

装饰器和迭代器
装饰器:
原则:1.不能修改被装饰的函数的源代码
2.不能修改被装饰的函数调用方式
实现装饰器知识储备:
1.函数即“变量”
2.高阶函数
a:把一个函数名当做实参传给另外一个函数(在不修改被装饰函数源代码的情况下为其添加功能)
b:返回值中包含函数名(不修改函数的调用方式)
3.嵌套函数(在一个函数体里声明一个函数)
高阶函数+嵌套函数=》 装饰器
装饰器的应用:
代码:利用装饰器查看函数test1运行所花时间
import time
def timmer(func):
def warpper(*args,**kwargs):
start_time=time.time()
func()
stop_time=time.time()
print('the func run time is %s' %(stop_time-start_time))
return warpper
@timmer
def test1():
time.sleep(3)
print('in the test1')
test1()
# 输出:
# in the test1
# the func run time is -3.004067897796631
1 装饰器之函数即“变量”
变量:先定义再调用

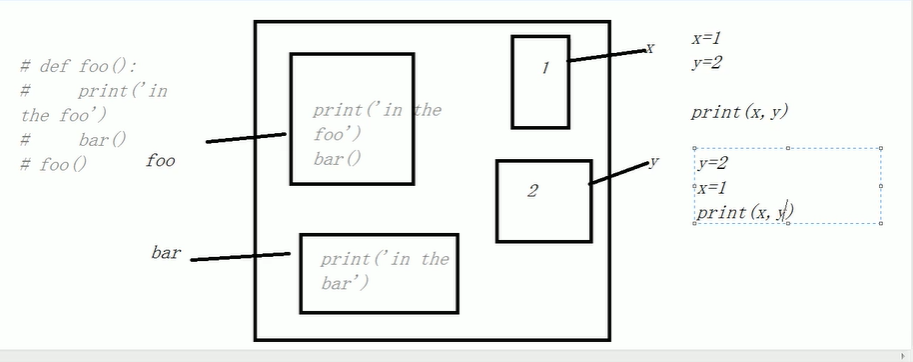
# 1 没用foor时,没有bar函数后半代码出错
def foo():
print('in the foo')
bar()
foo()
# 2
def bar():
print('in the bar')
def foo():
print('in the foo')
bar()
foo()
# 2,3相同
# 3
def foo():
print('in the foo')
bar()
def bar():
print('in the bar')
foo()
# 4 这里调用foo()时,bar()还没有读到
def foo():
print('in the foo')
bar()
foo()
def bar():
print('in the bar')
2 装饰器之高阶函数
a:把一个函数名当做实参传给另外一个函数
# #高阶函数(被装饰的函数作为装饰器的实参),这里更改了被装饰的函数的调用方式(作为装饰器的实参)
import time
def bar():
time.sleep(2)
print('in the bar')
def test1(func):
start_time=time.time()
func() #run bar
stop_time=time.time()
print('the func run time is %s' %(stop_time-start_time))
test1(bar)
print(bar) # 调用bar函数不带()时,输出为内存地址
b:返回值中包含函数名
# #高阶函数(返回值),这里bar=test2(bar),还缺嵌套函数(才能是装饰器,可用于省略前面的代码,在被装饰的函数体前加( @第一层函数名 ))
import time
def bar():
time.sleep(2)
print('in the bar')
def test2(func):
print(func)
return func
# print(test2(bar))
bar = test2(bar)
bar()
3 嵌套函数
局部作用域和全局作用域的访问顺序(里-->外)
x = 0
def grandpa():
# x = 1
def dad():
x = 2
def son():
x = 3
print(x)
son()
dad()
grandpa()
装饰器案例1:
import time
def timer(func): #timer(test1) func=test1
def deco():
start_time = time.time()
func() #run test1()
stop_time = time.time()
print("the func run time is %s" %(stop_time-start_time))
return deco
# def timer():
# def deco():
# pass
@timer #test1=timer(test1)
def test1():
time.sleep(3)
print('in the test1')
@timer
def test2():
time.sleep(3)
print('in the test2')
# test1 = timer(test1)
# test1() #--->deco
test1()
test2()
简化
import time
def timer(func): #timer(test1) func=test1
def deco():
start_time = time.time()
func() #run test1()
stop_time = time.time()
print("the func run time is %s" %(stop_time-start_time))
return deco
@timer #test1=timer(test1)
def test1():
time.sleep(3)
print('in the test1')
# test1 = timer(test1)
# test1() #--->deco
test1()
装饰器案例2:
import time
def timer(func): #timer(test1) func=test1
def deco(*args,**kwargs):
start_time = time.time()
func(*args,**kwargs) #run test1()
stop_time = time.time()
print("the func run time is %s" %(stop_time-start_time))
return deco
@timer #test1=timer(test1)
def test1():
time.sleep(1)
print('in the test1')
@timer
