

2 数据类型
import,先从当前目录找,然后sys.path查看标准库和第三方库。
1.1 sys
sys_mod.py
import sys #print(sys.path) # 打印环境变量 print(sys.argv) # 打印相对路径(pycharm显示绝对路径) print(sys.argv[2]) # 打印索引为2的参数
cmd内sys_mod.py上级目录执行:python sys_mod.py 1 2 3
'F:\python\lib\site-packages'
F:\python\Lib
1.2 os 文件/目录方法
os 模块提供了非常丰富的方法用来处理文件和目录
import os
#cmd_res = os.system("dir") #执行命令,不保存结果
# popen()可保存结果,需调用read()
cmd_res = os.popen("dir").read() #read()调用内存结果,不加则只显示内存对象地址
print("-->",cmd_res)
os.mkdir("new_dir") #创建文件夹
创建模块
login.py
_username = 'arfu'
_password = '123456'
username = input("username: ")
#password = getpass.getpass("password:")
password = input("password: ")
if _username == username and _password == password:
print("Welcome user {name} login...".format(name=username))
else:
print("Invalid username or password!")
xxx.py
import login
login.py作为模块,可以是当前文件,或标准库或第三方库
1.3 pyc
1. Python是一门解释型语言?
我初学Python时,听到的关于Python的第一句话就是,Python是一门解释性语言,我就这样一直相信下去,直到发现了.pyc文件的存在。如果是解释型语言,那么生成的.pyc文件是什么呢?c应该是compiled的缩写才对啊!
为了防止其他学习Python的人也被这句话误解,那么我们就在文中来澄清下这个问题,并且把一些基础概念给理清。
2. 解释型语言和编译型语言
计算机是不能够识别高级语言的,所以当我们运行一个高级语言程序的时候,就需要一个“翻译机”来从事把高级语言转变成计算机能读懂的机器语言的过程。这个过程分成两类,第一种是编译,第二种是解释。
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。最典型的例子就是C语言。
解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行,最典型的例子是Ruby。
通过以上的例子,我们可以来总结一下解释型语言和编译型语言的优缺点,因为编译型语言在程序运行之前就已经对程序做出了“翻译”,所以在运行时就少掉了“翻译”的过程,所以效率比较高。但是我们也不能一概而论,一些解释型语言也可以通过解释器的优化来在对程序做出翻译时对整个程序做出优化,从而在效率上超过编译型语言。
此外,随着Java等基于虚拟机的语言的兴起,我们又不能把语言纯粹地分成解释型和编译型这两种。
用Java来举例,Java首先是通过编译器编译成字节码文件,然后在运行时通过解释器给解释成机器文件。所以我们说Java是一种先编译后解释的语言。
3. Python到底是什么
其实Python和Java/C#一样,也是一门基于虚拟机的语言,我们先来从表面上简单地了解一下Python程序的运行过程吧。
当我们在命令行中输入python hello.py时,其实是激活了Python的“解释器”,告诉“解释器”:你要开始工作了。可是在“解释”之前,其实执行的第一项工作和Java一样,是编译。
熟悉Java的同学可以想一下我们在命令行中如何执行一个Java的程序:
javac hello.java
java hello
只是我们在用Eclipse之类的IDE时,将这两部给融合成了一部而已。其实Python也一样,当我们执行python hello.py时,他也一样执行了这么一个过程,所以我们应该这样来描述Python,Python是一门先编译后解释的语言。
4. 简述Python的运行过程
在说这个问题之前,我们先来说两个概念,PyCodeObject和pyc文件。
我们在硬盘上看到的pyc自然不必多说,而其实PyCodeObject则是Python编译器真正编译成的结果。我们先简单知道就可以了,继续向下看。
