new ContentNode("0"),
setNode(nodeMap, negMatcher.group("rightNode")));
} else if (mulMatcher.find()) {
label = mulMatcher.group("label");
node = new OperatorNode(Operator.MUL,
setNode(nodeMap, mulMatcher.group("leftNode")),
setNode(nodeMap, mulMatcher.group("rightNode")));
} else if (powMatcher.find()) {
label = powMatcher.group("label");
node = new OperatorNode(Operator.POW,
setNode(nodeMap, powMatcher.group("leftNode")),
setNode(nodeMap, powMatcher.group("rightNode")));
} else if (sinMatcher.find()) {
label = sinMatcher.group("label");
node = new TriNode(TriType.SIN, setNode(nodeMap, sinMatcher.group("rightNode")));
} else if (cosMatcher.find()) {
label = cosMatcher.group("label");
node = new TriNode(TriType.COS, setNode(nodeMap, cosMatcher.group("rightNode")));
} else {
throw new Exception("Invalid Input!");
}
nodeMap.put(label, node);
rootNode = node;
}
return rootNode;
}
事实上,我认为我在处理该方法的时候做到了模块化。即每一个正则表达式进行匹配,然后输出对应的结果,然后方法逻辑也是一致的。我不认为该方法在阅读的时候有任何理解上的负担。本质上我认为模块化程度是很高的。
由表格可知,模块设计复杂度最高的方法是PostOptimizer.contentNegPosOptimize()方法,该方法用于优化含0的操作,比如:0-x -> -x; 0+x -> x; 0*x -> 0; x**0 -> 1。
该模块的代码如下:
private static Node contentNegPosOptimize(Node inputNode) {
Node node = inputNode;
boolean needAgain = true;
while (needAgain) {
if (node instanceof OperatorNode) {
node.setLeftNode(contentNegPosOptimize(node.getLeftNode()));
node.setRightNode(contentNegPosOptimize(node.getRightNode()));
if (isPowNode(node) && (isZeroNode(node.getLeftNode())
|| isZeroNode(node.getRightNode()))) {
node = new ContentNode("1");
} else if (isAddNode(node)) {
if (isZeroNode(node.getLeftNode()) && isZeroNode(node.getRightNode())) {
node = new ContentNode("0");
} else if (node.getLeftNode() instanceof ContentNode
&& isZeroNode(node.getRightNode())) {
node = node.getLeftNode().clone();
} else if (node.getRightNode() instanceof ContentNode
&& isZeroNode(node.getLeftNode())) {
node = node.getRightNode().clone();
} else {
needAgain = false;
}
} else if (isSubNode(node)) {
if (isZeroNode(node.getLeftNode()) && isZeroNode(node.getRightNode())) {
node = new ContentNode("0");
} else if (node.getLeftNode() instanceof ContentNode
&& isZeroNode(node.getRightNode())) {
node = ((ContentNode) node.getLeftNode()).getOpposite().clone();
} else if (node.getRightNode() instanceof ContentNode
&& isZeroNode(node.getLeftNode())) {
node = ((ContentNode) node.getRightNode()).getOpposite().clone();
} else {
needAgain = false;
}
} else if (isPowNode(node)) {
if (isZeroNode(node.getLeftNode())) {
node = new ContentNode("1");
} else {
needAgain = false;
}
} else {
needAgain = false;
}
} else if (node instanceof TriNode) {
node.setRightNode(contentNegPosOptimize(node.getRightNode()));
needAgain = false;
} else {
needAgain = false;
}
}
return node;
}
该方法引用的模块代码如下:
private static boolean isAddNode(Node node) {
return node instanceof OperatorNode &&
((OperatorNode) node).getOperator().equals(Operator.ADD);
}
private static boolean isSubNode(Node node) {
return node instanceof OperatorNode
