

BUAA_OO_2020_第一单元总结
OO第一单元作业主题为表达式求导,主要学习目标是熟悉面向对象的思想以及学会使用类来进行数据的管理。
一、 程序结构分析
(1)第一次作业
在做第一次作业时对于面向对象的理解还不足,也没有体会到程序延展性的重要意义。因此构筑得并不好,如下图所示,用一个类Parser完成了读入,求导和写出,耦合性太大,在第二次作业中代码无法复用,只能重构。读入方式为用一个一次匹配一项的小正则表达式循环匹配整个大正则表达式,存储上使用Map,key为次数,value为系数,方便化简。读入和存储的实现虽然适用于这次作业且较为简单,但无法用到之后的作业,必须重构。
这次作业给了我很好的教训,让我意识到了在设计的时候需要走一步看三步,多多思考可能出现的需求,尽可能减少程序的耦合。
构筑与复杂度分析如下图所示。
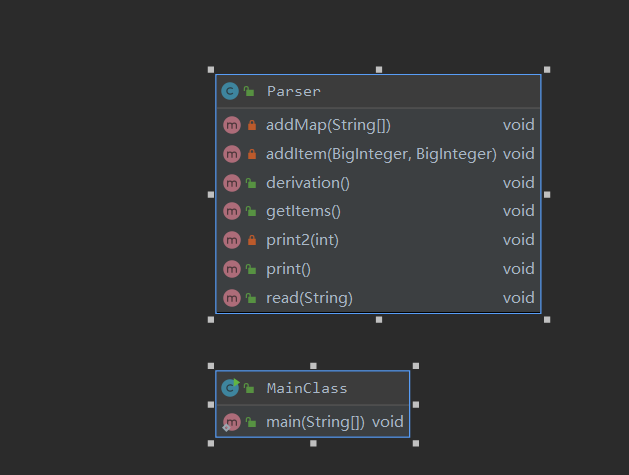
| Parser.read(String) | 1.0 | 2.0 | 2.0 |
| Parser.print2(int) | 3.0 | 7.0 | 10.0 |
| Parser.print() | 3.0 | 7.0 | 7.0 |
| Parser.Parser() | 1.0 | 1.0 | 1.0 |
| Parser.getItems() | 1.0 | 2.0 | 2.0 |
| Parser.derivation() | 1.0 | 4.0 | 4.0 |
| Parser.addMap(String[]) | 1.0 | 10.0 | 15.0 |
| Parser.addItem(BigInteger,BigInteger) | 4.0 | 4.0 | 4.0 |
| MainClass.main(String[]) | 1.0 | 4.0 | 4.0 |
| Total | 16.0 | 41.0 | 49.0 |
| Average | 1.7777777777777777 | 4.555555555555555 | 5.444444444444445 |
(2)第二次作业
在对第二次作业设计时,我吸取了上次的教训,考虑到了第三次作业中可能出现的新的需求。我考虑到了除法,表达式嵌套的出现情况,因此希望在第二次作业就实现能够读入括号嵌套的表达式的功能。先尝试了第一次作业的一次读一项的正则表达式读入方式,但需要对输入的原表达式进行复杂的预处理,否则会有爆栈的风险,之后又想到了用状态机的方式读入,根据下一个expect的小字符串切换状态,这样子的结构方便扩展功能(加入新的状态就能完成新功能,而修改正则表达式则很繁琐,担心出错),debug(正则表达式容易出现细节上的疏漏,而状态机读入分层次检查,很好debug),也非常好写。
