目标检测—Faster R-CNN详解
Faster R-CNN是继R-CNN,Fast R-CNN后基于Region-CNN的又一目标检测力作。Faster R-CNN发表于NIPS 2015。即便是2015年的算法,在现在也仍然有着广泛的应用以及不俗的精度。缺点是速度较慢,无法进行实时的目标检测。
Faster R-CNN是典型的two-stage目标检测框架,即先生成区域提议(Region Proposal),然后在产生的Region Proposal上做分类和回归。相较于前作R-CNN和Fast R-CNN,Faster R-CNN的改进主要在于区域提议方面,使用区域提议网络(Region Proposal Network, RPN)提供区域建议,取代了选择性搜索。RPN是全卷积神经网络,并与检测网络共享图像的卷积特征,减少了区域提议的计算开销。也就是说,可以将Faster R-CNN 看作是 RPN + Fast R-CNN。
Faster R-CNN的网络示意如下图。
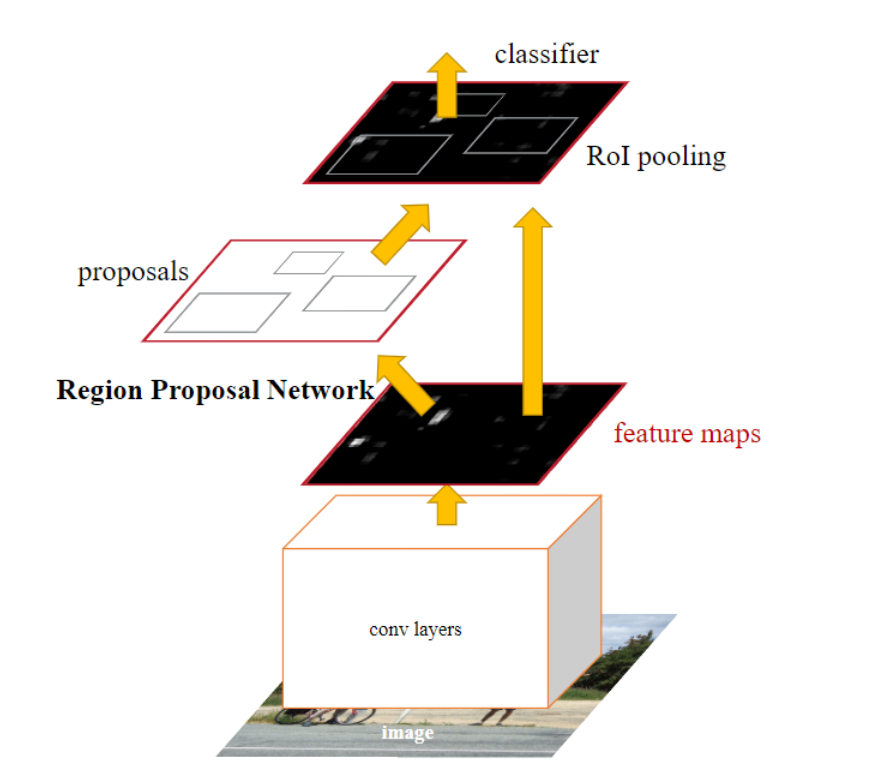
学习Faster R-CNN目标检测框架,对于目标检测任务的熟悉和进一步研究有着非常大的帮助,接下来将主要通过Faster R-CNN的训练和推理过程,学习它的网络结构等内容。
Faster R-CNN 网络结构
Dataset
在提及Faster R-CNN框架前,首先还是要简单说明一下目标检测数据集。以Pascal VOC数据集为例,该数据集的一组数据包括一张图片,一个对应的xml标注文件。用于目标检测任务时,需要关注object标签内的标注信息,一般使用到的是:
bndbox,目标包围框的坐标;
difficult,目标是否难以识别;
name,目标的类别;
在构建自定义Dataset时,往往会将图片image转换成Tensor格式,标签target则处理成Tensor的字典。
Generator Transform
由于目标检测数据集的特殊性(每张图片大小不一,图片内目标的个数和大小也各不相同),在送入网络前,需要进行数据处理。
-
记录一个batch内图像(Tensor列表)以及目标边界框的原始尺寸,用于后处理(post process)。
-
对图像进行标准化处理(normalization),然后将图像及其目标框按照边长等比例缩放,记录缩放后尺寸。
将图像按照边长等比例缩放时,这一个batch内的图像的长宽只有一个对齐,而送入网络时需要尺寸均一致的张量,因此还需继续处理。
-
将上述batch内图像调整至统一的尺寸(冗余部分用0填充),得到完整的Tensor。
-
将打包好的图片Tensor以及缩放后的尺寸打包至ImageList类中。
Feature
将ImageList中的图像Tensor送入骨干网络进行特征提取。在论文中使用的模型是VGG,取单层特征图进行目标检测。现在比较经典的神经网络是ResNet结合特征金字塔网络(Feature Pyramid Network, FPN),得到图像的多尺度语义特征图,可以获得更高的目标检测精度。
