

5 模块
-
定义:
-
导入方法
import module_name
import module1_name,module2_name
from module_lisi import *
from module_lisi import m1,m2,m3
from module_lisi import logger as logger_lisi
import module_lisi print(module_lisi.name) module_lisi.say_hello()
from module_lisi import * """ name = 'lisi' def say_hello(): print("hello lisi") def logger(): #logger----->print('hello lisi') print('hello lisi') def running(): pass """ def logger(): #logger----->print('hello main') print('hello main') logger()# import module_lisi from module_lisi import logger as logger_lisi def logger(): print('hello main') logger() logger_lisi() -
import本质(路径搜索和搜索路径)
导入模块的本质就是把python文件解释一遍
import test(test=‘test.py all code’)
import module_name #module_name = all_code module_alex.name module_name.logger()相当于里面代码赋给一个变量(module_name)然后变量名.来调用方法 module_name.logger()
from test import m1(m1 = ‘code’)
from module_name import * # 相当于直接把模块里面的代码拿过来用 logger()
module_name.py C:\Users\jjh\Desktop\python\module_name
def login(): print("wecome to my atm")main.py C:\Users\jjh\Desktop\python\模块\main.py
import os,sys BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(BASE_DIR) import module_name module_name.logger()
导入包的本质就是执行该包下的__init__.py文件
__init__.py
print("hello package_test") # import test1 #test1='test1.py all code' .test1.test() from . import test1test1.py
def test(): print("hello test")p_test.py
import package_test package_test.test1.test()
-
导入优化
前 import module_test module_test.test() #反复调用效率低 后 from module_test import test (as xxx) #括号为别名 test()
-
模块的分类:
a:标准库
b:开源模块
c:自定义模块
标准库:
1.time与datetime
time
>>> time.timezone #UTC与本地时间差值 -28800 >>> 28800/3600 8.0 >>> time.altzone #UTC与DST夏令时差值 -32400 >>> 32400/3600 9.0 >>> time.daylight #判断是否为夏令时 0 >>> time.time() #时间戳 1612429274.4117286 >>> time.sleep(2) #睡眠 #时间戳获取元组形式 >>> time.gmtime() #UTC时区,默认当前时间 time.struct_time(tm_year=2021, tm_mon=2, tm_mday=4, tm_hour=9, tm_min=3, tm_sec=30, tm_wday=3, tm_yday=35, tm_isdst=0) >>> time.localtime() #UTC+8时区,默认当前时间 time.struct_time(tm_year=2021, tm_mon=2, tm_mday=4, tm_hour=17, tm_min=3, tm_sec=47, tm_wday=3, tm_yday=35, tm_isdst=0) >>> time.localtime(123456789) time.struct_time(tm_year=1973, tm_mon=11, tm_mday=30, tm_hour=5, tm_min=33, tm_sec=9, tm_wday=4, tm_yday=334, tm_isdst=0) >>>
import time
x = time.localtime(123456789)
print(x)
# print(help(x))
print(x.tm_year) #获取年份
print('this is %d day:%d' %(x.tm_year,x.tm_yday))
# struct_time(tuple)转换为时间戳
>>> x = time.localtime()
>>> time.mktime(x)
1612430074.0
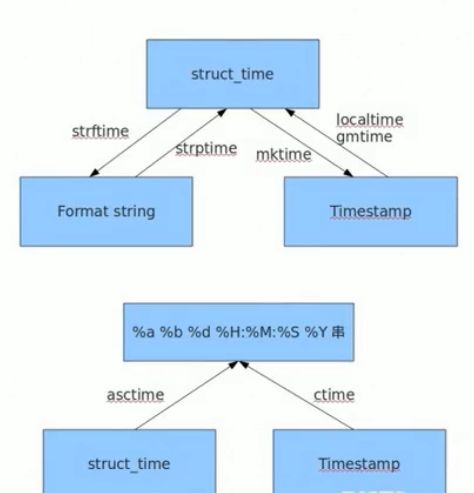
#strftime("格式",struct_time) ---> 格式化的字符串
>>> time.strftime("%Y-%m-%d %H:%M:%S",x) #格式位置可换
'2021-02-04 17:14:34'
#strptime("格式化的字符串","格式") ---> struct_time
>>> time.strptime('2021-02-04 17:14:34',"%Y-%m-%d %H:%M:%S") #格式位置不要换
time.struct_time(tm_year=2021, tm_mon=2, tm_mday=4, tm_hour=17, tm_min=14, tm_sec=34, tm_wday=3, tm_yday=35, tm_isdst=-1)
>>>
help(time.strftime) strftime(format[, tuple]) -> string
is not present, current time as returned by localtime() is used.