def test2(name,age):
print('test1: ',name,age)
# test1 = timer(test1)
# test1() #--->deco
test1()
test2("hello",18)
装饰器案例3:
import time
user,passwd = "张三","123456"
def auth(func):
def wrapper(*args,**kwargs):
username = input("Username:").strip()
password = input("password:").strip()
if user == username and passwd == password:
print("\033[32:1mUser has passwd authentication\033[0m")
func(*args,**kwargs)
else:
exit("\033[31:1mInvalid username or password\033[0m")
return wrapper
def index():
print("welcome to index page")
@auth
def home():
print("welcome to home page")
@auth
def bbs():
print("welcome to bbs page")
index()
home()
bbs()
加内容:
import time
user,passwd = "张三","123"
def auth(auth_type):
print("auth auth_type:",auth_type)
def outer_wrapper(func):
def wrapper(*args, **kwargs):
print("wrapper func args:",*args, **kwargs)
if auth_type == "local":
username = input("Username:").strip()
password = input("password:").strip()
if user == username and passwd == password:
print("\033[32:1mUser has passwd authentication\033[0m")
res = func(*args, **kwargs)
print("---after authenticaion")
return res
else:
exit("\033[31:1mInvalid username or password\033[0m")
elif auth_type == "ldap":
print("搞毛线ldap,不会。。。。")
return wrapper
return outer_wrapper
def index():
print("welcome to index page")
@auth(auth_type="local")
def home():
print("welcome to home page")
return "from home"
@auth(auth_type="ldap")
def bbs():
print("welcome to bbs page")
index()
print(home()) #wrapper()
bbs()
生成器
生成器
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
生成器:只有在调用时才会生成相应的数据
只记录当前位置
只有一个__next__()方法。next(g)
要创建一个generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator:
# 列表生成器 L = [i*2 for i in range(10)] print(L) # [0, 2, 4, 6, 8, 10, 12, 14, 16, 18] #生成器 g = (i*2 for i in range(10)) print(g) # <generator object <genexpr> at 0x000002BFCB8DE948>
L为list(可以直接打印每一个元素),g为一个generator。
generator可以通过next()函数获得generator的下一个返回值:
>>> a = (i*2 for i in range(10)) >>> a.__next__() 0 >>> a.__next__() 2 >>> a.__next__() 18 >>> a.__next__() Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration >>> b = (i*2 for i in range(10)) >>> next(b) 0 >>> next(b) 2 #... >>> next(b) 18 >>> next(b) Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration
generator保存的是算法,每次调用next(g),就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误。
当然,上面这种不断调用next(g)实在是太变态了,正确的方法是使用for循环,因为generator也是可迭代对象:
>>> g =(x*x for x in range(10)) >>> for n in g: ... print(n) ... 0 1 4 9 16 25 36 49 64 81
斐波那契
所以,我们创建了一个generator后,基本上永远不会调用next(),而是通过for循环来迭代它,并且不需要关心StopIteration的错误。
generator非常强大。如果推算的算法比较复杂,用类似列表生成式的for循环无法实现的时候,还可以用函数来实现。
比如,著名的斐波拉契数列(Fibonacci),除第一个和第二个数外,任意一个数都可由前两个数相加得到:
1, 1, 2, 3, 5, 8, 13, 21, 34, ...