在存储上,我本想在第二次作业时就用Factor接口,并用幂函数,常数,三角函数等等类来实现这一接口的结构,但由于探索读入的实现花费太长时间,担心之后的优化没有时间做好,因此使用了更容易实现和优化的方式:用Item类存储各类函数的次数,每个Exp对象含有一个ItemList,体现加法关系。
在第二次的设计中,我吸取了第一次的教训,扩展性地实现了第二次作业的读入部分,但仍然有做得不足的地方,导致了我在第三次作业中读入部分仍然有一部分需要重构,花费了不少的时间,具体原因请往后看。构筑与复杂度分析如下图所示。
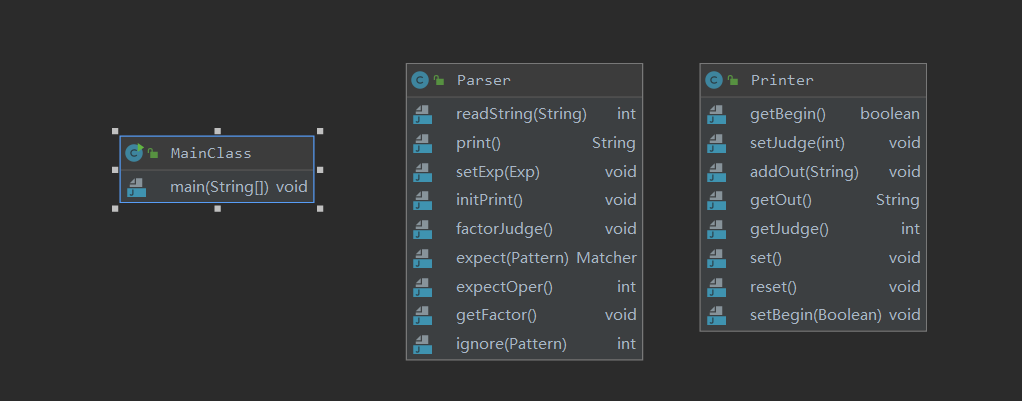
| Printer.setJudge(int) | 1.0 | 1.0 | 2.0 |
| Printer.setBegin(Boolean) | 1.0 | 1.0 | 1.0 |
| Printer.set() | 1.0 | 1.0 | 2.0 |
| Printer.reset() | 1.0 | 1.0 | 1.0 |
| Printer.getOut() | 1.0 | 1.0 | 1.0 |
| Printer.getJudge() | 1.0 | 1.0 | 1.0 |
| Printer.getBegin() | 1.0 | 1.0 | 1.0 |
| Printer.addOut(String) | 1.0 | 1.0 | 1.0 |
| Parser.setExp(Exp) | 1.0 | 1.0 | 1.0 |
| Item.getCoef() | 1.0 | 1.0 | 1.0 |
| Item.diff() | 1.0 | 1.0 | 1.0 |
| Item.addXIndex(BigInteger) | 1.0 | 1.0 | 1.0 |
| Item.addSinIndex(BigInteger) | 1.0 | 1.0 | 1.0 |
| Item.addCosIndex(BigInteger) | 1.0 | 1.0 | 1.0 |
| Item.addCoef(BigInteger) | 1.0 | 1.0 | 1.0 |
| Exp.simplifyPlus() | 3.0 | 3.0 | 3.0 |
| Exp.simplify() | 3.0 | 3.0 | 3.0 |
| Exp.setItems(List) | 1.0 | 1.0 | 1.0 |
| Exp.pre() | 1.0 | 7.0 | 7.0 |
| Exp.positiveJudge() | 1.0 | 2.0 | 2.0 |
| Exp.popZero() | 1.0 | 3.0 | 3.0 |