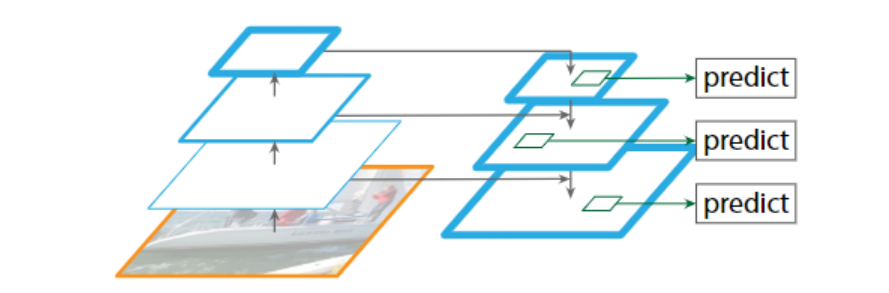
经过特征提取后,得到一个有序字典features,字典的key为特征层的id,value为图像在该层的特征图。然后Faster R-CNN在每一个特征层上进行预测。
Region Proposals Network
将ImageList,features,以及标签targets(目标边界框)传入RPN网络。
Anchor Generator
在features的每个feature map中,每一个cell都生成k个锚框(anchor boxes)。这k个锚框由不同的尺寸和纵横比组成,一般将尺寸设置为 $ {128^2, 256^2, 512^2} $ ,纵横比为 $ {1:1, 1:2, 2:1} $,即k=9个anchors。
使用AnchorGenerator类生成锚框,forward代码如下,是anchors生成的过程。
def forward(self, image_list, feature_maps):
# type: (ImageList, List[Tensor]) -> List[Tensor]
grid_sizes = list([feature_map.shape[-2:] for feature_map in feature_maps])
image_size = image_list.tensors.shape[-2:]
dtype, device = feature_maps[0].dtype, feature_maps[0].device
# one step in feature map equate n pixel stride in origin image
strides = [[torch.tensor(image_size[0] // g[0], dtype=torch.int64, device=device),
torch.tensor(image_size[1] // g[1], dtype=torch.int64, device=device)] for g in grid_sizes]
# 根据sizes和aspect_ratios生成anchors模板列表,len(list)=len(sizes)
# [Tensor:(3, 4), ...] Tensor.shape = (len(aspect_ratios), 4)
self.set_cell_anchors(dtype, device)
# 得到list列表,对应每张预测特征图映射回原图的anchors坐标信息
# 通过特征图尺寸以及stride得到原图基准坐标,再与anchors模板坐标相加
anchors_over_all_feature_maps = self.cached_grid_anchors(grid_sizes, strides)
anchors = torch.jit.annotate(List[List[torch.Tensor]], [])