Commonly used format codes:
%Y Year with century as a decimal number. %m Month as a decimal number [01,12]. %d Day of the month as a decimal number [01,31]. %H Hour (24-hour clock) as a decimal number [00,23]. %M Minute as a decimal number [00,59]. %S Second as a decimal number [00,61]. %z Time zone offset from UTC. %a Locale's abbreviated weekday name. %A Locale's full weekday name. %b Locale's abbreviated month name. %B Locale's full month name. %c Locale's appropriate date and time representation. %I Hour (12-hour clock) as a decimal number [01,12]. %p Locale's equivalent of either AM or PM.
#asctime([tuple]) -> string >>> time.asctime() 'Thu Feb 4 17:36:16 2021' #ctime(seconds) -> string >>> time.ctime() 'Thu Feb 4 17:37:58 2021'
datetime
>>> import datetime
#三种类
>>> datetime.date #日期
<class 'datetime.date'>
>>> datetime.time #时间
<class 'datetime.time'>
>>> datetime.datetime #日期时间
<class 'datetime.datetime'>
>>> print(datetime.datetime.now())
2021-02-04 17:46:18.769956
>>> print(datetime.date.fromtimestamp(time.time())) #时间戳直接转换成日期格式
2021-02-04
#当前时间+3天
>>> print(datetime.datetime.now() + datetime.timedelta(3))
2021-02-07 17:51:07.238133
#当前时间-3天
>>> print(datetime.datetime.now() + datetime.timedelta(-3))
2021-02-01 17:51:13.507524
#当前时间-3小时
>>> print(datetime.datetime.now() + datetime.timedelta(hours = -3))
2021-02-04 14:53:17.338997
#当前时间+3小时
>>> print(datetime.datetime.now() + datetime.timedelta(hours = 3))
2021-02-04 20:53:27.443156
#当前时间+3分
>>> print(datetime.datetime.now() + datetime.timedelta(minutes = 3))
2021-02-04 17:57:16.082105
#当前时间-3分
>>> print(datetime.datetime.now() + datetime.timedelta(minutes = -3))
2021-02-04 17:51:27.203019
#
>>> c_time = datetime.datetime.now()
>>> print(c_time.replace(minute=3,hours=2))#时间替换
2.random
import random
print(random.random()) #0-1
print(random.uniform(1,2)) #
print(random.randint(0,1)) #随机整数
print(random.randrange(0,10,2)) #随机范围内的值
print(random.choice(("hello","hi"))) #随机序列或字符串
print(random.sample(["hello","lisi","zhangsan","wangwu"],2)) #随机一个序列或字符串的长度
#洗牌
items = list(range(10))
random.shuffle(items)
print(items)
import random
checkcode = ""
for i in range(5):
current = random.randrange(0,5)
if current == i:
tmp = chr(random.randrange(65,90))
else:
tmp = random.randrange(0,9)
checkcode += str(tmp)
print(checkcode)
3.os模块

import os
print(os.getcwd()) #当前位置
os.chdir('C:\\Users\\') #切换目录
# os.chdir(r'C:\Users\')
print(os.getcwd())
print(os.curdir) #返回当前目录
print(os.pardir) #获取上级目录
os.makedirs(r"D:\a\b\c") #递归生成目录
os.removedirs(r"D:\a\b\c") #递归删除空目录
os.mkdir(r"D:\a\b\c")
os.rmdir(r'D:\a\b\c') #删除单级空目录
print(os.listdir(r'D:')) #列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove(r"D:\a\b\c\test.text") #删除一个文件
os.rename(r"D:\a\1.txt",r"D:\a\2.txt") #重命名/目录
os.rename(r"D:\a",r"D:\ab")
print(os.stat(r"D:\ab")) #获取文件/目录的信息
print(os.sep) #输出系统特定的路径分隔符
print(os.altsep) #
print(os.extsep)
print(os.linesep) #当前平台使用的终止符,win\t\n,Linux\n
print(os.pathsep) #输出用于分隔文件路径的字符串
print(os.name) #输出字符串指示当前使用平台。win -> nt ; linux -> posix
print(os.system("dir")) #运行shell命令,直接显示
print(os.environ) #获取系统的环境变量
print(os.path.abspath(r"D:")) #返回path规范化的绝对路径
print(os.path.split(r"D:\ab\b\c")) #将path分割成目录和文件名二元组返回
print(os.path.dirname()) #返回path的目录,其实就是os.path.split(path)的第一个元素
print(os.path.basename()) #返回path最后的文件名