&& ((OperatorNode) node).getOperator().equals(Operator.SUB);
}
private static boolean isMulNode(Node node) {
return node instanceof OperatorNode
&& ((OperatorNode) node).getOperator().equals(Operator.MUL);
}
private static boolean isPowNode(Node node) {
return node instanceof OperatorNode
&& ((OperatorNode) node).getOperator().equals(Operator.POW);
}
private static boolean isZeroNode(Node node) {
return node instanceof ContentNode && node.toString().equals("0");
}
很容易看得出来,所引用的模块,基本上都是条件语句的判断布尔值。修改其中引用的模块,并不对整体的程序结构产生变化。所以我认为该方法的模块设计复杂度较高是可以接受的。
而v(G)最高的方法,依然是PostOptimizer.contentNegPosOptimize()方法,这本身是因为涉及到加、减、乘、乘方四种运算,同时还涉及到OperatorNode、TriNode两种结点,同时涉及到0结点的判定。这就导致了条件判断的必然复杂。
但是我认为该方法在逻辑结构上还是清晰的,就是对OperatorNode和TriNode分别递归分析,然后对于加、减、乘、乘方四种运算和0结点分别判断。
所以我认为该方法很难做到进一步的优化。
类复杂度
| class | OCavg | OCmax | WMC |
|---|---|---|---|
| com.company.ContentNode | 1.0 | 1.0 | 9.0 |
| com.company.Factor | 2.25 | 5.0 | 18.0 |
| com.company.Inputer | 2.0 | 2.0 | 2.0 |
| com.company.Main | 1.0 | 1.0 | 1.0 |
| com.company.Node | 1.0 | 1.0 | 4.0 |
| com.company.NodeTree | 6.5 | 11.0 | 13.0 |
| com.company.NodeTree.PreOptimizer | 1.0 | 1.0 | 1.0 |
| com.company.Operator | 2.0 | 4.0 | 6.0 |
| com.company.OperatorNode | 2.4 | 7.0 | 24.0 |
| com.company.OutputOptimizer | 2.25 | 5.0 | 9.0 |
| com.company.Position | 0.0 | ||
| com.company.PostOptimizer | 3.875 | 15.0 | 62.0 |
| com.company.TermMerger | 2.4 | 2.0 | 12.0 |
| com.company.TermMerger.PostMergeOptimizer | 5.0 | 7.0 | 15.0 |
| com.company.TriNode | 1.1666666666666667 | 2.0 | 7.0 |
| com.company.TriType | 1.0 | 1.0 | 2.0 |
| Total | 185.0 | ||
| Average | 2.466666666666667 | 4.333333333333333 | 11.5625 |
由表格可知,平均方法复杂度最高的类是NodeTree类,根本原因还是NodeTree.build()方法比较复杂,且该类主要围绕着这个方法构造。
最高方法复杂度没有超过阈值。
而加权方法复杂度最高的类是PostOptimizer类。其流程控制代码如下:
public static Node optimize(Node inputNode) throws Exception {
Node node = inputNode;
node = subEqualOptimize(node);
node = contentNegPosOptimize(node);
node = powOptimize(node);
node = bracketsOptimize(node);
node = mulZeroOptimize(node);
node = negOptimize(node);
return node;
}
所有的方法都做到了模块化,该类内部几乎没有耦合。因此某些方法的复杂不影响整个类的运行。事实上,调试过程中,该类是很方便定位错误的。
该类WMC高,可能来源于设计的欠合理。我在设计这个类的时候,将其作为一个工具类,负责所有表达式树上的操作。因此方法比较多。但是因为每个方法基本做到了模块化,即使分布到别的类,本质上还是方法的聚合。
这样静态方法组成的类,或许看起来很不面向对象。
但是从调试和代码流程来说,我认为这样是可以接受的。事实上,该类的所有方法,都来源于根节点和左右结点的判断。如果强行放在Node类中,会显得很臃肿。
我希望我设计的Node类只负责Node类内部,Node类的子类也只负责它们的内部,保持类内部的简洁与一致。然后结点间的操作全部交给PostOptimizer类。由PostOptimizer类统一归一化操作。
关于完成作业过程中的思考,将放在在心得中。
分析bug
这一部分很尴尬,因为我几乎没有找到别人的bug,然后自己的作业,尤其是第一次作业,几乎是"面向评测机编程",导致第一次作业出现了18个bug,以至于不得不重构。
但是重构过程中确实意识到,设计的简洁、流程的规范,在客观上是可以减少bug出现的情况。
就比如neg, pos操作,一开始我的设计存在一个DummyNode类,本质上就是一个空集。比如f1 neg x,在我的表达式树中表现为
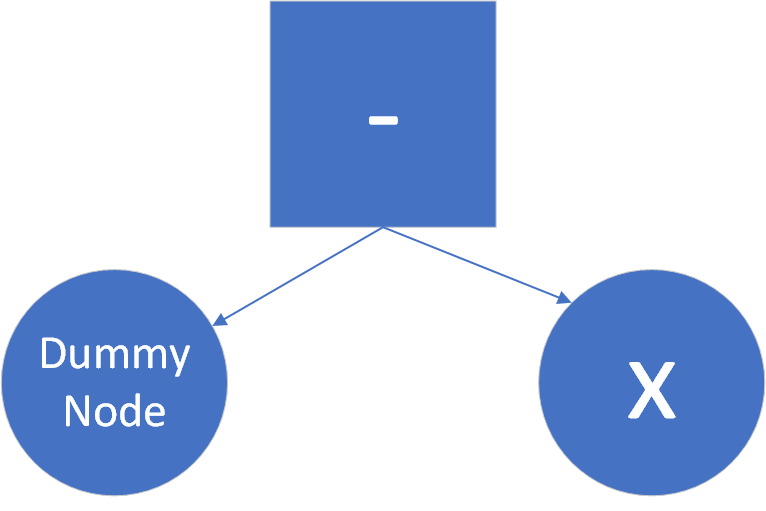
但是涉及到拆括号,就会出现如:DummyNode-(a+b) -> (DummyNode - a) + (DummyNode - b)
不断类推,就会生成越来越多的DummyNode,而DummyNode本身没有toString()方法,因此在输出字符串的过程中,产生了许多恶性bug。
在第一次重构中,我将DummyNode类去掉了,如:-x -> 0-x。在后续的优化中,把0去掉。
然后在拆括号中,绝不引入新的结点,只在原有的根节点、左右节点上进行替换、组合等操作,从而避免了一开始的生成越来越多的DummyNode的情况。
在重构过程中,不由得一会到了奥卡姆剃刀的威力:
如无必要,勿增实体!