# 遍历一个batch中的每张图像
for i, (image_height, image_width) in enumerate(image_list.image_sizes):
anchors_in_image = []
# 遍历每张预测特征图映射回原图的anchors坐标信息
for anchors_per_feature_map in anchors_over_all_feature_maps:
anchors_in_image.append(anchors_per_feature_map)
anchors.append(anchors_in_image)
# 将每一张图像的所有预测特征层的anchors坐标信息拼接在一起
# anchors是个list,len(anchors)=batch,每个元素为一张图像的所有anchors
anchors = [torch.cat(anchors_per_image) for anchors_per_image in anchors]
self._cache.clear()
return anchorsRPN Head
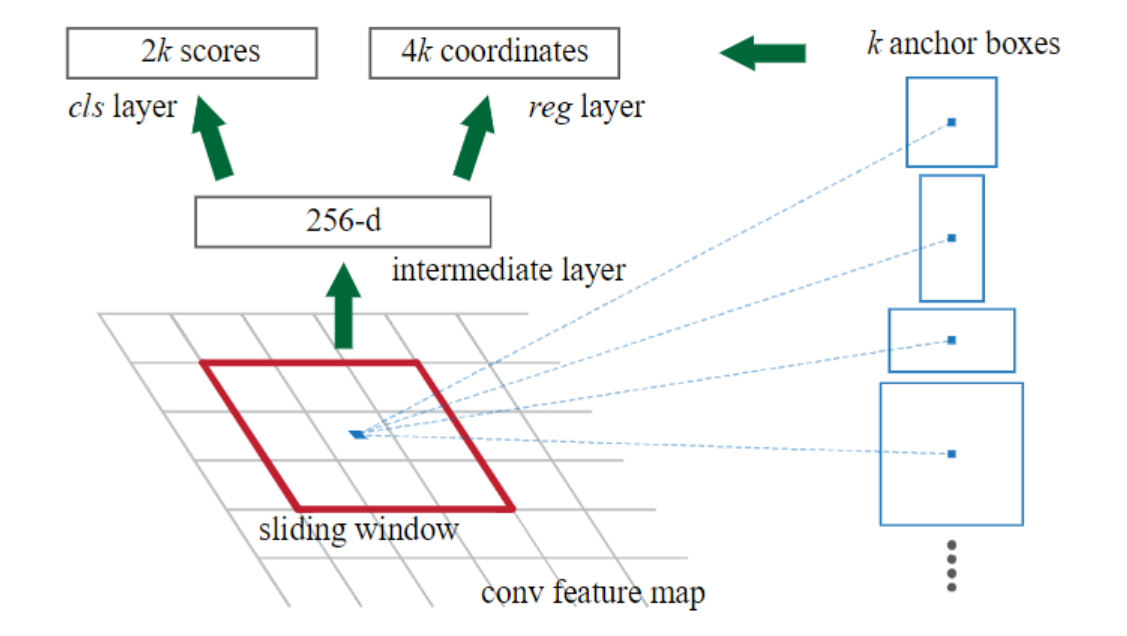
在RPN网络头部,先通过3x3的滑动窗口对每一个cell进一步提取特征,用于生成区域建议。
然后并行地连接两个全连接层(1x1大小的卷积层),cls layer 和 reg layer。分别预测每个cell生成anchor的类别分数(只关心是前景还是背景,输出特征维度为2k)和坐标(输出特征维度为4k)。
注:在论文中cls layer 预测2k个分数。在源码实现上,可以只预测k个分数,使用二至交叉熵计算损失,后续在损失计算时会再次提及。
经过PRN Head计算以后,得到两个结果:
-
objectness (box_cls),表示预测的每个anchor的类别分数。是len(objectness) = len(features)的列表,列表的每个元素是(B, K, H, W)的Tensor。
-
pred_bbox_deltas (box_regression),为预测的每个anchor的回归参数。是len(objectness) = len(features)的列表,列表的每个元素是(B, 4*K, H, W)的Tensor。
即经过RPN Head计算以后,我们得到了每个特征层下的预测分数以及预测回归参数。在进一步处理前,需要调整一下形状。
-
objectiness,Tensor(num_anchors, 1)
-
pred_bbox_deltas, Tensor(num_anchors, 4)
Box Coder Decode
然后将预测的回归参数(rel_codes)和锚框(boxes)进行编解码,得到最终的proposals。
$ x $, $ x_a $,and $ x^* $ are perdictied box, anchor box, and ground-truth box.