print(os.path.exists(r"D:\ab\b\c")) #如果path存在,则为Ture
print(os.path.isabs(r"D:\ab\b\c")) #如果path是绝对路径,则为Ture
print(os.path.isfile(r"D:\ab\2.txt")) #如果path是一个存在的文件,则为Ture
print(os.path.isdir(r"D:\ab")) #path是一个存在的目录,则为Ture
print(os.path.join(r"D:",r"\ab","b","c","d")) #将多个路径组合返回,第一个绝对路径之前的参数将被忽略
print(os.path.getatime(r"D:\ab\2.txt")) #path指向的文件或目录的最后存取时间
print(os.path.getmtime(r"D:\ab")) #path指向的文件或目录的最后修改时间
4.sys
import sys,time
print(sys.path) #返回模块的搜索路径,初始化是使用PYTHONPATH环境变量的值
# sys.exit() #退出程序,正常退出时exit(0)
print(sys.version) #获取python解释程序的版本信息
print(sys.maxsize)
print(sys.maxunicode)
print(sys.platform) #返回平台的名称
sys.stdout.write('please:')
val = sys.stdin.readline()[:-1]
# for i in range(20): #进度条
# sys.stdout.write("#")
# sys.stdout.flush()
# time.sleep(0.5)
5.shutil
高级的 文件、文件夹、压缩包 处理模块
shutil
import shutil,os
f1 = open("test.text",encoding="utf-8")
f2 = open("test2.txt","w",encoding="utf-8")
# shutil.copyfileobj(f1,f2) #将文件内容拷贝到另一个文件中,可以部分内容
# shutil.copyfile("test.text","t3.txt") #拷贝文件
# shutil.copymode("test.text","t3.txt") #仅拷贝权限。内容、组、用户均不变
# # print(os.stat("t3.txt"))
#
# shutil.copystat("test.text","t3.txt") #拷贝状态的信息,包括,mode,bits,atime,mtime,flags
#
# shutil.copy("t3.txt","t4.txt") #copy文件和权限(copyfile和copymode)
# shutil.copy2("t3.txt","t5.txt") #copy文件(包括权限)和状态信息
# shutil.copytree("package_test","new_package_test") #递归copy文件
# shutil.rmtree("new_package_test")
# shutil.move("t5.txt","t6.txt") #递归的去移动文件
# shutil.make_archive("shutil_test_zip","zip",r"C:\Users\黄建海\Desktop\python\模块\package_test")
# os.remove("shutil_test_zip.zip")
make_archive:
创建压缩包并返回文件路径,例如:zip、tar base_name:压缩包的文件名或包的路径。只是文件时,则保存当前目录,否则保存至指定路径。 如:www => 保存至当前路径 /User/zhangsan/www => 保存至/User/zhangsan/ format:压缩包的种类,zip,tar,bztar,gztar root_dir:压缩的文件路径(默认当前目录) owner:用户,默认当前用户 group:组,默认当前组 logger:用于记录日志,通常logging.Logger对象
zipfile
shutil对压缩包的处理是调用ZipFile和TarFile两个模块来进行的
import zipfile
#压缩
z = zipfile.ZipFile("test.zip","w")
z.write("t3.txt")
print("----")
z.write("sys模块.py")
z.close()
#解压
z = zipfile.ZipFile('test.zip',"r")
z.extractall()
z.close()
tarfile
import tarfile
#压缩
tar = tarfile.open('tar_test.tar',"w")
tar.add('/Users/wupeiqi/PycharmProjects/bbs2.zip', arcname='bbs2.zip')
tar.add('/Users/wupeiqi/PycharmProjects/cmdb.zip', arcname='cmdb.zip')
tar.close()
#解压
tar = tarfile.open('tar_test.tar',"r")
tar.extractall() #可设置解压地址
tar.close()
json和pickle
出处:http://www.cnblogs.com/wupeiqi/
用于序列化的两个模块
-
json,用于字符串 和 python数据类型间进行转换
-
pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
shelve模块
shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式
import shelve,datetime
d = shelve.open("shelve_test")
info = {"age":22,"job":"it"}
name = ["zhangsan","lisi","wangwu"]
d["name"] = name #持久化列表
d["info"] = info #持久dict
d["date"] = datetime.datetime.now()
print(d.get("name"))
print(d.get("info"))
print(d.get("date"))
d.close()
xml模块
xmltest.xml
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
遍历
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
print(root)
print(root.tag)
# 遍历xml文档
for child in root:
print(child.tag, child.attrib)
for i in child:
print(i.tag, i.text, i.attrib)
# 只遍历year 节点
for node in root.iter('year'):
print(node.tag, node.text)
删改
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
# 修改
for node in root.iter('year'): #查找标签year
new_year = int(node.text) + 1