斐波拉契数列用列表生成式写不出来,但是,用函数把它打印出来却很容易:
def fib(max): #10
n,a,b = 0,0,1
while n < max: #n<10
print(b)
# yield b
a,b = b, a+b
n = n + 1
return '---done---'
f = fib(10)
ps:a用来保存前一个b的值,b用来获取下一个值
注意,赋值语句:
a,b = b, a+b
相当于:
t = (b,a+b) # t是一个tuple a = t[0] b = t[1]
a,b = 0,1 a,b = a, a + b a,b = 1,1 a,b = 1,2 a,b = 2,3 a,b = 3,5 a,b = 5,8 a,b = 8,13
生成器2
裴波那契写成生成器:
-
yield 结束函数,返回生成器。
-
try 关键字用于 try...except 块中。它定义了代码测试块是否包含任何错误。
在 try 块中出现错误时引发错误并停止程序:
try: x > 3 except: raise Exception("Something went wrong")
def fib(max): #10
n,a,b = 0,0,1
while n < max: #n<10
#print(b)
yield b
a,b = b, a+b
n = n + 1
return '---done---'
# f = fib(5)
# print("------dd")
# print(f.__next__())
# print("======")
# print(f.__next__())
# print(f.__next__())
# print(f.__next__())
# print(f.__next__())
# print(f.__next__()) # 用完会报错
g = fib(6)
while True:
try:
x = next(g)
print('g:', x)
except StopIteration as e:
print('Generator return value:', e.value)
break
这就是定义generator的另一种方法。如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator:
>>> f = fib(6) >>> f <generator object fib at 0x104feaaa0>
在循环过程中不断调用yield,就会不断中断。当然要给循环设置一个条件来退出循环,不然就会产生一个无限数列出来。
同样的,把函数改成generator后,我们基本上从来不会用next()来获取下一个返回值,而是直接使用for循环来迭代:
>>> for n in fib(6): ... print(n) ... 1 1 2 3 5 8
生成器:包子并行(协程)
import time
def consumer(name):
print("%s 准备吃包子啦!" %name)
while True:
baozi = yield
print("包子[%s]来了,被[%s]吃了!" %(baozi,name))
c = consumer("ChenRonghua")
c.__next__()
# b = "韭菜馅"
# c.send(b) #调用yield且传值
# c.__next__() #调用yield
def producer(name):
c = consumer('A')
c2 = consumer('B')
c.__next__()
c2.__next__()
print("老子开始装备吃包子啦!")
for i in range(1,3):
time.sleep(1)
print("做了1个包子,分两半!")
c.send(i)
c2.send(i)
producer("张三")
迭代器
可迭代对象
可以直接作用于for循环的数据类型有以下几种:
一类是集合数据类型,如list、tuple、dict、set、str等;
一类是generator,包括生成器和带yield的generator function。
这些可以直接作用于for循环的对象统称为可迭代对象:Iterable。
可以使用isinstance()判断一个对象是否是Iterable对象:
from collections import Iterable
print(isinstance([],Iterable)) #True
print(isinstance({},Iterable)) #True
print(isinstance('abc',Iterable)) #True
print(isinstance((x for x in range(2)),Iterable)) #True
print(isinstance(100,Iterable)) #False
迭代器
而生成器不但可以作用于for循环,还可以被next()函数不断调用并返回下一个值,直到最后抛出StopIteration错误表示无法继续返回下一个值了。
*可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