当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式
2数据类型
1、数字
2 是一个整数的例子。 长整数 不过是大一些的整数。 3.23和52.3E-4是浮点数的例子。E标记表示10的幂。在这里,52.3E-4表示52.3 * 10-4。 (-5+4j)和(2.3-4.6j)是复数的例子,其中-5,4为实数,j为虚数,数学中表示复数是什么?。
int(整型)
在32位机器上,整数的位数为32位,取值范围为-231~231-1,即-2147483648~2147483647 在64位系统上,整数的位数为64位,取值范围为-263~263-1,即-9223372036854775808~9223372036854775807
long(长整型)
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。 注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。 float(浮点型)
先扫盲 http://www.cnblogs.com/alex3714/articles/5895848.html ** ** 浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。 complex(复数) 复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
注:Python中存在小数字池:-5 ~ 257
2、布尔值
真或假
1 或 0
a = 0 if a:print(a) #为假不输出 a = 1 if a:print(a) #为真输出1
3 三元运算
result =` `值1if条件 else` `值2
如果条件为真:result = 值1 如果条件为假:result = 值2
a,b,c = 1,3,5 d = a if a >c else c print(d) # 结果为5 # 同: >>> if a >b:d=a ... else:a=c ... >>> a 1
4 bytes数据类型
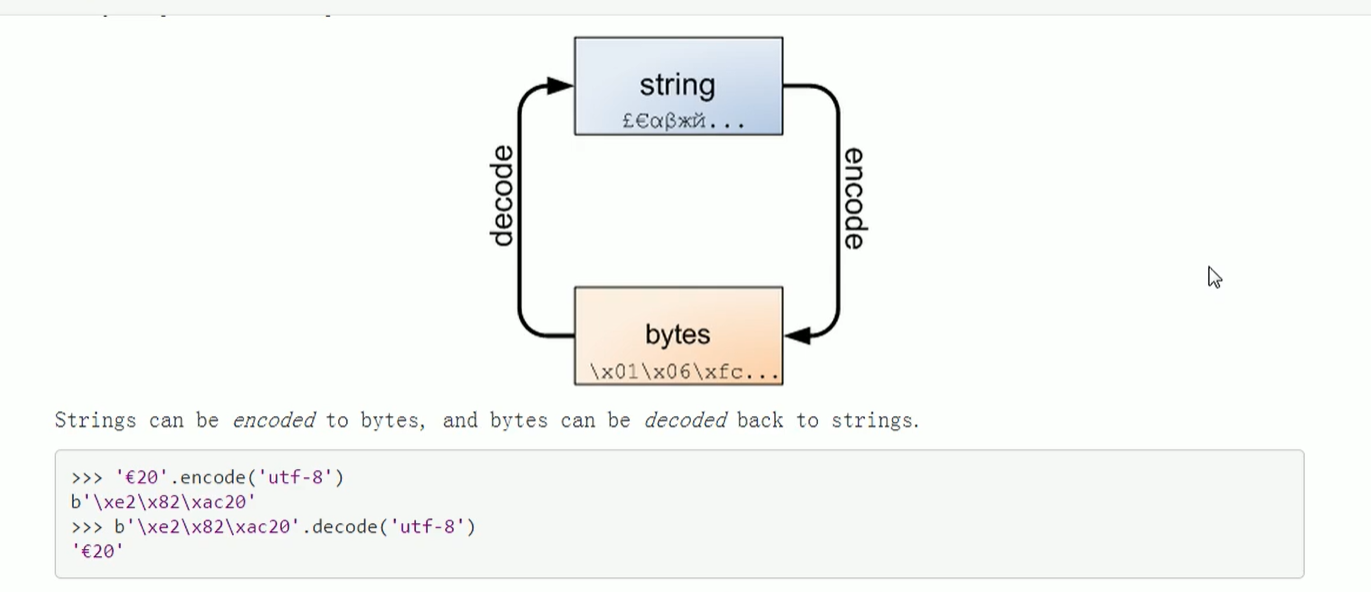
msg = "你好,世界" print(msg) print(msg.encode(encoding="utf-8")) print(msg.encode(encoding="utf-8").decode(encoding="utf-8"))
输出结果:
你好,世界 b'\xe4\xbd\xa0\xe5\xa5\xbd\xef\xbc\x8c\xe4\xb8\x96\xe7\x95\x8c' 你好,世界
3 列表、元组、字典、集合、函数
| 列表 | 备注 | |
|---|---|---|
| 创建 | List_one = [] List_one = list() | |
| 查询 | List_one[1:5:2] List_one[0] | |
| 排序 | List_one.sort() List_one.sort(key=len,reverse=True) List_two = sorted(List_one) List_one.reverse() | Sort(reverse=True)降序 按字符串的长度排序,降序 生成一个新列表 倒序排序 |
| 添加 | List_1.append(10) List_1.extend(list_2) List_1.insert(1,’d’) | Append(值) Extend(新列表) Insert(索引,’值’) |
| 删除 | Del List_one[1] List_one.remove(‘e’) List_one.pop(1) | |
| 修改 | Names[1] = ‘hello’ | |
| 嵌套 | List_one = [[],[],[]] |
| 元组 | ||
|---|---|---|
| 创建 | Tu_1 = () Tu_1 = tuple() | |
| 查询 | Print(tu_1[1]) Print(tu_1[0:3:2]) |
| 字典 | ||
|---|---|---|
| 创建 | Dict_1 = {‘姓名’:’张三’, ‘地址’:”大学路’} Dict_1 = dict(姓名=’李四’,地址=’大学路’) | Dict()出现重复键报错 |
| 访问 | Print(Dict_1[‘’姓名]) | |
| 添加 | Dict_1.update(姓名=’张三’) Dict_1[‘姓名’] = ‘王八’ | 若键存在则修改 |
| 查询 | Dict_1.items() Dict_1.keys() Dict_1.values() | 查询所有元素 |