回归参数的计算公式如下。同样我们可以通过回归参数以及anchor box推导出计算ground truth box。
t_x = (x − x_a)/w_a, \ \ t_y = (y − y_a)/h_a, \\ t_w = log(w/w_a), \ \ t_h = log(h/h_a),\\ t^∗_x = (x^∗ − x_a)/w_a, \ \ t^∗_y = (y^∗ − y_a)/h_a,\\ t^∗_w = log(w^∗/w_a), \ \ t^∗_h = log(h^∗/h_a),
$$
在具体实现中,
首先根据anchors的坐标(xmin,ymin,xmax,ymax),得到中心点坐标以及宽高。
widths = boxes[:, 2] - boxes[:, 0] # anchor/proposal宽度
heights = boxes[:, 3] - boxes[:, 1] # anchor/proposal高度
ctr_x = boxes[:, 0] + 0.5 * widths # anchor/proposal中心x坐标
ctr_y = boxes[:, 1] + 0.5 * heights # anchor/proposal中心y坐标然后根据rel_codes得到相应的回归参数。
wx, wy, ww, wh = self.weights # RPN中为[1,1,1,1], fastrcnn中为[10,10,5,5]
dx = rel_codes[:, 0::4] / wx # 预测anchors/proposals的中心坐标x回归参数
dy = rel_codes[:, 1::4] / wy # 预测anchors/proposals的中心坐标y回归参数
dw = rel_codes[:, 2::4] / ww # 预测anchors/proposals的宽度回归参数
dh = rel_codes[:, 3::4] / wh # 预测anchors/proposals的高度回归参数
dw = torch.clamp(dw, max=self.bbox_xform_clip)
dh = torch.clamp(dh, max=self.bbox_xform_clip)根据回归参数以及anchor box坐标由最上边的公式逆推,得到proposals的坐标。
pred_ctr_x = dx * widths[:, None] + ctr_x[:, None]
pred_ctr_y = dy * heights[:, None] + ctr_y[:, None]
pred_w = torch.exp(dw) * widths[:, None]
pred_h = torch.exp(dh) * heights[:, None]
# xmin
pred_boxes1 = pred_ctr_x - torch.tensor(0.5,) * pred_w
# ymin
pred_boxes2 = pred_ctr_y - torch.tensor(0.5,) * pred_h
# xmax
pred_boxes3 = pred_ctr_x + torch.tensor(0.5,) * pred_w
# ymax
pred_boxes4 = pred_ctr_y + torch.tensor(0.5,) * pred_h这样我们得到了proposals,并调整至shape=(batch, num_anchors_per_img, 4)。
Filter Proposals
在之前的步骤中,我们生成了大量的proposals(10000个以上)。显然这么多proposals是不必要的,因此我们在这里要滤除大量的proposals,只留下2000个proposals。
根据objectness得分,进行top_n运算,获取每个特征图上预测概率排名靠前(pre_nms_top_n)的索引。
根据得到的索引,将objectness更新,仅保留索引处的概率信息。并通过sigmoid函数,将objectness预测值处理成概率形式。
最后我们遍历每个batch:
-
调整预测的bounding box坐标,将越界坐标调整至图片边界。
-
滤除面积过小的bounding box(将高宽不满足min_size的box剔除)。
