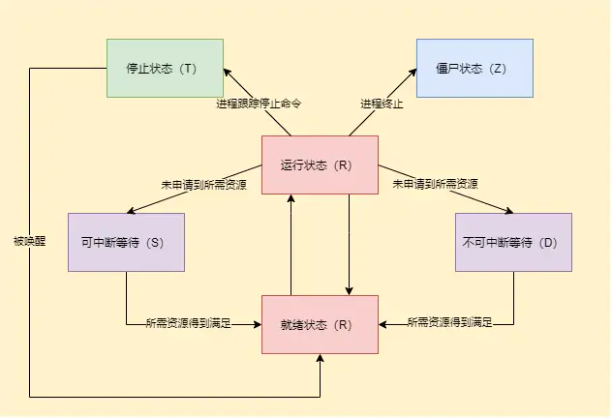
进程
二者区别:
1 #include<stdio.h> 2 3 int main(int argc, char** argv, char** env) 4 { 5 int i = 0; 6 while(env[i] != NULL) 7 { 8 printf("%s\n", env[i++]); 9 } 10 return 0; 11 }
1 #include<stdio.h> 2 3 int main(int argc, char** argv, char** env) 4 { 5 extern char** environ; 6 int i = 0; 7 while(environ[i] != NULL) 8 { 9 printf("%s\n", environ[i++]); 10 } 11 return 0; 12 }
char *getenv(const char *name);
参数说明:
返回值:
int setenv(const char *name, const char *value, int overwrite);
参数说明:
返回值:
int unsetenv(const char *name);
参数说明:
返回值:
#include<unistd.h> int getuid(); //获取进程的实际用户ID。 int geteuid(); //获取进程的有效用户ID。 int getgid(); //获取进程的用户所属的实际用户组ID。 int getegid(); //获取进程的用户所属的有效用户组ID。 int getpid(); //获取当前进程的ID。 int getppid(); //获取父进程的ID
1 #include<stdio.h> 2 #include<unistd.h> 3 4 int main(int argc, char** argv) 5 { 6 printf("uid = %d\n", getuid()); 7 printf("euid = %d\n", geteuid()); 8 printf("gid = %d\n", getgid()); 9 printf("egid = %d\n", getegid()); 10 return 0; 11 }
$ gcc test.c //编译 $ sudo chown root:root a.out //修改所有者 $ sudo chmod u+s g+s a.out //添加suid位和sgid位 $ ./a.out //运行 uid = 1000 euid = 0 gid = 1000 egid = 0
#include <unistd.h> pid_t fork(void);
返回值:
案例1:
1 #include<stdio.h> 2 #include<unistd.h> 3 4 int main(int argc, char** argv) 5 { 6 printf("main process id = %d\n", getpid()); 7 pid_t pid = fork(); 8 if(pid == -1) 9 { 10 perror("fork"); 11 return -1; 12 } 13 else if(pid == 0) 14 { 15 printf("child process id = %d, parent id = %d\n", 16 getpid(), getppid()); 17 } 18 else 19 { 20 sleep(1); 21 printf("main process id = %d\n", getpid()); 22 } 23 return 0; 24 }
main process id = 5504 child process id = 5505, parent id = 5504 main process id = 5504
案例2:
1 #include<stdio.h> 2 #include<unistd.h> 3 4 int main(int argc, char** argv) 5 { 6 printf("main process id = %d\n", getpid()); 7 pid_t pid = fork(); 8 if(pid == -1) 9 { 10 perror("fork"); 11 return -1; 12 } 13 else if(pid == 0) 14 { 15 int i = 0; 16 while(i++ < 10) 17 { 18 printf("child process id = %d, i = %d\n", getpid(), i); 19 sleep(1); 20 } 21 } 22 else 23 { 24 int i = 0; 25 while(i++ < 10) 26 { 27 printf("main process id = %d, i = %d\n", getpid(), i); 28 sleep(1); 29 } 30 } 31 printf("process end, pid = %d\n", getpid()); 32 return 0; 33 }
main process id = 5632 main process id = 5632, i = 1 child process id = 5633, i = 1 main process id = 5632, i = 2 child process id = 5633, i = 2 ... main process id = 5632, i = 10 child process id = 5633, i = 10 process end, pid = 5632 process end, pid = 5633
案例3:
1 #include<stdio.h> 2 #include<unistd.h> 3 #include<fcntl.h> 4 #include<sys/stat.h> 5 6 int main(int argc, char** argv) 7 { 8 int fd = open("log", O_RDWR); 9 if(fd == -1) 10 { 11 perror("open"); 12 return -1; 13 } 14 15 pid_t pid = fork(); 16 if(pid == -1) 17 { 18 perror("fork"); 19 return -1; 20 } 21 else if(pid == 0) 22 { 23 char buf[32] = {0}; 24 int nRet = read(fd, buf, 5); 25 buf[nRet] = '\0'; 26 printf("read : %s, lseek = %ld\n", buf, lseek(fd, 0, SEEK_CUR)); 27 } 28 else 29 { 30 sleep(1); 31 char buf[32] = {0}; 32 int nRet = read(fd, buf, 5); 33 buf[nRet] = '\0'; 34 printf("read : %s, lseek = %ld\n", buf, lseek(fd, 0, SEEK_CUR)); 35 } 36 return 0; 37 }
$ cat log 0123456789abcedf $ ./a.out pid = 6076, read : 01234, lseek = 5 pid = 6075, read : 56789, lseek = 10
#include <stdlib.h> void exit(int status);
参数说明:
其他:
案例:
1 #include<stdio.h> 2 #include<stdlib.h> 3 4 void my_exit() 5 { 6 printf("my_exit\n"); 7 } 8 9 int main(int argc, char** argv) 10 { 11 //注册退出函数 12 if(atexit(my_exit) != 0) 13 printf("can't register my_exit\n"); 14 15 printf("main is done!\n"); 16 return 0; 17 }