| Exp.getItems() | 1.0 | 1.0 | 1.0 |
| Exp.getIt() | 1.0 | 1.0 | 1.0 |
| Exp.diff() | 1.0 | 2.0 | 2.0 |
| Exp.copy(List) | 1.0 | 2.0 | 2.0 |
| Exp.addItem(Item) | 4.0 | 3.0 | 4.0 |
| Total | 69.0 | 121.0 | 137.0 |
| Average | 1.4375 | 2.5208333333333335 | 2.8541666666666665 |
(3)第三次作业
第三次作业的要求与我之前预测的存在一点出入,然后就是这一点区别使得我只能把之前的构筑重构很大一部分:sin中套入的是Exp因子,也就是说sin(x+1)不合法(而我之前按其合法构筑)。由于未想到这一点,在sin与cos的读入和exp的读入上必须重构,现在反思来看其实还是当时的延展性做得不够好,因为我重构之后的方式能够支持这两种情况,显然应该在第二次作业时采用这种方式,只能说想得还不够周到,细致。
在存储上,我实现了Factor接口,并用幂函数,常数,三角函数等等类来实现这一接口的结构。然而在设计的过程中,我有一个地方想着偷懒:不实现Constant类,转为为Item类(即项类)添加一个BigInteger成员coef,如此一来在做合并同类项时大大方便了,刚想到这一点时我还非常得意,可是殊不知这一设计在之后带给了我灾难性的后果。不实现Constant类确实在合并时较为方便,但这一蝇头小利却破坏了程序结构上的统一性:也即Constant与幂函数,三角函数等等都是通过Parser读入的,同样在之后的求导,化简,优化中也要参与,尤其是在化简中,常数化简做得好不好影响巨大,假如我不实现Constant类,那么我必须在做这些步骤的时候每次都要特判Constant情况。还有,在读入以sin(1)为例的,常数为三角函数中的因子的情况时,由于我的SinFunc类中的成员变量的类型为接口Factor,若不实现Constant会造成矛盾。发现上述缺点和矛盾时我已经基本实现完了一部分求导和化简,不禁后悔万分。
当时还只是在周四上午,我纠结于重构与硬着头皮打补丁之间。这时我又犯下第二个错误:我选择了硬着头皮打补丁,因为假如重构,很多关键方法都要重写,花费大量时间,而且我很担心在修改过程中有一些细节我没有把握到位,出现大量Bug。然而,正是这一决定,导致原本我设计好的能在半天之内实现的化简和优化部分变得非常难以实现,在写每一步时我都如履薄冰,因为我十分担心Constant所导致的问题,我必须时时考虑与Constant的各种边界情况,并且打了很多的补丁,让程序结构变得极为丑陋,也使得之前的设计失去了意义。我最终花了两天时间才实现完最后的部分,那时已经是周六中午了,在这一过程中我老是在纠结到底要不要重构Constant,一切推到重来,但是最终还是放弃了,整个过程非常痛苦。