node.text = str(new_year) #修改text
node.set("updated", "yes") #添加属性
tree.write("xmltest.xml")
# 删除node
for country in root.findall('country'): #findall找出所有country
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country)
tree.write('output.xml')
yaml模块
Python也可以很容易的处理ymal文档格式,只不过需要安装一个模块,参考文档:http://pyyaml.org/wiki/PyYAMLDocumentation
configparser模块
用于生成和修改常见配置文档
import configparser
config = configparser.ConfigParser() #生成处理对象
config["DEFAULT"] = {'ServerAliveInterval':'45',
'Compression':'yes',
'CompressionLevel':'9'}
config['bitbucket.org'] = {}
config['bitbucket.org']['User'] = 'hg'
config['topsecret.server.com'] = {}
topsecret = config['topsecret.server.com']
topsecret['Host Port'] = '50022' # mutates the parser
topsecret['ForwardX11'] = 'no' # same here
config['DEFAULT']['ForwardX11'] = 'yes'
with open('example.ini', 'w') as configfile:
config.write(configfile)
config.write()
import configparser
conf = configparser.ConfigParser()
conf.read("example.ini")
#############读############
print(conf.defaults()) #返回默认配置的key和value
print(conf.sections()) #返回非默认标签
print(conf.options("bitbucket.org")) #列表
print(conf.items("bitbucket.org")) #列表二元组
print(conf.get("bitbucket.org","user"))
print(conf['bitbucket.org']['user'])
# for key in conf["topsecret.server.com"]:
# print(key)
##########改写##########
sec = conf.remove_section('bitbucket.org')
conf.write(open('example.cfg',"w"))
sec = conf.has_section('wupeiqi') #判断是否存在
print(sec)
sec = conf.add_section('wupeiqi')
conf.write(open('example.cfg', "w"))
# conf.set('group2','k1',11111)
# conf.write(open('example.cfg', "w"))
hashlib模块和hmac模块
import hashlib
m = hashlib.md5()
m.update(b"Hello") #Hello
print(m.hexdigest())
m.update(b"Word") #Hello + Word
print(m.hexdigest())
m2 = hashlib.md5()
# m2.update(b"HelloWord")
m2.update("HelloWord".encode(encoding="utf-8"))
print(m2.hexdigest())
s2 = hashlib.sha1()
s2.update(b"HelloWord")
print(s2.digest())
print(s2.hexdigest())
import hmac
h = hmac.new("12345你好".encode(encoding="utf-8"),"hello 123 世界".encode(encoding="utf-8"))
print(h.digest())
print(h.hexdigest())
re正则表达式
常用正则表达式符号
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行
'^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)
'$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以
'*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']
'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']
'?' 匹配前一个字符1次或0次
'{m}' 匹配前一个字符m次
'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']
'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC'
'(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c
'\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的
'\Z' 匹配字符结尾,同$
'\d' 匹配数字0-9
'\D' 匹配非数字
'\w' 匹配[A-Za-z0-9]
'\W' 匹配非[A-Za-z0-9]
's' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t'
'(?P<name>...)' 分组匹配 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict("city") 结果{'province': '3714', 'city': '81', 'birthday': '19
93'}
匹配语法
re.match 从头开始匹配 re.search 匹配包含 re.findall 把所有匹配到的字符放到以列表中的元素返回 re.splitall 以匹配到的字符当做列表分隔符 re.sub 匹配字符并替换
匹配模式
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同) M(MULTILINE): 多行模式,改变'^'和'$'的行为 S(DOTALL): 点任意匹配模式,改变'.'的行为
反斜杠的困扰
与大多数编程语言相同,正则表达式里使用""作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\"表示。同样,匹配一个数字的"\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