事实上,之所以会出现这样问题,我想也是因为我在一开始设计的时候思路不清晰。这是一个很重要的问题:
面向对象思想中的“class”,真的是人们头脑中的“类”吗?
关于这部分的思考,我会放到心得中。
如何迭代?
首先本次作业,比较庆幸的是,在第一次作业重构之后,我的作业架构一直沿用了三次作业结束。一方面可能是因为我使用的是parse mode;另一方面,可能是因为我一开始使用的表达式树,本身可拓展性就比较高。
我认为,三次作业中,最重要的就是第一次作业。因为第一次作业设计好的架构,会影响到三次作业的迭代。
我认为我的设计比较好的点,有以下几个点:
使用表达式树作为逻辑结构:
输入给入的是字符串,那么能不能在字符串(以下从数据结构的角度称为“字符线性表”)的基础上进行操作呢?当然可以。逻辑数据结构本身没有任何问题,问题在于使用者使用的环境。
但是不管是逻辑结构,是选择表达式树,还是字符线性表,最重要一点,在于明确自己选择这个逻辑结构的理由。
字符线性表的特征就是线性,而且字符串有“正则表达式”这个强大的工具,可以有效地进行查找、替换等操作。但是没有良好的“递归”特性,而且java的正则表达式也不支持递归。那么遇到“括号匹配”这样的问题,还是要回到栈、树这样的有递归性的逻辑数据结构上。
而且另外一个很重要的问题,那就是输入的字符串,真的可以随便用正则表达式进行替换吗?
马克思主义中,有一条著名的世界观——“世界是相互联系的。”
实际上,可以把一个字符线性表看作一个高耦合的“小系统”。当你替换了任何一部分的时候,都会面临着整个系统的改变:不管是规则上,还是语句上。举例来说,你在表达式左右各加一个括号,那么这个表达式就变成了因子。从抽象的层次上来说,这是层次上的巨大变化。所以任何的小替换,都要考虑前前后后的影响,和影响背后的影响,甚至是影响背后的影响背后的影响......
为什么会这样呢?
本质上还是抽象的层次不够,从而导致的高耦合。
我们分析字符线性表,其实它不仅仅具有存储数据的功能,还负责了翻译语义的功能,当你对字符线性表进行“替换”操作,你改变的不仅仅是“数据”,你同时也改变了“语义”。这本身就是高耦合的结果。而“语义”的改变,本身就是混沌的,并非线性的——它只和“语法规则”有关。这样就会导致,如果你采用“字符线性表”的数据结构,你很难预测你的“替换”会造成什么样的“蝴蝶效应”。所以只能靠不断地添加限定、不断地debug找到漏洞再添加限定,从而将这个混沌系统进行拟合。
字符线性表本身是很直观的设计(毕竟输入直接给出的就是字符线性表),却也是很糟糕的设计。
而表达式树的优点,完全就是同字符线性表相反的。首先具有良好的递归特性;其次实现了数据存储与语义翻译的解耦。当我们构造表达式树的时候,我们不关心它的语义是什么样的——我们只要求它能按照优先级正确地计算。我们会单独设计模块来实现“语义翻译”。
另外,表达式树中的父子结点耦合程度低。这就导致我们在进行父子结点的操作过程中,只需要关心局部,而不必要在意整体。
综上,我们可以得出这样的一个结论——直观的建模,不一定就是合理的建模。
编程的本质,可以粗略地概括为通过建模来解决问题。而建模,本身就是认识论的问题。当我们能更合理地认识世界,我们就能更合理地改造世界。而谈到建模、认识这个问题,在“直观的建模,不一定就是合理的建模”的结论上,日心说取代地心说的案例是绕不开的。
地心说究竟错在哪,日心说又究竟对在哪,可不是这么一件太显然的事情——即便到了今天,大多数人也只知其一不知其二。
地球位于宇宙的中心,天体以永恒的秩序沿着不同的正圆轨道层层嵌套。白天,太阳从东方升起,从西边落下;晚上,星辰便绕着北极星旋转着。
地心说是多么的直观啊!可能也就没有地平说直观吧!
- 但是,地心说很快遇到了一个问题——很多天体运行的轨道圆心不在地球上。而且地球稳定地在世界的中心,那么为什么会有四季的变化呢?