可以使用isinstance()判断一个对象是否是Iterator对象:
from collections import Iterator
print(isinstance((x for x in range(10) ), Iterator)) #True
print(isinstance([], Iterator)) #False
print(isinstance({}, Iterator)) #False
print(isinstance('abc', Iterator)) #False
iter()
生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
把list、dict、str等Iterable变成Iterator可以使用iter()函数:
from collections import Iterator
print(isinstance(iter([]),Iterator)) #Ture
print(isinstance(iter('abc'),Iterator)) #Ture
dir()
查看一个数据类型的方法
小结
凡是可作用于for循环的对象都是Iterable类型;
凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;for i in f:、range()
集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
Python的for循环本质上就是通过不断调用next()函数实现的,例如:
for i in range(3): pass
实际上完全等价于:
# 首先获得Iterator对象
it = iter([0,1,2])
# 循环
while True:
try:
# 获取下一个值
x = next(it)
except StopIteration:
# 遇到StopIteration:
break
内建函数
函数表
Python 有一组内建函数。
| 函数 | 描述 |
|---|---|
| 返回数的绝对值 | |
| 如果可迭代对象中的所有项均为 true,则返回 True。 | |
| 如果可迭代对象中的任何项为 true,则返回 True。 | |
| 返回对象的可读版本。用转义字符替换 none-ascii 字符。 | |
| 返回数的二进制版本。 | |
| 返回指定对象的布尔值。 | |
| 返回字节数组。 | |
| 返回字节对象。 | |
| 如果指定的对象是可调用的,则返回 True,否则返回 False。 | |
| 返回指定 Unicode 代码中的字符。 | |
| classmethod() | 把方法转换为类方法。 |
| 把指定的源作为对象返回,准备执行。 | |
| 返回复数。 | |
| 从指定的对象中删除指定的属性(属性或方法)。 | |
| 返回字典(数组)。 | |
| 返回指定对象的属性和方法的列表。 | |
| 当参数1除以参数2时,返回商和余数。 | |
| 获取集合(例如元组)并将其作为枚举对象返回。 | |
| 评估并执行表达式。 | |
| 执行指定的代码(或对象)。 | |
| 使用过滤器函数排除可迭代对象中的项目。 | |
| 返回浮点数。 | |
| 格式化指定值。 | |
| 返回 frozenset 对象。 | |
| 返回指定属性的值(属性或方法)。 | |
| 以字典返回当前全局符号表。 | |
| 如果指定的对象拥有指定的属性(属性/方法),则返回 True。 | |
| hash() | 返回指定对象的哈希值。 |
| help() | 执行内建的帮助系统。 |
| 把数字转换为十六进制值。 | |
| 返回对象的 id。 | |
| 允许用户输入。 | |
| 返回整数。 | |
| 如果指定的对象是指定对象的实例,则返回 True。 | |
| 如果指定的类是指定对象的子类,则返回 True。 | |
| 返回迭代器对象。 | |
| 返回对象的长度。 | |
| 返回列表。 | |
| 返回当前本地符号表的更新字典。 | |
| 返回指定的迭代器,其中指定的函数应用于每个项目。 | |
| 返回可迭代对象中的最大项目。 | |
| 返回内存视图(memory view)对象。 | |
| 返回可迭代对象中的最小项目。 | |
| 返回可迭代对象中的下一项。 | |
| 返回新对象。 | |
| 把数转换为八进制。 | |
| 打开文件并返回文件对象。 | |
| 转换表示指定字符的 Unicode 的整数。 | |
| 返回 x 的 y 次幂的值。 | |
| 打印标准输出设备。 | |
| property() | 获取、设置、删除属性。 |
| 返回数字序列,从 0 开始且以 1 为增量(默认地)。 | |
| repr() | 返回对象的可读版本。 |
| 返回反转的迭代器。 | |
| 对数进行舍入。 | |
| 返回新的集合对象。 | |
| 设置对象的属性(属性/方法)。 | |
| 返回 slice 对象。 | |
| 返回排序列表。 | |
| @staticmethod() | 把方法转换为静态方法。 |
| 返回字符串对象。 | |
| 对迭代器的项目进行求和。 | |
