Hadoop大作业
1.将爬虫大作业产生的csv文件上传到HDFS,选取的文件是hhh.csv,大约30000条数据
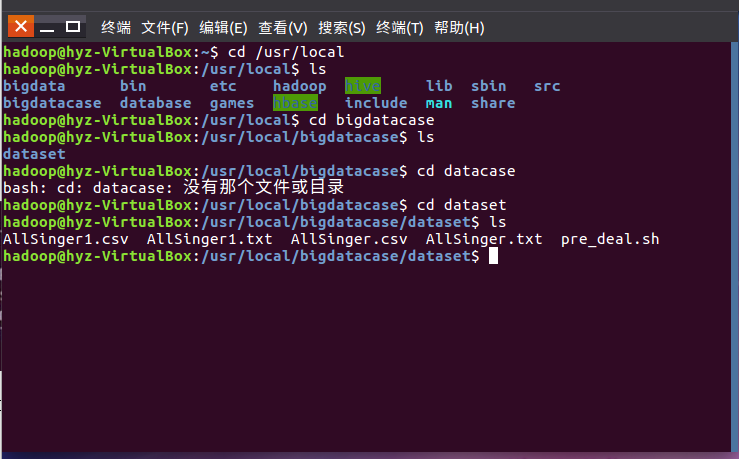
创建文件夹,导入hhh.csv文件并查看。并启动hadoop
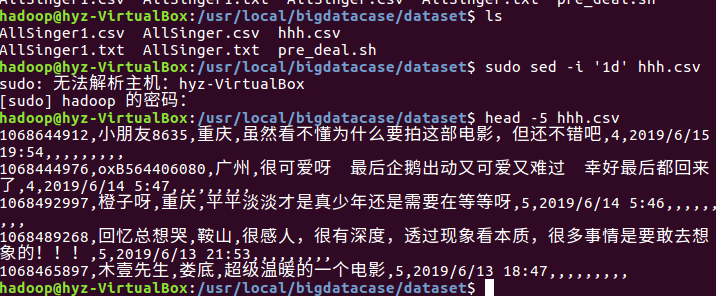
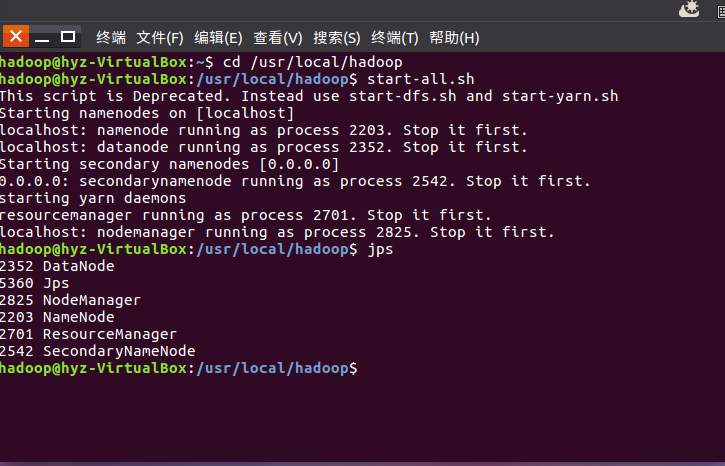
将hhh.csv文件导入hdfs中
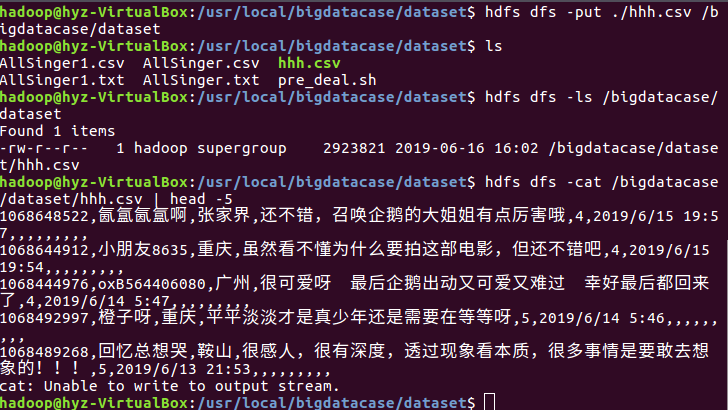
导入数据库hive中,创建数据库dbpy,创建表hhh_py,并查看前五行数据。
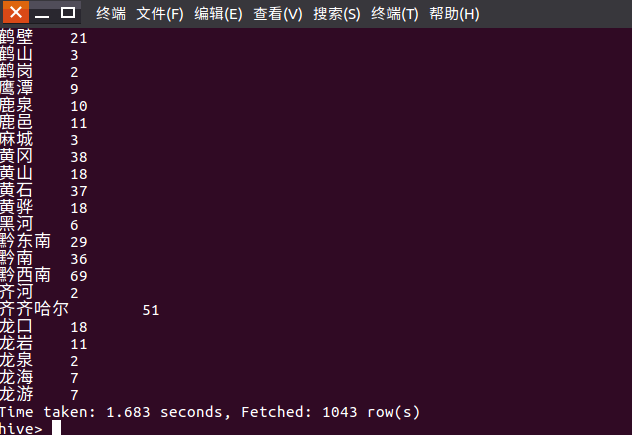
用select选取城市相同的并求和
再次创建hyz1_py表,做同样操作发现没有问题

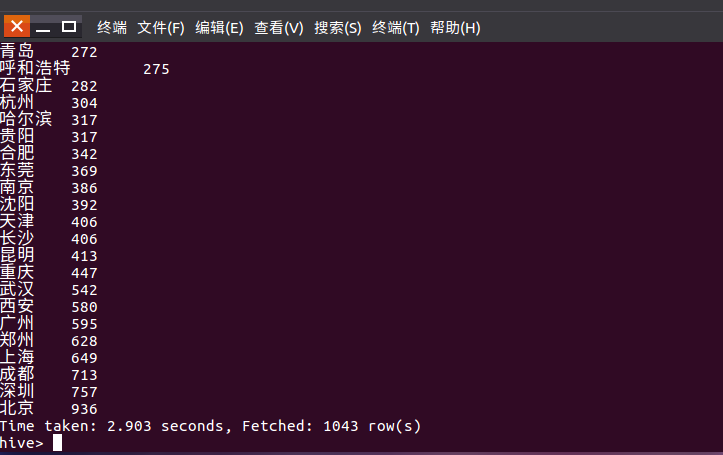
用语句select city count(distinct positionID) as sum group by city order by sum 统计并排序查看城市最多得,得到结果北京用户最多