于是托勒密天才地提出来新的规则——均轮:就是天体围绕地球运行时的大圆轨道,但是这个轨道的圆心不在地球上,也符合了天体距离变化带来的亮度变化,以及地球自转倾角带来的季节变化。
- 但是地心说很快遇到了另一个问题——很多行星经常在天空中改变了运动的方向和速度。比如著名的“火星逆行”。
于是托勒密又天才地提出了又一个新的规则——本轮:就是每个天体在环绕均轮转动的同时,还会环绕一个圆心在均轮上的小圆轨道运行,天体不同,本轮也不一样大,这同时解释了为何行星经常在天空中改变运动的方向和速度。
于是地心说从此以良好的精确性,统治了世界一千年。直到望远镜的出现。
- 有了望远镜,可以让天空被放大一些了。人们发现,本轮和均轮的理论和实际上的位置是稍微有一些偏差的。
于是天文学家,便沿用托勒密的思维——既然两个轮不够,那么我们多加几个轮就是了!
于是地心说的模型就变为了这样。
观测条件不断的提高,数据需要不断的修改,每次观测到了异常的天体,天文学家就加进去新的内旋螺线——直到我们的古人已经觉得,好烦啊,我们觉得这太扯淡了,世界不可能是这样的。
于是这个时候,哥白尼的革命性的“日心说”才走上了历史的舞台。
日心说最大的特征,便是将地球的公转与自转解耦。地球对于太阳的旋转作为公转,地球在自身倾角上的旋转作为自转。昼夜更替,这个变化的周期是“日”;四季更替,这个变化的周期是“年”——这都符合日心说的公转、自转概念。
于是大量的内旋螺线消失了,一切又变的那么简洁。
但是很远处的天体依然运动有误差。于是人们认识到了,可能太阳也不是宇宙的中心——太阳可能也有自转和公转!
于是人们发现,或许银河中心就是宇宙的中心!
但是随着观测水平的提升,人们发现银河中心作为参考点,还是有误差。
人们意识到,或许银河也不是宇宙的中心——银河系不是宇宙的全部!这才是距离现在不到一百年才得出的结论。
或许宇宙是没有中心的呢!——但是谁又知道这一条什么时候被推翻呢?
这和我们三次作业迭代是类似的。建立模型->新的需求->加入限定满足新的需求->又是新的需求->加入新的限定满足新的需求->再次新的需求->很难再加上新的限定了->重构->满足新的需求......
但是我们需要明确一点,那就是不要觉得一开始选择更好的模型就可以一劳永逸了。事实上需求是不断变化的,那么对模型的限定也会越来越严苛。毕竟,太阳也不是宇宙的中心。
所以总结一下,没有最好的建模,只有合适的建模。如果作业的要求,就是把输入的字符串,再倒序输出,那么没有比字符线性表更好的逻辑结构了——只需要满足数据存储就可以了;但是当需要翻译语义的时候,字符线性表就不合适了。
所以,当我们遇到了一个问题的时候,一定要分析好背后潜在的需求,尽量选择满足当前需求的尽可能解耦的模型。这是有利于我们未来的迭代的。
就好比,人们明知道“昼夜更替”和“四季更替”不是一回事,却依然选择耦合的地心说,加上“本轮”、“均轮”来限定;明知道数据存储和翻译语义不是一回事,却依然选择耦合的字符线性表,加上各种规则来限定——那么你自然而然地会比解耦的表达式树更早地进入“重构阶段”。
综上,直观的建模,不一定就是合理的建模;能更好地解耦需求的建模,才是更合理的建模。
在流程中多遍扫描,而不是将所有的操作耦合在一遍中:
这主要体现在我的PostOptimizer类的设计上。
这个类全是静态方法,可能会觉得这样的做法很不面向对象(笑),但是从设计的角度出发。我希望我设计的类是简洁的,只负责自身的属性和输出,而不要去关心两个子节点的情况。
另一方面,如果全部放在NodeTree这个类中,当然也没问题,甚至就可以将所有的静态方法转化为围绕跟结点的实例方法。但是我从设计出发,认为从流程的角度分析,我希望我所设计的模块只负责单一的没有耦合的功能。我不希望我设计的NodeTree类,既负责表达式树的生成,又要负责表达式树的修改。
所以我将所有的负责表达式树修改的方法全部作为静态方法,放入PostOptimizer类中,只需要传入根节点,就可以的得到修正后的表达式树。
现在回到正题,我在设计PostOptimizer类的过程中,采用了对表达式树多遍扫描,而不是将所有的修改操作耦合在一遍之中。
优势是显然的,比如说PostOptimizer类的流程,就如以下代码所示:
public static Node optimize(Node inputNode) throws Exception {
Node node = inputNode;
node = subEqualOptimize(node);
node = contentNegPosOptimize(node);
node = powOptimize(node);
node = bracketsOptimize(node);
node = mulZeroOptimize(node);
node = negOptimize(node);
return node;
}
流程清晰,降低耦合是比较好的特点。而且表达式树是单向的,所以在不断地迭代过程中不会发生循环遍历。我们以下面这个方法为例:
private static Node subEqualOptimize(Node inputNode) { Node node = inputNode; boolean needAgain = true; while (needAgain) { if (node instanceof OperatorNode) { node.setLeftNode(subEqualOptimize(node.getLeftNode())); node.setRightNode(subEqualOptimize(node.getRightNode())); if (isSubNode(node) && isEqual(node.getLeftNode(), node.getRightNode())) { node = new ContentNode("0"); } else { needAgain = false; } } else if (node instanceof TriNode) { node.setRightNode(subEqualOptimize(node.getRightNode())); needAgain = false; } else { needAgain = false; } } return node;}
首先我们不去关注needAgain这个布尔值的含义。该方法的流程很清晰:对表达式树后序遍历,如果该节点是OperatorNode,那么递归遍历各自的左右节点;如果该结点是TriNode,那么只遍历其右节点。遍历之后,若该结点的两个子节点相等,且该节点的符号位“-”,那么把该节点复制为常数0。
逻辑很简单,但是遇到了一个问题:我们在对数据结构进行修改的时候,需要注意,修改之后本身是否会代入新的影响。而needAgain的用处就是为了规避这个影响:若是改变了表达式树,那么需要重新遍历表达式树——直到某一次遍历不对表达式树更改。
解决了遍历过程中前后的耦合问题。那么解决不同的方法之间的引入新的耦合问题也是类似的,不再赘述。
心得与体会
这次作业,一开始很容易按照指导书去构造类,比如幂函数因子、三角函数因子、函数因子、表达式因子;然后上层在设计项;再上层再设计表达式......
这是我们一开始就很容易想到的设计,而且也是人头脑中很直观的设计。甚至我们可以做到什么代码还没怎么写,先啪啪把几个类先给罗列出来。似乎这样的设计很面向对象——“一切皆对象”嘛!。但是——
面向对象思想中的“class”,真的是人们头脑中的“类”吗?
我们似乎总是会潜意识中觉得“一切皆对象”,然后以此去设计继承结构,比如说:家禽继承鸟类,鸡继承家禽,公鸡继承鸡,小公鸡继承公鸡......
但是,没有真正的抓到一类事物(在当前应用场景下)的根本,就去设计继承结构,是必不会有所得的。
我们是要根据需求来设计我们的类,举例来说,我要研究种族歧视,那么必然以肤色分类;换到法医学,那就按死因分类;生物学呢,则搞门科目属种……
但是实际操作过程中,我们会因为这样的设计遇到很多问题:
问题来了。。。就比如说继承。。。
一个正方形,按照“正方形是特殊的长方形”的人类思维习惯,那么正方形应该继承长方形。。。
但是你真继承了,事情就来了。那么我如果临时需要正方形的上下两个边拉长,正方形怎么做呢?正方形根本做不了。。。所以一般人的做法就是销毁这个正方形,新建一个普遍意义的长方形。。。因为你知道正方形能转化为长方形,但是编译器很难理解你这是什么操作。
那么你这个继承的意义是什么?就为了表明长=宽的状态吗?那你根本就不需要新建“正方形”这个类,直接令长=宽就可以了。
所以“正方形”继承“长方形”就是很垃圾的类的设计,除了告诉你这是“正方形”,再没有别的用处。
但是这很符合人的思维习惯。
所以我们真的很需要明确,oo里的类,真的可以类比为人类思维里的类吗?
抽象的唯一目的,就是为了抽象出共性,这个共性是指计算机处理数据的共性,而不是人类思维的共性。
但是人类思维看来,正方形就应当是继承矩形。
问题来了,现在你有一个容器存储的是正方形。如果将容器中某一个正方形的某一对边长改一下,那么按照人类思维,这就是矩形了。
于是你调用了父类矩形的setLength()的方法,就是要强行length和width不相等。可是你真的这么做了,编译器会报错。首先正方形的边长必须四个边都相等。
于是你不管,你就是要强行向上转型,你就是想让编译器知道,我就是要把正方形转成一个矩形。然后编译器又报错,子类引用不能指向父类对象。
OK,你服了。你new了一个矩形,把正方形的属性放到矩形中,然后再更改。你编译器不会向上转型,我程序员手动给你向上转型!
这次矩形没有问题了。但是编译器还是报错了——容器只能存正方形,不能存长方形。
好的,这次你新建了一个矩形容器,把这个矩形挑了出来放了进去。手动放的哦。
但是问题来了,就是会有正方形要变成矩形的业务需求,总不能一个个手动取出来,变成长方形,再放进矩形容器吧!