| 删除 | Dict_1.pop(‘姓名’) Dict_1.popitem() Dict_1.clear() | 最后一位 |
| 集合 | ||
|---|---|---|
| 创建 | Set_1 = set([1,2,3,5]) Set_1 = {‘p’, ‘y’, ‘t’, ‘h’} Set_1 = frozenset((1,2,3,5)) | 不可变集合 |
| 操作 | Set_1.add(‘py’) Set_1.update(‘thon’) | |
| 删除 | Set_1.remove(‘o’) Set_1.discard(‘t’) Set_1.pop() Set_1.clear() | |
| 操作符 | Set_1 = {‘a’,’b’} set_2 = {‘b’,’c’} Result = set_1 | set_2 Result = set_1 & set_2 Result = set_1 - set_2 Result = set_1 ^ set_2 | | & - ^ 联合 交集 差补 对称差分 |
| 函数 | ||
|---|---|---|
| Def test(): | ||
| Def test1(date,temp,air): Print(f’日期:{date}’) Print(f’温度:{temp}’) Print(f’空气状况:{air}’) | ||
| 调用 | Test() Test1(‘2020年’,’20度’,’优’) |
3.1列表
列表方法
Python 有一组可以在列表上使用的内建方法。
| 方法 | 描述 |
|---|---|
| 在列表的末尾添加一个元素 | |
| 删除列表中的所有元素 | |
| 返回列表的副本 | |
| 返回具有指定值的元素数量。 | |
| 将列表元素(或任何可迭代的元素)添加到当前列表的末尾 | |
| 返回具有指定值的第一个元素的索引 | |
| 在指定位置添加元素 | |
| 删除指定位置的元素 | |
| 删除具有指定值的项目 | |
| 颠倒列表的顺序 | |
| 对列表进行排序 |
代码
names = ["A","B","C","D","E"]
#增
names.append("F")
names.insert(1,"G")
names.insert(3,"L")
names.insert(3,["word,hi"])
#改
names[2] = "GG"
print(names)
# print(names[0])
# print(names[1:3]) #切片
# print(names[:3]) #切片
# print(names[-3:]) #切片
# print(names[0:-1:2])
# print(names[::2])
#删
# names.remove("GG")
# del names[1] # =names.pop(1)
names.pop() #默认为最后一个
print(names)
#查找
print(names.index("E"))
print(names[names.index("E")])
#统计
print(names.count("G"))
#清除clear()
# names.clear()
# print(names)
#reverse()反转
names.reverse()
print(names,"reverse()方法")
#排序 符号>数字>大写字母>小写字母
names2 = ["#A","2B","1C","D","aE"]
names2.sort()
print(names2)
# 合并
names.extend(names2)
del names2
print(names)
copy()
import copy names = ["A","B","C",["word","hi"],"D","E"] # names2 = names.copy() # 浅copy第一层,二层copy内存地址 # names2 = copy.copy(names) # 同列表的copy(),浅copy names2 = copy.deepcopy(names) print(names) print(names2) names[2] = "你好" names[3][0] = "WORD" print(names) print(names2)
浅copy:
['A', 'B', 'C', ['word', 'hi'], 'D', 'E'] ['A', 'B', 'C', ['word', 'hi'], 'D', 'E'] ['A', 'B', '你好', ['WORD', 'hi'], 'D', 'E'] ['A', 'B', 'C', ['WORD', 'hi'], 'D', 'E']
深copy:
['A', 'B', 'C', ['word', 'hi'], 'D', 'E'] ['A', 'B', 'C', ['word', 'hi'], 'D', 'E'] ['A', 'B', '你好', ['WORD', 'hi'], 'D', 'E'] ['A', 'B', 'C', ['word', 'hi'], 'D', 'E']
补充:浅copy,联合账号
import copy person=['name',['saving',100]] #浅copy方法 """ p1=copy.copy(person) p2=person[:] p3=list(person) """ p1=person[:] p2=person[:] p1[0]='zhangsan' p2[0]='lisi' p1[1][1]=50 print(p1) print(p2)
list()
制作副本的另一种方法是使用内建的方法 list()。
实例
使用 list() 方法复制列表:
thislist = ["apple", "banana", "cherry"] mylist = list(thislist) print(mylist)
合并两个列表:
list1 = ["a", "b" , "c"] list2 = [1, 2, 3] list3 = list1 + list2 print(list3)
补充:
names = ["A","B","C",["word","hi"],"D","E"]
print(names[0:-1:2])
print(names[::2])
for i in names:
print(">>",i)
str = list(["1","2"])
str += "3"
str += [40]
print(str)
#['1', '2', '3', 40]
购物程序
需求:
-
启动后,让用户输入工资,然后打印商品列表
-
允许用户根据商品编号购买商品
-
用户选择商品后,检测余额是否够,够就直接扣款,不够则提醒
-
可随时退出,退出时,打印已购买商品的余额
product_list = [
('Iphone',5800),
('Mac Pro',9800),
('Bike',8000),
('Watch',10600),
('Coffee',31),
('Ar fu',1),
]
shopping_list = []
salary = input("input your salary:")
if salary.isdigit():
salary = int(salary)
while True:
for index,item in enumerate(product_list): # 取出下标
# print(product_list.index(item),item)
print(index,item)
user_choice =input("选择要买?>>>:")
if user_choice.isdigit():
user_choice = int(user_choice)
if user_choice < len(product_list) and user_choice >=0:
p_item = product_list[user_choice]
if p_item[1] <= salary: #买的起
shopping_list.append(p_item)
salary -= p_item[1]
print("Added %s into shopping cart,your current balance is \033[31;1m%s\033[0m" %(p_item,salary))
else:
print("\033[41;1m你的余额只剩[%s]啦,还买个毛线\033[0m")
else:
print("product code [%s] is not exist!"% user_choice)
elif user_choice == 'q':
print("----------shopping list---------")
for p in shopping_list:
print(p)
print("Your current halance:",salary)
exit()
else:
print("invalid option")
3.2元组
元组方法
Python 提供两个可以在元组上使用的内建方法。
| 方法 | 描述 |
|---|---|
| 返回元组中指定值出现的次数。 | |
| 在元组中搜索指定的值并返回它被找到的位置。 |
代码
元组(Tuple)
元组是有序且不可更改的集合。在 Python 中,元组是用圆括号编写的。
thistuple = ("apple", "banana", "cherry", "orange", "kiwi", "melon", "mango")