现在看来,第三次作业绝对让我受益匪浅,一是设计时不要因为蝇头小利而抛弃程序的统一性,完整性,之后很可能会付出加倍的代价,付出更多的时间,二是浪子回头绝对不晚,在一个已经失败的构筑上继续打补丁难上加难,而且在实现完后也十分心虚,担心是否还有未考虑到的边界情况。
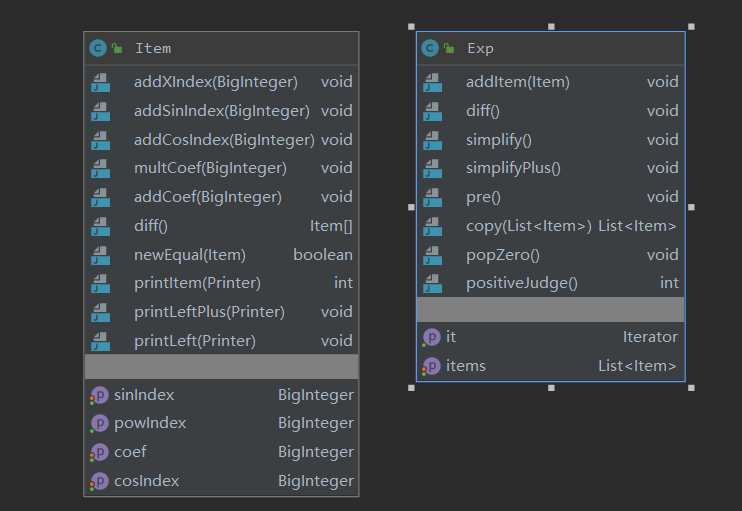
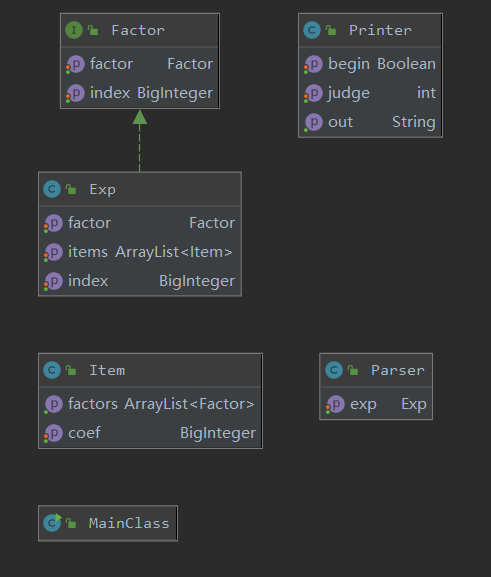
具体构筑如下图所示。(注:最终实现的Constant类只是一个壳子,没有实际作用,其具体作用由打在整个程序中的繁杂的补丁实现,耦合度极高)
Factor接口包含主要的求导diff方法和print()输出方法,实现递归调用。化简主要在读入的过程中进行,当检测到Exp因子中只有一个因子时打开括号,只有一个项,但项中有多个因子的时候,判断打开括号是否能让字符串更短,视情况来打开括号。
Parser类实现状态机式读入过程,Printer实现写出功能,其中Item不实现Factor,代表一个项,含有ArrayList<Factor> 成员。
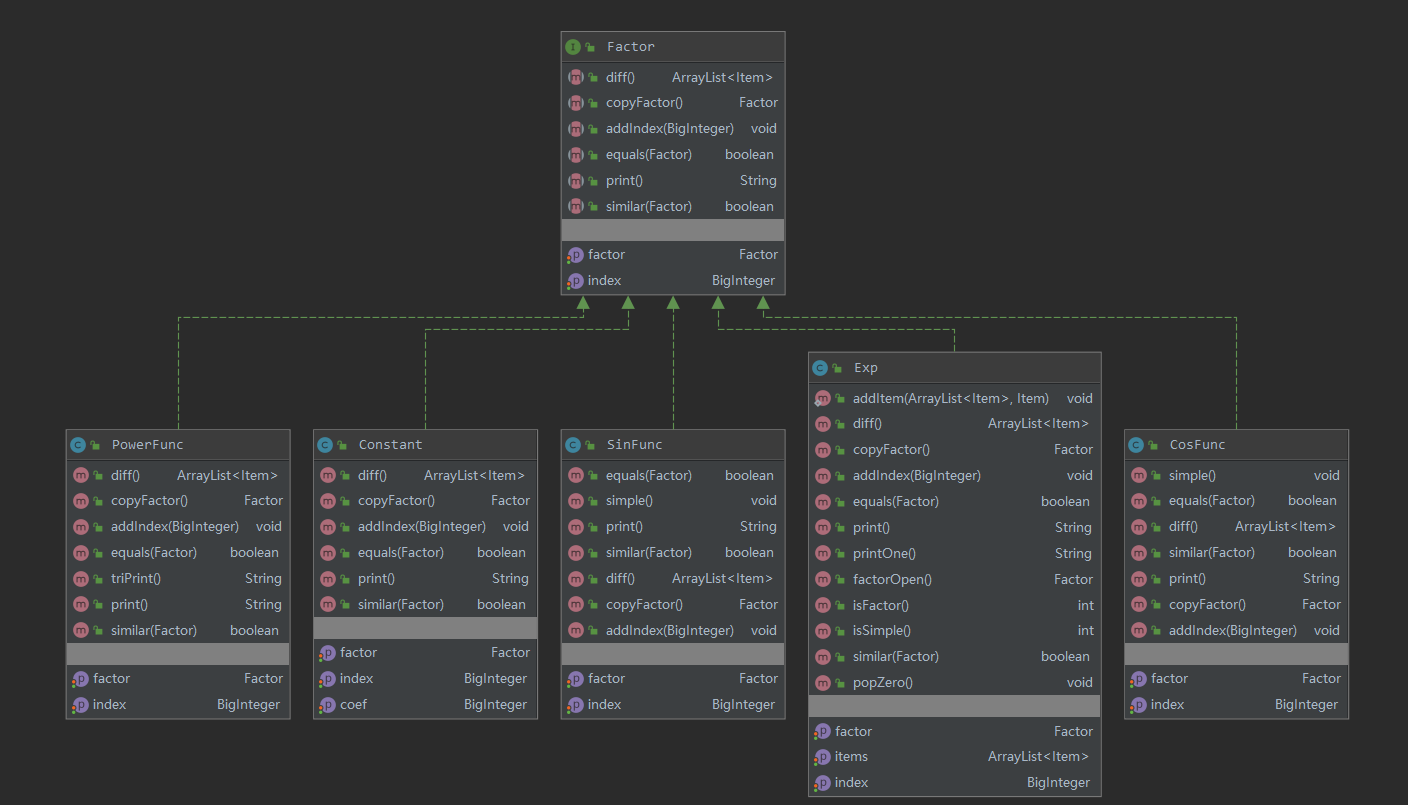
| SinFunc.SinFunc(BigInteger,Factor) | 1.0 | 1.0 | 1.0 |
| SinFunc.simple() | 2.0 | 4.0 | 5.0 |
| SinFunc.similar(Factor) | 3.0 | 2.0 | 3.0 |
| SinFunc.setIndex(BigInteger) | 1.0 | 1.0 | 1.0 |
| SinFunc.setFactor(Factor) | 1.0 | 1.0 | 1.0 |
| SinFunc.print() | 6.0 | 6.0 | 6.0 |
| SinFunc.getIndex() | 1.0 | 1.0 | 1.0 |
| CosFunc.setIndex(BigInteger) | 1.0 | 1.0 | 1.0 |
| CosFunc.setFactor(Factor) | 1.0 | 1.0 | 1.0 |
| CosFunc.print() | 6.0 | 6.0 | 6.0 |
| CosFunc99.getIndex() | 1.0 | 1.0 | 1.0 |
| CosFunc.getFactor() | 1.0 | 1.0 | 1.0 |
| CosFunc.equals(Factor) | 4.0 | 3.0 | 4.0 |