| 返回表示父类的对象。 | |
| 返回元组。 | |
| 返回对象的类型。 | |
| 返回对象的 dict 属性。 | |
| 从两个或多个迭代器返回一个迭代器。 |
代码
print(abs(-2)) #绝对值
print(all([0,-1,2])) #如果可迭代对象中的所有项均为 true,则返回 True。
print(any([0,-1,2])) #如果可迭代对象中的任何项为 true,则返回 True。
a = ascii([1,2,"你好","hello"])
print(type(a),[a])
print(bin(255)) #返回数的二进制版本。
print(bool(0)) #布尔值
a = bytes("abcde",encoding="utf-8") # 不可修改
print(a)
b = bytearray("abcde",encoding="utf-8")
b[0] = 100 # a为97,d为100
print(b,b[0])
def sayhi():pass
print( callable(sayhi) ) #如果指定的对象是可调用的,则返回 True,对象后有括号为可调用
print( callable([]) )
print(chr(97)) #返回指定 Unicode 代码中的字符。
print(ord('a')) #字符转ascii码
# classmethod() 把方法转换为类方法
# >>> a = "for i in range(5):print(i)"
# >>> compile(a,'','exec')
# <code object <module> at 0x0000021E31B140C0, file "", line 1>
a = eval("1,2,3")
b = "1+2/3"
print(a,type(a)) #评估并执行表达式。如str转tuple
print(eval(b))
b = "for i in range(5):print(i)"
exec(b) #执行指定的代码(或对象)。
# #complex() 返回复数
# #delattr() 从指定的对象中删除指定的属性(属性或方法)。
# #dict() 返回字典(数组),{}和dict()
# #dir() 返回指定对象的属性和方法的列表。
print(divmod(1,2)) #当参数1除以参数2时,返回商和余数。
# #enumerate() 获取集合(例如元组)并将其作为枚举对象返回。(获取下标)
c = enumerate({'a','b','c','d'})
for index,line in c:
print(index,line)
# # 匿名函数
print("-------------匿名函数--------------")
# def sayhi(n):
# print(n)
# for i in range(n):
# print(i)
# sayhi(3)
#
# # (lambda n:print(n) )(5)
# calc = lambda n:3 if n<4 else n #只能写一些简单(一行输出、三元运算等)
# print(calc(8))
# res = filter(lambda n:n>5,range(10)) #使用过滤器函数排除可迭代对象中的项目。
# #map()返回指定的迭代器,其中指定的函数应用于每个项目。
res = map(lambda n:n*2,range(10)) #[ i*2 for i in range(10)]
# res = [ lambda i:i*2 for i in range(10)]
for i in res:
print(i)
#map()
def myfunc(n):
return len(n)
x = map(myfunc, ('apple', 'banana', 'cherry'))
import functools
res = functools.reduce( lambda x,y:x*y,range(1,4)) #x存储结果,y获取新值
print(res)
# #float() 返回浮点数。
# #format() 格式化指定值。
fset = frozenset([1,22,33,55,3423,35]) #不可变集合
print(type(fset))
# #getattr() 返回指定属性的值(属性或方法)。
# #hasattr() 如果指定的对象拥有指定的属性(属性/方法),则返回 True。
print(globals()) #以字典返回当前全局符号表。
print(hash("hello")) #返回指定对象的哈希值。
代码2
# # help #执行内建的帮助系统。
# #id() 返回对象的 id。
# #input() 允许用户输入。
# #int() 返回整数。
# from collections import Iterable
# print(isinstance([],Iterable)) #True,如果指定的对象是指定对象的实例,则返回 True。
# #issubclass() 如果指定的类是指定对象的子类,则返回 True。
# #iter() 返回迭代器对象。
# #len() 返回对象的长度。
# #list() 返回列表。
def test():