于是你取消了正方形容器,改为了矩形容器。终于没有问题了,长方形正方形都可以放了。
但是问题又来了,那么矩形如果修改后边长相等,那么它还是矩形,是无法自动转型为正方形的。。。
所以这样垃圾的类的继承究竟是为了什么呢?只是为了满足人类的抽象思维吗
面向对象语言,继承只有一个目的,那就是复用代码。而不是为了满足人类的抽象思维。
问题来了,为了你的人类思维而这样面向对象,这值得吗?
以上这两段,来源于知乎中我和别人的一次讨论。最后大v做出了这样的总结:
造成这颗炸弹的根本原因是,面向对象中的“类”,和我们日常语言乃至数学语言中的“类”根本就不是一码事。
面向对象中的“类”,意思是“接口上兼容的一系列对象”,关注的只不过是接口的兼容性而已(可搜索 里氏代换);关键放在“可一视同仁的处理”上(学术上叫is-a)。
显然,这个定义完全是且只是为了应付归一化的需要。
这个定义经常和我们日常对话中提到的类概念上重合;但,如前所述,根本上却彻彻底底是八杆子打不着的两码事。
就着生活经验滥用“类”这个术语,甚至依靠这种粗浅认识去做设计,必然会导致出现各种各样的偏差。这种设计实质上就是在胡说八道。
就着这种胡说八道来写程序——有人觉得这种人能有好结果吗?
——但,几乎所有的面向对象语言、差不多所有的面向对象方法论,却就是在鼓励大家都这么做,完全没有意识到它们的理论基础有多么的不牢靠。
——如此作死,焉能不死?!
——你还敢说面向对象无害吗?
——在真正明白何谓封装、何谓归一化之前,每一次写下class,就在错误的道路上又多走了一步。
——设计真正需要关注的核心其实很简单,就是封装和归一化。一个项目开始的时候,“class”写的越早,就离这个核心越远。
——过去鼓吹的各种面向对象方法论、甚至某些语言本身,恰恰正是在怂恿甚至逼迫开发者尽可能早、尽可能多的写class。
作者:invalid s
链接:https://www.zhihu.com/question/20275578/answer/26577791
来源:知乎
所以我们应当明确,我们为了什么而设计类?面向对象到底有什么好处?
我们仔细想想,不难得到这样的结论:封装可(通过固定接口而)应付需求变更、归一化可简化(类的使用者的)设计:以上,就是面向对象最最基本的好处。
事实上,我们设计的类,往往就是直观上——我感觉。所以我们会做出这样的设计——游戏设计出“英雄类”、“装备类”,然后将装备绑定在英雄身上。但是遇到lol这样的复杂的游戏,这样面向对象的设计方法真的合适吗?
想想看,假如让那些面向对象原教旨主义者来设计,会出现什么情况:
定义一个基类叫技能;然后一个继承类叫法术技能,另一个叫物理技能;然后神圣法术从法术技能继承,疾病法术也从法术技能继承;由于圣骑士一个技能同时具备物理和法术两种效果,于是必须多重继承神圣法术和物理技能;多重继承太危险,于是不得不把神圣法术搞成接口类,引入接口继承甚至带实现的纯虚函数等等高端概念;然后,活该枪毙的暴雪设计师又想出了让某个技能同时对目标加上神圣持续伤害效果的奇怪点子——于是不得不再加个继承层次,使得神圣法术是神圣持续伤害法术的子集:仅立刻造成一次持续伤害的DOT(damage of time)技能……
那么,点一个天赋,一个技能就会有dot,否则就没有怎么办?
设计模式是灵丹妙药,不是吗 _
等到把这所有几千个技能全部搞定,起码也是一个数万个类、几十层的恐怖继承树,并且会用完23个设计模式(甚至再发明几个新模式出来,我也不会感到奇怪),精巧复杂到没有任何人愿意去碰它。
但,请注意,天杀的暴雪设计师,在最开始的设计方案里规定DOT不能暴击;后来又添加约定说某某某职业的某个dot可以暴击;另一个职业的某个dot在点天赋后可暴击;至于死亡骑士,在他穿了T9套装中的其中四件装备时,他的某个瘟疫类型的dot可以暴击——但另一个瘟疫dot永远不能暴击。
嗯嗯嗯,太好解决了——这不就是策略模式吗?
好吧,你再填几十几百个类体系,然后把旧的几十层继承树中的数万个类一个个都策略化吧。反正不是我在维护……
哎呀不好,那个枪毙了几百次都还没死的暴雪设计师又出馊主意了,他要求:当死亡骑士点了邪恶系的某个天赋时,不光给他增加一个新的dot、并且在这个新dot的存在期间,还要保护他的两个dot性疾病和1个debuf性疾病不被驱散!