print(thistuple)
print(thistuple[1])
print(thistuple[-1])
print(thistuple[-4:-1])
把元组转换为列表即可进行更改:
x = ("apple", "banana", "cherry")
y = list(x)
y[1] = "kiwi"
x = tuple(y)
print(x)
#结果:('apple', 'kiwi', 'cherry')
单项元组,别忘了逗号:
thistuple = ("apple",)
print(type(thistuple))
#不是元组
thistuple = ("apple")
print(type(thistuple))
合并这个元组:
tuple1 = ("a", "b" , "c")
tuple2 = (1, 2, 3)
tuple3 = tuple1 + tuple2
print(tuple3)
tuple() 构造函数
也可以使用 tuple() 构造函数来创建元组。
实例
使用 tuple() 方法来创建元组:
thistuple = tuple(("apple", "banana", "cherry")) # 请注意双括号
print(thistuple)
3.3 字典
字典(Dictionary)
字典是一个无序、可变和有索引的集合。在 Python 中,字典用花括号编写,拥有键和值。
字典方法
Python 提供一组可以在字典上使用的内建方法。
| 方法 | 描述 |
|---|---|
| 删除字典中的所有元素 | |
| 返回字典的副本 | |
| 返回拥有指定键和值的字典 | |
| 返回指定键的值 | |
| 返回包含每个键值对的元组的列表 | |
| 返回包含字典键的列表 | |
| 删除拥有指定键的元素 | |
| 删除最后插入的键值对 | |
| 返回指定键的值。如果该键不存在,则插入具有指定值的键。 | |
| 使用指定的键值对字典进行更新 | |
| 返回字典中所有值的列表 |
代码
info = {
'001':"zhang san",
'002':"li si",
'003':"wang wu",
}
print(info)
#查
print(info['001']) #找不到key会报错
print(info.get('005')) #找不到返回None
#改
info['001'] = "zhao liu" #修改
info['004'] = "qian qi" # 无则添加
#del
# del info['004']
info.pop("004")
info.popitem()
#判断是否存在
print('001' in info) #info.has_key("001") in py2.x
print(info)
dict = {
"一":{
"桌子":["被子","盘子"],
"车":["镜子","油箱"]
},
"二":{
"卧室":["床","被子","桌子"],
"厅":["沙发","桌子","电视"]
}
}
print(dict["一"]["桌子"])
dict["一"]["桌子"][1] += "dog"
print(dict["一"]["桌子"])
print(dict.keys())
print(dict.values())
dict.setdefault("三",{"www.baidu.com":[1,2]}) # 有key二,直接返回,没有则添加后面的值
print(dict)
info = {
'001':"zhang san",
'002':"li si",
'003':"wang wu",
}
b = {
'001':"ar fu",
1:2,
3:4
}
info.update(b) # 有则更新,无则加入
# {'001': 'ar fu', '002': 'li si', '003': 'wang wu', 1: 2, 3: 4}
#fromkeys()
c = dict.fromkeys([6,7,8],[1,{"name":"ar fu"},11])
print(c)
c[7][1]['name'] = "ha ha" # 修改其中一个其他全改
print(c)
#items()
print(info.items()) # 返回包含每个键值对的元组的列表
#方法一
for i in info:
print(i,info[i])
#方法二
for k,v in info.items():
print(k,v)
三级菜单代码
data = {
'北京':{
"昌平":{
"沙河":["",""],
"天通宛":["链家地产","我爱我家"]
},
"朝阳":{
"望京":["奔驰","陌陌"],
"国贸":["CICC","HP"],
"东直门":["Advent","飞信"]
},