local_var = 333
print(locals()) #locals() #返回当前本地符号表的更新字典。
test()
print(globals())
print(globals().get('local_var'))
print(max([1,2,34,5])) #返回可迭代对象中的最大项目。
print(max({'zhangsan':'hello','lisi':'hello word'}))
print(min({'zhangsan':'hello','lisi':'hello word'})) #返回可迭代对象中的最小项目。
x = memoryview(b"Hello") #返回内存视图(memory view)对象。
print(x)
#return the Unicode of the first character
print(x[0])
#return the Unicode of the second character
print(x[1])
# #next() 返回可迭代对象中的下一项。
# #object() 返回新对象。
# 一切皆对象
# oct() 把数转换为八进制。
# open() 打开文件并返回文件对象。
# pow() 返回 x 的 y 次幂的值。
print(pow(2,2))
# print() 打印标准输出设备。
# property() 获取、设置、删除属性。
# range() 返回数字序列,从 0 开始且以 1 为增量(默认地)。
# repr() 返回对象的可读版本。
alph = ["a", "b", "c", "d"]
ralph = reversed(alph) # reversed() 返回反转的迭代器。
for x in ralph:
print(x)
x = round(3.1415926, 2) #对数进行舍入。
print(x)
# set() 返回新的集合对象。
# setattr() 设置对象的属性(属性/方法)。
a = ("a", "b", "c", "d", "e", "f", "g", "h")
x = slice(2,4)
print(a[x])
print(a[2:4])
a = {1:8,10:4,5:9,-7:18,2:10} #sorted 返回排序列表。
print(sorted(a.items())) #key排序
print(sorted(a.items(),key=lambda x:x[1])) #value排序
print(sorted(a))
# @staticmethod() 把方法转换为静态方法。
print(type(str(3.14))) # str() 返回字符串对象。
print(sum((1,2,3,4))) # sum() 对迭代器的项目进行求和。
# super() 返回表示父类的对象。
# tuple() 返回元组。
# type() 返回对象的类型。
class Person: # vars() 返回对象的 __dict__ 属性。
name = "John"
age = 36
country = "norway"
x = vars(Person)
a = ("Bill", "Steve", "Elon","hello")
b = ("Gates", "Jobs", "Musk")
x = zip(a, b)
print(tuple(x))
# import decorator
__import__('decorator')
json与pickle数据序列化
JSON 是用于存储和交换数据的语法。
json序列化
import json
def sayhi(name):
print("hello",name)
info = {
'name':'zhangsan',
'age':18,
# 'func':sayhi
}
f = open("test.text","w")
print(json.dumps(info))
f.write(json.dumps(info))
f.close()
json反序列化
import json
f = open('test.text','r')
data = json.loads(f.read())
print(data["age"])
pickle
import pickle
def sayhi(name):
print("hello",name)
info = {
'name':'zhangsan',
'age':18,
'func':sayhi
}
f = open("test.text","wb",)
print(pickle.dumps(info))
f.write(pickle.dumps(info))
f.close()
pickle
import pickle
def sayhi(name): #
# print("hello",name)
print("hello word", name)
f = open('test.text','rb')
data = pickle.loads(f.read())