| CosFunc.diff() | 3.0 | 3.0 | 4.0 |
| CosFunc.CosFunc(BigInteger,Factor) | 1.0 | 1.0 | 1.0 |
| CosFunc.copyFactor() | 1.0 | 1.0 | 1.0 |
| CosFunc.addIndex(BigInteger) | 1.0 | 1.0 | 1.0 |
| Constant.similar(Factor) | 1.0 | 1.0 | 1.0 |
| Constant.setIndex(BigInteger) | 1.0 | 1.0 | 1.0 |
| Constant.setFactor(Factor) | 1.0 | 1.0 | 1.0 |
| Constant.setCoef(BigInteger) | 1.0 | 1.0 | 1.0 |
| Constant.print() | 1.0 | 1.0 | 1.0 |
| Constant.getIndex() | 1.0 | 1.0 | 1.0 |
| Constant.getFactor() | 1.0 | 1.0 | 1.0 |
| Constant.getCoef() | 1.0 | 1.0 | 1.0 |
| Constant.equals(Factor) | 3.0 | 2.0 | 3.0 |
| Constant.diff() | 1.0 | 1.0 | 1.0 |
| Constant.copyFactor() | 1.0 | 1.0 | 1.0 |
| Constant.Constant(BigInteger) | 1.0 | 1.0 | 1.0 |
| Constant.addIndex(BigInteger) | 1.0 | 1.0 | 1.0 |
| Total | 218.0 | 260.0 | 312.0 |
| Average | 2.0 | 2.385321100917431 | 2.8623853211009176 |
二、性能优化分析
(1)第一次作业
性能优化很简单,只有合并同类项与一些输出细节,这些输出细节可以同理用到之后的作业,例如第一项省略正号。最终性能分也拿满了。
(2) 第二次作业
在第一次作业的基础上还加入了三角函数的化简,我采用了利用sin方+cos方等于1这一式子化简的方式。即不断尝试,判断作代换并合并是否能让输出变短,若变短则成功化简,假如成功化简则又从第一项开始遍历。这一方法需要注意的是有部分式子需要两次使用sin方+cos方等于1这一式子才能化简得更短,第一次使用时会变长,导致方法失效。其实仍然有可以改进的地方,但由于担心超时等问题,在补充这一实现后作为最终版提交,拿到97分的总分。
(3)第三次作业