"海淀":{}
},
'山东':{
"德州":{},
"青岛":{},
"济南":{}
},
'广东':{
"东莞":{},
"中山":{},
"佛山":{}
}
}
exit_flag = False
while not exit_flag:
for i in data:
print(i)
choice = input("选择进入1》》:")
if choice in data:
while not exit_flag:
for i2 in data[choice]:
print("\t",i2)
choice2 = input("选择进入2》》:")
if choice2 in data[choice]:
while not exit_flag:
for i3 in data[choice][choice2]:
print("\t\t",i3)
choice3 = input("选择进入3》》:")
if choice3 in data[choice][choice2]:
for i4 in data[choice][choice2][choice3]:
print("\t\t\t",i4)
choice4 = input("最后一层,按b返回》》:")
if choice4 in data[choice][choice2][choice3]:
print("你选择的地址为:",choice,choice2,choice3,choice4)
if choice4 == "b":
pass
elif choice4 == "q":
exit_flag = True
if choice3 == "b":
break
elif choice3 == "q":
exit_flag = True
if choice2 == "b":
break
elif choice2 == "q":
exit_flag = True
4 字符串常用操作
4.1字符串方法
Python 有一组可以在字符串上使用的内建方法。
注释:所有字符串方法都返回新值。它们不会更改原始字符串。
| 方法 | 描述 |
|---|---|
| 把首字符转换为大写。 | |
| 把字符串转换为小写。 | |
| 返回居中的字符串。 | |
| 返回指定值在字符串中出现的次数。 | |
| 返回字符串的编码版本。 | |
| 如果字符串以指定值结尾,则返回 true。 | |
| 设置字符串的 tab 尺寸。 | |
| 在字符串中搜索指定的值并返回它被找到的位置。 | |
| 格式化字符串中的指定值。 | |
| format_map() | 格式化字符串中的指定值。 |
| 在字符串中搜索指定的值并返回它被找到的位置。 | |
| 如果字符串中的所有字符都是字母数字,则返回 True。 | |
| 如果字符串中的所有字符都在字母表中,则返回 True。 | |
| 如果字符串中的所有字符都是小数,则返回 True。 | |
| 如果字符串中的所有字符都是数字,则返回 True。 | |
| 如果字符串是标识符,则返回 True。 | |
| 如果字符串中的所有字符都是小写,则返回 True。 | |
| 如果字符串中的所有字符都是数,则返回 True。 | |
| 如果字符串中的所有字符都是可打印的,则返回 True。 | |
| 如果字符串中的所有字符都是空白字符,则返回 True。 | |
| 如果字符串遵循标题规则,则返回 True。 | |
| 如果字符串中的所有字符都是大写,则返回 True。 | |
| 把可迭代对象的元素连接到字符串的末尾。 | |
| 返回字符串的左对齐版本。 | |
| 把字符串转换为小写。 | |
| 返回字符串的左修剪版本。 | |
| maketrans() | 返回在转换中使用的转换表。 |
| 返回元组,其中的字符串被分为三部分。 | |
| 返回字符串,其中指定的值被替换为指定的值。 | |
| 在字符串中搜索指定的值,并返回它被找到的最后位置。 | |
| 在字符串中搜索指定的值,并返回它被找到的最后位置。 | |
| 返回字符串的右对齐版本。 | |
| 返回元组,其中字符串分为三部分。 | |
| 在指定的分隔符处拆分字符串,并返回列表。 | |
| 返回字符串的右边修剪版本。 | |
| 在指定的分隔符处拆分字符串,并返回列表。 | |
| 在换行符处拆分字符串并返回列表。 | |
| 如果以指定值开头的字符串,则返回 true。 | |
| 返回字符串的剪裁版本。 | |
| 切换大小写,小写成为大写,反之亦然。 | |
| 把每个单词的首字符转换为大写。 | |
| translate() | 返回被转换的字符串。 |
| 把字符串转换为大写。 | |
| 在字符串的开头填充指定数量的 0 值。 |
注释:所有字符串方法都返回新值。它们不会更改原始字符串。