继续补充:在WLK里面,那个脑袋都被子弹打成筛子了的暴雪设计师又跳出来了,用他满是漏洞的脑子出了个该杀的主意:他要求添加载具概念,当玩家坐上载具时,临时删除他的所有技能,替换为载具的技能;或者当他坐在特定载具的特定位置时,防止他受到任何伤害、并且允许他释放自己的所有技能!
更该死的是,他要求,一些技能本来不允许在移动中施放;但现在,当玩家坐在载具上某个位置时,要临时允许他移动施法!还有,为了平衡某个野外战场,他还要求,在某方人数较少时,临时根据提高他们的生命值和所有技能的攻击力和治疗能力——这个改变必须根据进入战场的人数实时进行;在一方连续在某个战场失败时,同样要给他们一定补偿!
嗯嗯,看看这些不断改变的刁钻需求吧,如果没有面向对象,没有以策略模式为首的28个设计模式(我有理由相信你们需要至少28个设计模式而不是23个)的英明领导,我们这些没接触过大项目、不懂面向对象的傻B们,就是哭的拿眼泪把长城溶解掉都没办法吧?——我当然知道搭建长城的材料极难溶与水。
可怜的瞎子,你们的鱼汤很鲜吧?
作者:invalid s
链接:https://www.zhihu.com/question/20275578/answer/26577791
来源:知乎
所以我们为什么要面向对象呢?难道不是——
Why object-oriented coding (in some words) is piece of sxxt?
首先我们先看几个著名人物的论断:
Object-oriented programming is an exceptionally bad idea which could only have originated in California.
--Dijistra
The ‘disaster’ that OOP has become, compared to its promise.
--Ilya Suzdalnitski
--Joe Armstrong
很多大佬似乎对“面向对象”本身具有“独特”的看法(笑)。
我们回顾一下面向对象编程的起源。一般说来,OOP起源于是Alan Kay的SmallTalk,但是Kay似乎对于现在OOP的现状不是很满意:
Smalltalk is not only NOT its syntax or the class library, it is not even about classes. I'm sorry that I long ago coined the term "objects" for this topic because it gets many people to focus on the lesser idea.
The big idea is "messaging" -- that is what the kernal of Smalltalk/Squeak is all about ...
在Alan Kay看来,最重要的不是class,而是通信。所以如果以通信为目的的话,那么自然而然信息就是接口,那么将计算实体的内部、状态封装起来便是自然而然的事情。这或许就是OOP封装的起源。
从起源来入手,我们可以思考一下FOP为什么会失败。FOP是紧耦合的,需求变动的话,那么自然而然需要修改原有的代码。但是这带来的问题,便是修改局部的代码,整体的代码都会受到影响。
换句话说,OOP的根本目的,是为了在尽可能少变动原有代码的基础上,完成需求。
所以我们也不难理解,为什么OOP最重要的原则是OCP(开闭原则)。
遵循开闭原则设计出的模块具有两个主要特征:
(1)对于扩展是开放的(Open for extension)。这意味着模块的行为是可以扩展的。当应用的需求改变时,我们可以对模块进行扩展,使其具有满足那些改变的新行为。也就是说,我们可以改变模块的功能。
(2)对于修改是关闭的(Closed for modification)。对模块行为进行扩展时,不必改动模块的源代码或者二进制代码。模块的二进制可执行版本,无论是可链接的库、DLL或者.EXE文件,都无需改动。
所以举例来讲,为什么OOP提倡用多态取代switch呢?
1 - 违反「开放扩展」原则。假如别人的switch调用了你的代码,你的代码要扩展,就必须在别人的代码里,人工找出每一个调用你代码的switch,然后把你新的case加进去。
2 - 违反「封闭修改」原则。这是说,被switch调用的逻辑可能会因为过于紧密的耦合,而无法在不碰switch的情况下进行修改。
所以我们很容易理解,面向对象诞生,是为了解决大规模编程的问题。本身没有什么好坏之分。
但是在使用上的确是有好坏之分的。
现在,随着长期以来的技术环境、编程语言、一些工具的推广、培训和教育都大大的过分乐观的强调了面向对象编程本身可以带来的好处。以至于很多学习编程的人都深深的相信“只要用了面向对象编程(以及基于其基础之上的的一系列设计模式、规范、工具、框架),就能得到非常容易维护、可以复用、明晰可理解的代码“。
仿佛面向对象,就意味着简单、意味着直观。
但是,真的是这样吗?
OOP好不好用,我们学习几个设计模式,学习几个封装方法,学习几个接口定义,就能明白OO的精髓吗?难道不是在实践中大量的大规模开发才会理解吗?只用几个sample code来学习,并且简化问题本身,突出代码设计的“模式”,这真的能体会到面向对象的精髓吗?