main is done! my_exit
1 #include<stdio.h> 2 #include<unistd.h> 3 4 int main(int argc, char** argv) 5 { 6 pid_t pid = fork(); 7 if(pid == -1) 8 { 9 perror("fork"); 10 return -1; 11 } 12 else if(pid == 0) 13 { 14 sleep(2); 15 printf("pid = %d, child process is done\n", getpid()); 16 } 17 else 18 { 19 printf("main process\n"); 20 sleep(60); 21 } 22 }
main process pid = 6972, child process is done
$ ps -aux ... test 6939 0.0 0.1 13956 5120 pts/1 Ss 17:36 0:00 bash test 6971 0.0 0.0 2496 508 pts/0 S+ 17:39 0:00 ./a.out test 6972 0.0 0.0 0 0 pts/0 Z+ 17:39 0:00 [a.out] <defunct> test 6973 0.0 0.0 14780 3520 pts/1 R+ 17:39 0:00 ps -aux
#include <sys/wait.h> pid_t wait(int *status);
参数说明:
返回值:
用于检查子进程退出的宏定义:
WIFEXITED(status) //通过系统调用_exit或exit()函数退出,该值为真 WIFSIGNALED(status) //由信号(signal)导致退出时,该值为真 WEXITSTATUS(status) //如果 WIFEXITED 为真,该宏获取 exit 设置的退出码 WTERMSIG(status) //如果 WIFSIGNALED 为真,该宏获取具体信号值
案例:
1 #include<stdio.h> 2 #include<unistd.h> 3 #include<sys/wait.h> 4 #include<stdlib.h> 5 6 int main(int argc, char** argv) 7 { 8 printf("main process id = %d\n", getpid()); 9 10 pid_t pid = fork(); 11 if(pid == -1) 12 { 13 perror("fork"); 14 return -1; 15 } 16 else if(pid == 0) 17 { 18 for(int i = 0; i < 10; i++) 19 { 20 printf("child process %d, id = %d\n", i, getpid()); 21 sleep(1); 22 } 23 exit(10); 24 } 25 else 26 { 27 int status; 28 int pid = wait(&status); 29 if(WIFEXITED(status)) 30 { 31 printf("child process has exit by exit code : %d\n", WEXITSTATUS(status)); 32 } 33 else if(WIFSIGNALED(status)) 34 { 35 printf("child process has exit by signal : %d\n", WTERMSIG(status)); 36 } 37 sleep(20); 38 } 39 40 return 0; 41 }
main process id = 9058 child process 0, id = 9059 child process 1, id = 9059 ... child process 9, id = 9059 child process has exit by exit code : 10
$ ps -aux test 9058 0.0 0.0 2496 512 pts/0 S+ 10:02 0:00 ./a.out test 9059 0.0 0.0 2496 84 pts/0 S+ 10:02 0:00 ./a.out
$ ps -aux test 9058 0.0 0.0 2496 512 pts/0 S+ 10:02 0:00 ./a.out
$ ./a.out
$ kill -9 9068
main process id = 9067 child process 0, id = 9068 child process 1, id = 9068 child process 2, id = 9068 child process 3, id = 9068 child process 4, id = 9068 child process has exit by signal : 9
#include <sys/types.h> #include <sys/wait.h> pid_t waitpid(pid_t pid, int *status, int options);
参数说明:
返回值:
用于检查子进程退出的宏定义:
WIFEXITED(status) //通过系统调用_exit或exit()函数退出,该值为真 WIFSIGNALED(status) //由信号(signal)导致退出时,该值为真 WIFSTOPPED(status) //指定了 WUNTRACED 选项且进程被暂停时,该值为真 WIFCONTINUED(status) //指定了 WCONTINUED 选项且子进程由停止态转为就绪态,该值为真 WEXITSTATUS(status) //如果 WIFEXITED 为真,该宏获取 exit 设置的退出码 WTERMSIG(status) //如果 WIFSIGNALED 为真,该宏获取具体信号值 WSTOPSIG(status) //如果 WIFSTOPPED 为真,该宏获取导致子进程停止的信号
#include <unistd.h> int execl(const char* path, const char *arg, ...); int execlp(const char* file, const char *arg, ...); int execle(const char* path, const char *arg, ..., char * const envp[]); int execv(const char* path, char* const argv[]); int execvp(const char* file, char * const argv[]); int execve(const char* filename, char* const argv[], char* const envp[]);
案例:
1 #include<stdio.h> 2 #include<unistd.h> 3 4 int main(int argc, char** argv) 5 { 6 printf("main process id = %d\n", getpid()); 7 execlp("/bin/ls", "ls", "-la", "./", NULL); 8 printf("main end!\n"); 9 return 0; 10 }
$ ./a.out main process id = 9824 总用量 32 drwxrwxr-x 2 test test 4096 12月 8 14:44 . drwxrwxr-x 3 test test 4096 12月 7 10:19 .. -rwxrwxr-x 1 test test 16824 12月 8 14:44 a.out -rw-rw-r-- 1 test test 449 12月 8 14:44 test.c

 浙公网安备 33010602011771号
浙公网安备 33010602011771号