在实现一二次作业的化简的基础上,第三次作业的化简主要集中在对Exp的化简上,即尽可能地去掉能让式子变得更短的。在最初设计时,希望在求导后输出前进行这一化简过程,但发现极为繁琐,因为这是一个递归遍历的过程,而困难在于sin内部的exp因子具有特殊性,部分时候不能舍去括号,否则会WF,而每个Exp对象又无法知道自己所在的位置,除非给它加上一个成员变量,但这样实在是不够优雅,最终想到在读入的时候特化读入sin内部的exp因子,完成了这一化简,最终拿到99分的总分。
三、程序Bug分析
在强测,互测中,我的三次作业均未检测出任何Bug,第一次作业和第二次作业的实现比较简单,实现过程中出现的也都是手误Bug。因此具体说说自己在实现第三次作业过程中出现的Bug。
(1)拷贝机制理解不够造成的Bug
在化简和优化时,由于需要判断拆开时会不会使得输出的字符串更短,故需要实现克隆功能。然而由于对Java语言的不熟悉,一开始使用的是浅拷贝,在部分情况下会出现优化错误的Bug,在debug的过程中很难发现这一Bug。不过踩过了这个坑之后,我相信以后自己能避开它。
(2)equals方法与==
由于还不习惯Java语言的字符串,对象的比较,我的程序中多处由于手误出现了==和equals的Bug,此属于习惯问题,需要多多注意。
四、互测他人Bug方式分析
在互测中,我实现了同时对七位Room友的自动化测试。但由于大家都太强了,或者是我的自动生成数据写得不够具有针对性,在三次作业中都没有收获。
最后我采用助教在灌水群中提到的定向爆破的方法找出了几个Bug,即寻找逻辑繁琐杂乱的地方,针对这一部分设计数据,尝试Bug。
还采用了IDEA提供的CoverUp功能,在运行过程中分析没有运行到的代码段,观察这部分代码段,更容易发现问题,再设计数据运行到这段代码就能找出Bug。
五、设计模式反思
在本次的设计中考虑过使用工厂模式,但学习了工厂模式的时候我的第三次作业已经设计完成,考虑到时间问题还是使用了原本设计。
现在反思认为工厂模式能避开耦合,且能够不够我犯下之前提到的重大失误,应该采用。
六、总结与反思
在这三次作业中我学习到了很多新的知识并且对Java语言更熟练了。我认为最重要的收获便是我通过大量时间换来的三个教训:
1. 设计时尽全力周全地考虑延展性,尽可能在第一次就使用延展性强的架构。
2. 不要捡了芝麻丢了西瓜,绝对不能因为局部的一点方便而打破了程序设计思路的完整性,整体性,否则之后会付出巨大的代价。
3. 浪子回头永远不晚,在基础的设计出现失误时,除非无法在ddl前完成,一定要回头,在一个已经设计烂了的架构上继续打补丁非常慢,而且体验极差,需要考虑的事情非常杂乱,不如重写,反而节约了时间!
在设计,优化过程中听取了很多同学和助教的意见,非常感谢他们。