比如说接口,什么是好的接口?好的接口应该是能够隐藏极大的复杂度的,可能不是很多factory、builder这样,对于调用接口去解决问题毫无意义的抽象。
比如说继承,继承的确能复用代码,但是本身也是强耦合。当你尝试着去继承,你就必须去明确父类代码是怎么写的,难道这个就比复制粘贴更简单了吗?你代码是少写了几行,但是整个类的复杂性并没有降低,甚至因为继承,你的子类的可读性也降低了。这是抽象吗?根本不是。你并没有把复杂性封装起来,你只不过是把复杂性没有体现在你的子类里罢了。
OOP究竟想干什么?
我们知道,OOP的精髓在于,封装、继承、多态。换句话说,即是归一化,是是“无需区别就能处理接口兼容的一系列对象”。
换句话说,面向对象的精髓,在于架构设计,在于战略层面,而不是“使用继承就可以复用代码”这样的战术层面的东西。并不是用C++、Java、Python等面向对象语言开发,你的程序就是面向对象的了。事实上Linux内核完全是C开发,一样用虚函数表实现了面向对象思想。
事实上,面向对象,重点在于“programming”,而不是"coding"。
就比如我们熟悉的继承,本质上是想让我们一定要“实现继承”吗?难道是想让我们写出强耦合的、软件复杂度失控的垃圾吗?难道“接口继承”就是没有意义、华而不实的东西吗?
为什么业界会有这样的忠告——“使用组合而不是继承”。
所以在学习面向对象编程中,我们真正需要看重的是归一化。而我们封装的目的,就是为了每一层各司其职。最终实现“通过合理模块化而灵活应对需求变更”。
所以,那篇知乎回答是这么总结的:
1、什么是真正的封装?
——回答我,封装是不是等于“把不想让别人看到、以后可能修改的东西用private隐藏起来”?
显然不是。
如果功能得不到满足、或者未曾预料到真正发生的需求变更,那么你怎么把一个成员变量/函数放到private里面的,将来就必须怎么把它挪出来。
你越瞎搞,越去搞某些华而不实的“灵活性”——比如某种设计模式——真正的需求来临时,你要动的地方就越多。
真正的封装是,经过深入的思考,做出良好的抽象,给出“完整且最小”的接口,并使得内部细节可以对外透明(注意:对外透明的意思是,外部调用者可以顺利的得到自己想要的任何功能,完全意识不到内部细节的存在;而不是外部调用者为了完成某个功能、却被碍手碍脚的private声明弄得火冒三丈;最终只能通过怪异、复杂甚至奇葩的机制,才能更改他必须关注的细节——而且这种访问往往被实现的如此复杂,以至于稍不注意就会酿成大祸)。
一个设计,只有达到了这个高度,才能真正做到所谓的“封装性”,才能真正杜绝对内部细节的访问。
否则,生硬放进private里面的东西,最后还得生硬的被拖出来——当然,这种东西经常会被美化成“访问函数”之类渣渣(不是说访问函数是渣渣,而是说因为设计不良、不得不以访问函数之类玩意儿在封装上到处挖洞洞这种行为是渣渣)。
2、接口继承真正的好处是什么?是用了继承就显得比较高大上吗?
显然不是。
接口继承没有任何好处。它只是声明某些对象在某些场景下,可以用归一化的方式处理而已。
换句话说,如果不存在“需要不加区分的处理类似的一系列对象”的场合,那么继承不过是在装X罢了。
了解了如上两点,那么,很显然:
1、如果你没有做出好的抽象、甚至完全不知道需要做好的抽象就忙着去“封装”,那么你只是在“封”和“装”而已。
这种“封”和“装”的行为只会制造累赘和虚假的承诺;这些累赘以及必然会变卦的承诺,必然会为未来的维护带来更多的麻烦,甚至拖垮整个项目。
正是这种累赘和虚假的承诺的拖累,而不是为了应付“需求改变”所必需的“灵活性”,才是大多数面向对象项目代码量暴增的元凶。
2、没有真正的抓到一类事物(在当前应用场景下)的根本,就去设计继承结构,是必不会有所得的。
不仅如此,请注意我强调了在当前应用场景下。
这是因为,分类是一个极其主观的东西,不存在普适的分类法。
举例来说,我要研究种族歧视,那么必然以肤色分类;换到法医学,那就按死因分类;生物学呢,则搞门科目属种……
想象下,需求是“时尚女装”,你却按“窒息死亡/溺水死亡/中毒死亡之体征”来了个分类……你说后面这软件还能写吗?
作者:invalid s
链接:https://www.zhihu.com/question/20275578/answer/26577791
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
总结:面向对象的好处实际就这么两点。
一是通过封装明确定义了何谓接口、何谓接口内部实现、何谓接口的外部调用者,使得大家各司其职,不得越界;
二是通过继承+多态这种内置机制,在语言的层面支持归一化的设计,并使得内行可以从代码本身看到这个设计——但,注意仅仅只是支持归一化的设计。不懂如何做出这种设计的外行仍然不可能从瞎胡闹的设计中得到任何好处。
作者:invalid s
链接:https://www.zhihu.com/question/20275578/answer/26577791
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号