print(data["func"]("zhangsan")) #提示出错,没找到sayhi的内存地址,所以copy函数过来
pickle2
import pickle
def sayhi(name):
print("hello",name)
info = {
'name':'zhangsan',
'age':18,
'func':sayhi
}
f = open("test.text","wb",)
pickle.dump(info,f) # f.write(pickle.dumps(info))
f.close()
pickle2
import pickle
def sayhi(name): #
# print("hello",name)
print("hello word", name)
f = open('test.text','rb')
data = pickle.load(f) # data = pickle.loads(f.read())
print(data["func"]("zhangsan")) #提示出错,没找到sayhi的内存地址,所以copy函数过来
json序列化2
一个文件dumps一次,这里dumps两次,loads出错
import json
def sayhi(name):
print("hello",name)
info = {
'name':'zhangsan',
'age':18,
# 'func':sayhi
}
f = open("test.text","w",)
# print(json.dumps(info))
f.write(json.dumps(info))
info['age'] = 17
f.write(json.dumps(info))
f.close()
import json
f = open('test.text','r')
for line in f:
# print(line)
print(json.loads(line))
目录结构规范
Foo/ |-- bin/ | |-- foo | |-- foo/ | |-- tests/ | | |-- __init__.py | | |-- test_main.py | | | |-- __init__.py | |-- main.py | |-- docs/ | |-- conf.py | |-- abc.rst | |-- setup.py |-- requirements.txt |-- README
简要解释一下:
-
bin/: 存放项目的一些可执行文件,当然你可以起名script/之类的也行。 -
foo/: 存放项目的所有源代码。(1) 源代码中的所有模块、包都应该放在此目录。不要置于顶层目录。(2) 其子目录tests/存放单元测试代码; (3) 程序的入口最好命名为main.py。 -
docs/: 存放一些文档。 -
setup.py: 安装、部署、打包的脚本。 -
requirements.txt: 存放软件依赖的外部Python包列表。 -
README: 项目说明文件。
除此之外,有一些方案给出了更加多的内容。比如LICENSE.txt,ChangeLog.txt文件等,我没有列在这里,因为这些东西主要是项目开源的时候需要用到。如果你想写一个开源软件,目录该如何组织,可以参考
关于README的内容
这个我觉得是每个项目都应该有的一个文件,目的是能简要描述该项目的信息,让读者快速了解这个项目。
它需要说明以下几个事项:
-
软件定位,软件的基本功能。
-
运行代码的方法: 安装环境、启动命令等。
-
简要的使用说明。
-
代码目录结构说明,更详细点可以说明软件的基本原理。
-
常见问题说明。
我觉得有以上几点是比较好的一个README。在软件开发初期,由于开发过程中以上内容可能不明确或者发生变化,并不是一定要在一开始就将所有信息都补全。但是在项目完结的时候,是需要撰写这样的一个文档的。
可以参考Redis源码中
关于requirements.txt和setup.py
setup.py
一般来说,用setup.py来管理代码的打包、安装、部署问题。业界标准的写法是用Python流行的打包工具
这个我是踩过坑的。
我刚开始接触Python写项目的时候,安装环境、部署代码、运行程序这个过程全是手动完成,遇到过以下问题:
-
安装环境时经常忘了最近又添加了一个新的Python包,结果一到线上运行,程序就出错了。
-
Python包的版本依赖问题,有时候我们程序中使用的是一个版本的Python包,但是官方的已经是最新的包了,通过手动安装就可能装错了。
-
如果依赖的包很多的话,一个一个安装这些依赖是很费时的事情。
-
新同学开始写项目的时候,将程序跑起来非常麻烦,因为可能经常忘了要怎么安装各种依赖。
setup.py可以将这些事情自动化起来,提高效率、减少出错的概率。"复杂的东西自动化,能自动化的东西一定要自动化。"是一个非常好的习惯。
setuptools的
当然,简单点自己写个安装脚本(deploy.sh)替代setup.py也未尝不可。
requirements.txt
这个文件存在的目的是:
-
方便开发者维护软件的包依赖。将开发过程中新增的包添加进这个列表中,避免在
setup.py安装依赖时漏掉软件包。 -
方便读者明确项目使用了哪些Python包。