用select time from hyz1_py limit 5 选取前5条数据看出最后一位用户评论时间是2019 - 6 - 15 19:57
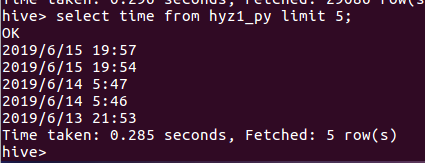
用select * from hyz1_py where mark='5' limit 10 选取评分为5分的前十条用户数据
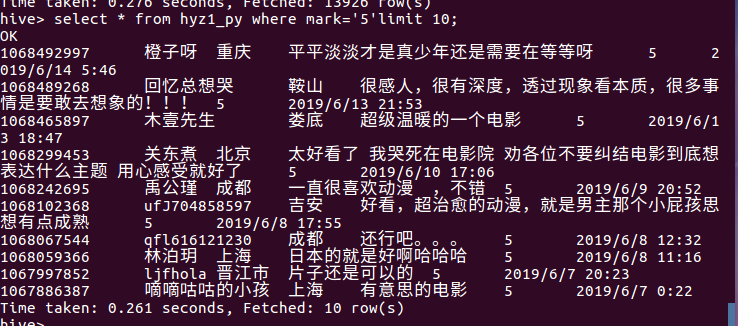
用select count(*) from hyz1_py where mark='5' 对评分为5的数据进行求和 共有13926条
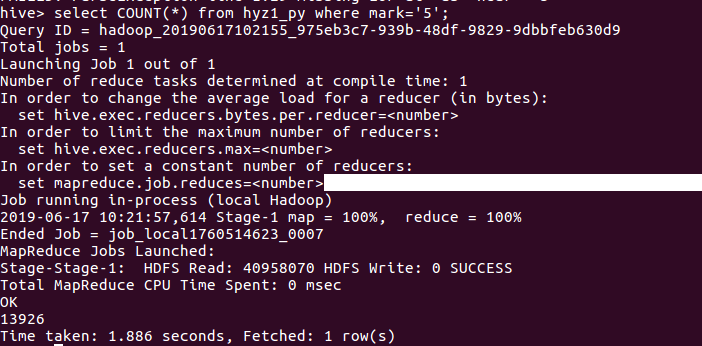
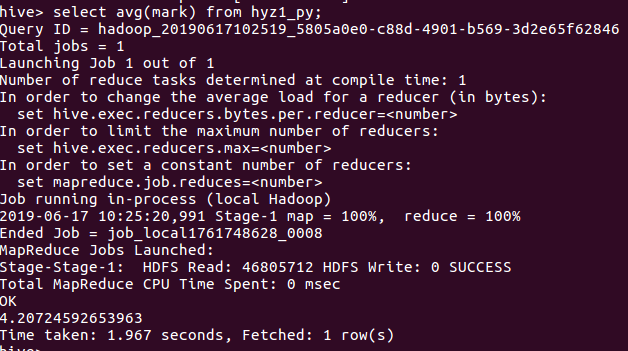
用 select avg(mark) from hyz1_py 对评分求平均数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号