代码
name = "my \tname is ar fu name"
name2 = "my \tname is {name} and i am {year}"
print(name.capitalize()) #首字符转换为大写
print(name.count("a"))
print(name.casefold()) #把字符串转换为小写。
print(name.encode()) #转化位二进制
print(name.center(50,"-")) #返回字符串居中,并使用空格填充至长度 width 的新字符串。默认填充字符为空格。
print(name.endswith("fu")) # 如果字符串以指定值结尾,则返回 true。
print(name.expandtabs(tabsize=20)) # 设置字符串的 tab 尺寸。
print(name.find('name'))
print(name.rfind('name'))
print(name[name.find("name"):]) #在字符串中搜索指定的值并返回它被找到的位置。
print(name2.format(name='arfu',year=23))
print(name2.format_map( {'name':'arfu','year':'23'} ))
print("ab123".isalnum()) #如果字符串中的所有字符都是字母数字,则返回 True
print("ab".isalpha()) #如果字符串中的所有字符都在字母表中,则返回 True
print("1.223".isdecimal()) #如果字符串中的所有字符都是小数,则返回 True
print("123".isdigit()) #如果字符串中的所有字符都是数字,则返回 True
print()
print("1a".isidentifier()) # 如果字符串是标识符,则返回 True
print("33A".isnumeric()) #如果字符串中的所有字符都是数,则返回 True。
print(" ".isspace()) #如果字符串中的所有字符都是空白字符,则返回 True
print('My Name Is'.istitle()) #如果字符串遵循标题规则,则返回 True。
print()
print('My Name Is'.isprintable()) #如果字符串中的所有字符都是可打印的,则返回 True
print('My Name Is'.isupper()) #如果字符串中的所有字符都是大写,则返回 True。
print('abc'.islower()) #如果字符串中的所有字符都是小写,则返回 True。
print('+'.join(['1','2','3'])) #把可迭代对象的元素连接到字符串的末尾。
print('name'.ljust(10,'*')) #返回字符串的左对齐版本。不够10用*补齐
print('name'.rjust(10,'-')) #
print('Arfu'.lower()) # 把字符串转换为小写。
print('Arfu'.upper()) #把字符串转换为大写。
print('\nArfu'.lstrip())
print('Arfu\n'.rstrip())
print('Arfu'.strip())
p = str.maketrans("abcdefg",'1234567') #返回在转换中使用的转换表。
print('arfu'.translate(p)) #返回被转换的字符串。
txt = "I could eat bananas all day, bananas are my favorite fruit"
print(txt.partition("bananas")) #partition() 方法搜索指定的字符串,并将该字符串拆分为包含三个元素的元组。
print(txt.rpartition("bananas")) #从右开始指定字符串,并将该字符串拆分为包含三个元素的元组。
print('1+2+3+4'.split('+'))
print('1+2 \n+3 \n+4'.rsplit(' ',1)) #在换行符处拆分字符串并返回列表。
print('1+2\n+3\n+4'.splitlines()) #在换行符处拆分字符串并返回列表。
print('1+2\n+3\n+4'.splitlines(True)) #在换行符处拆分字符串并返回列表。保留分隔符
print('Ar fu'.swapcase()) #切换大小写,小写成为大写,反之亦然。
print('ar fu'.title()) # 把每个单词的首字符转换为大写。
print('ar fu'.zfill(10)) #在字符串的开头填充指定数量的 0 值。