这个文件的格式是每一行包含一个包依赖的说明,通常是flask>=0.10这种格式,要求是这个格式能被pip识别,这样就可以简单的通过 pip install -r requirements.txt来把所有Python包依赖都装好了。具体格式说明:
关于配置文件的使用方法
注意,在上面的目录结构中,没有将conf.py放在源码目录下,而是放在docs/目录下。
很多项目对配置文件的使用做法是:
-
配置文件写在一个或多个python文件中,比如此处的conf.py。
-
项目中哪个模块用到这个配置文件就直接通过
import conf这种形式来在代码中使用配置。
这种做法我不太赞同:
-
这让单元测试变得困难(因为模块内部依赖了外部配置)
-
另一方面配置文件作为用户控制程序的接口,应当可以由用户自由指定该文件的路径。
-
程序组件可复用性太差,因为这种贯穿所有模块的代码硬编码方式,使得大部分模块都依赖
conf.py这个文件。
所以,我认为配置的使用,更好的方式是,
-
模块的配置都是可以灵活配置的,不受外部配置文件的影响。
-
程序的配置也是可以灵活控制的。
能够佐证这个思想的是,用过nginx和mysql的同学都知道,nginx、mysql这些程序都可以自由的指定用户配置。
所以,不应当在代码中直接import conf来使用配置文件。上面目录结构中的conf.py,是给出的一个配置样例,不是在写死在程序中直接引用的配置文件。可以通过给main.py启动参数指定配置路径的方式来让程序读取配置内容。当然,这里的conf.py你可以换个类似的名字,比如settings.py。或者你也可以使用其他格式的内容来编写配置文件,比如settings.yaml之类的。
2
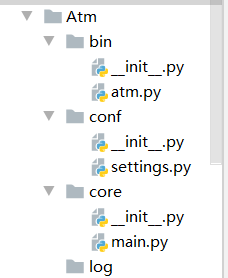
atm.py
import os,sys BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(BASE_DIR) from conf import settings from core import main main.login()
main.py
def login():
print("wecome to my atm")
ATM作业
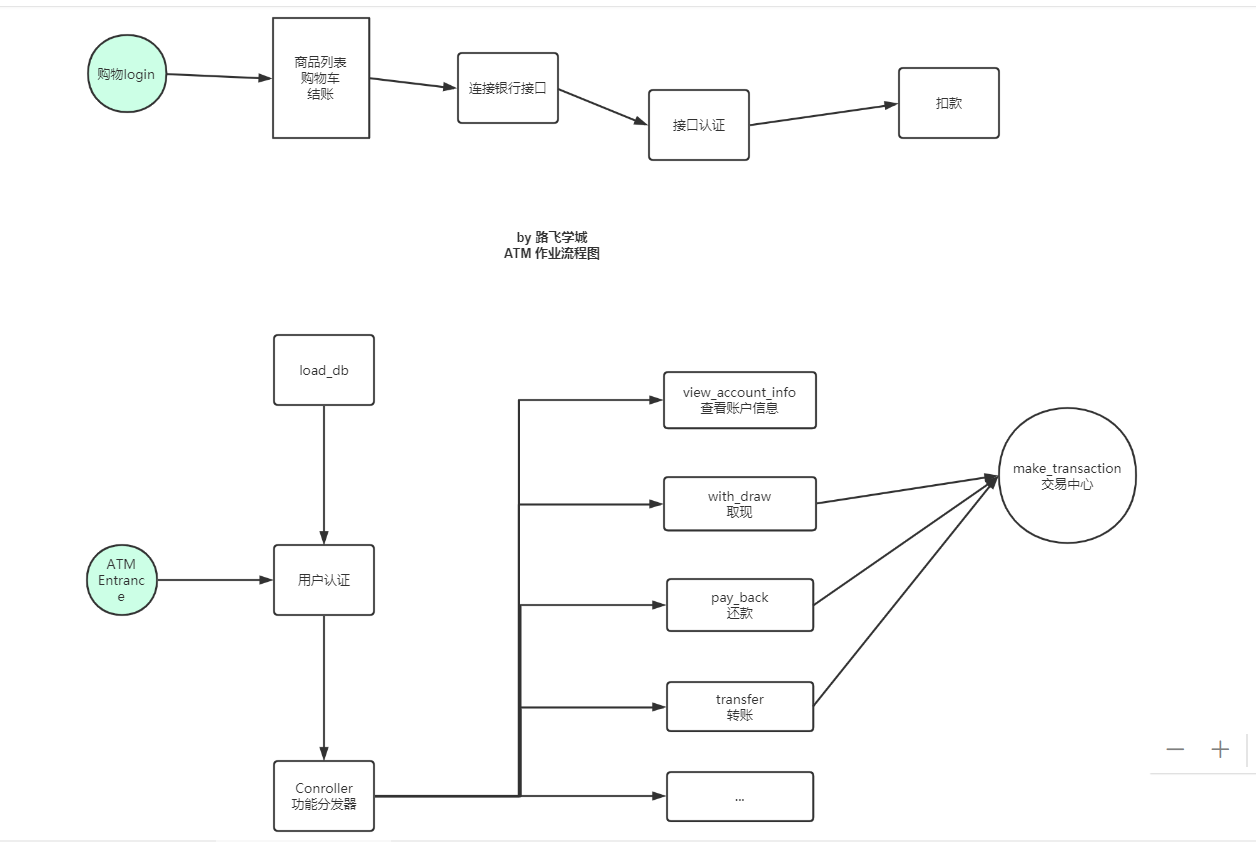
作业需求:
模拟实现一个ATM + 购物商城程序
-
额度 15000或自定义
-
实现购物商城,买东西加入 购物车,调用信用卡接口结账
-
可以提现,手续费5%
-
每月22号出账单,每月10号为还款日,过期未还,按欠款总额 万分之5 每日计息
-
支持多账户登录
-
支持账户间转账
-
记录每月日常消费流水
-
提供还款接口
-
ATM记录操作日志
-
提供管理接口,包括添加账户、用户额度,冻结账户等。。。
-
用户认证用装饰器
README
https://github.com/triaquae/py3_training/tree/master/atm
作者:Alex Li
版本:示例版本 v0.1
程序介绍:
实现ATM常用功能
功能全部用python的基础知识实现,用到了time\os\sys\json\open\logging\函数\模块知识, 主要帮给大家一个简单的模块化编程的示例
注意:只实现了"还款"和"取现功能"
程序结构:
day5-atm/
├── README
├── atm #ATM主程目录
│ ├── __init__.py
│ ├── bin #ATM 执行文件 目录
│ │ ├── __init__.py
│ │ ├── atm.py #ATM 执行程序
│ │ └── manage.py #ATM 管理端,未实现
│ ├── conf #配置文件
│ │ ├── __init__.py
│ │ └── settings.py
│ ├── core #主要程序逻辑都 在这个目录 里
│ │ ├── __init__.py
│ │ ├── accounts.py #用于从文件里加载和存储账户数据
│ │ ├── auth.py #用户认证模块
│ │ ├── db_handler.py #数据库连接引擎
│ │ ├── logger.py #日志记录模块
│ │ ├── main.py #主逻辑交互程序
│ │ └── transaction.py #记账\还钱\取钱等所有的与账户金额相关的操作都 在这
│ ├── db #用户数据存储的地方
│ │ ├── __init__.py
│ │ ├── account_sample.py #生成一个初始的账户数据 ,把这个数据 存成一个 以这个账户id为文件名的文件,放在accounts目录 就行了,程序自己去会这里找
│ │ └── accounts #存各个用户的账户数据 ,一个用户一个文件
│ │ └── 1234.json #一个用户账户示例文件
│ └── log #日志目录
│ ├── __init__.py
│ ├── access.log #用户访问和操作的相关日志
│ └── transactions.log #所有的交易日志
└── shopping_mall #电子商城程序,需单独实现
└── __init__.py