-
移除小概率的bounding box(将概率小于score_threshold的box剔除)。
-
非极大值抑制。
-
返回处理剩余的前top_n个proposals。
这样,得到我们最终的proposals和对应的scores。
ROI
在经过RPN后,我们得到了2000个proposals。接下来将通过ROI (Region of Interest)进一步提取骨干网络的特征,得到proposals的回归参数以及分类类别。
在训练模式下,需要对proposals划分正负样本。这个放到后续损失计算部分再讲。
ROI Pooling (Align)
将features,proposals,image_shapes传入至ROI Poooing层。在最初版本的Faster R-CNN中,是使用的ROI Pooling。在后续改进中(Mask R-CNN)将这一步换成了 MultiScaleRoIAlign。
官方示例如下
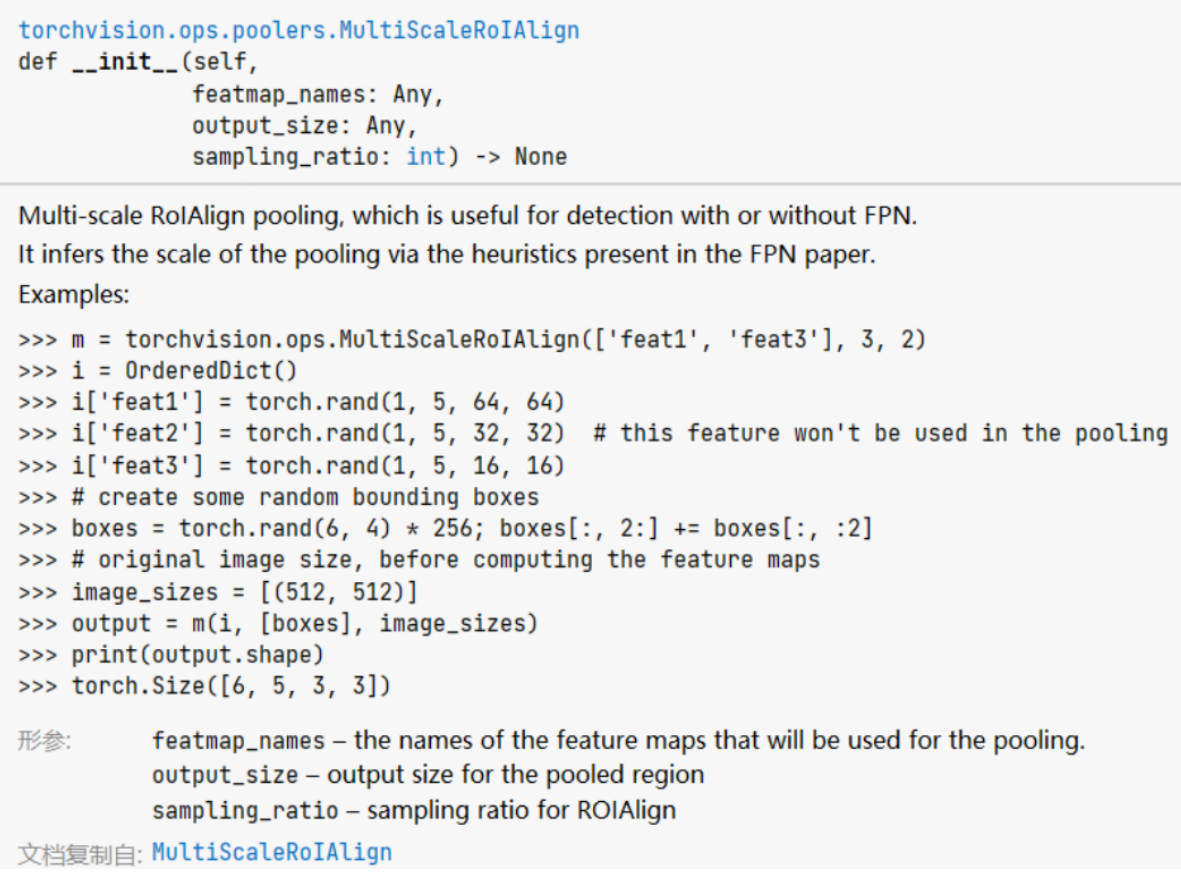
Faster R-CNN的ROI Pooling将backbone得到的多尺度features池化为若干7x7大小的特征图。在Faster R-CNN中,得到的池化后的特征图尺寸为(1024, 256, 7, 7)。1024为一个batch内proposals的个数,256为backbone的intermediate channels。
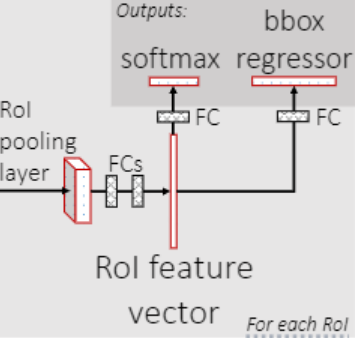
Two MLP Head
得到池化特征后,送入由两个全连接层构成的多层感知机,层间使用ReLU函数激活,用于进一步提取特征。第一个全连接层将池化特征的维度从intermediate size投射至representation size,第二个全连接层投射维度不变。
最终得到了(num_proposals, representation_size)的特征图。
Predictor
在 Fast R-CNN Predictor阶段,就负责对Proposals进行预测。
一个全连接层负责预测proposals的类别, ($ channels \to num\_classes $) 。
一个全连接层负责预测proposals的坐标回归参数, ($ channels \to num\_classes \times 4 $) 。
即得到class_logits, box_regression。
如果是训练模式,将预测的结果与此前的样本(labels,regression_targets)进行损失计算更新网络即可。
Post Process Detections
若是推理模式,则不需上述的损失计算这一过程。但需进行后处理,将回归参数转换为坐标,即通过class_logits, box_regression, proposals, images_shapes,得到最终的预测边界框坐标和类别分数。
首先,通过Box Coder Decode,将box_regression和proposals进行计算,得到预测的1000 * num_classes个(在推理模式下,RPN生成1000个Proposals,训练模式下生成2000个Proposals,每个Proposal对每个类别都预测边界框回归参数和得分)边界框的预测坐标。
然后将预测的类别分数进行softmax处理,处理成概率分数。
最后遍历batch内的每个图像:
-
裁剪预测的bounding boxes坐标,将越界包围框调整到图像边界。
-
移除索引为背景(即类别0)的所有信息。
-
移除低概率目标(预测概率小于score threshold,一般为目标个数分之一)。
-
移除小目标。
-
NMS非极大值抑制处理,滤除过于相近的目标包围框(返回结果由scores从大到小排序)。
-
选取前topk个预测目标(一般是100个)。
得到最终的boxes,scores,labels,打包至result变量中。
Post Process
因为我们输入网络的图像已经根据指定的边长进行了等比例缩放,预测后的目标包围框也是基于缩放后的尺寸。因此需要借助缩放后的尺寸image_sizes(保存在了ImageList中),以及最初统计的图像原尺寸original_image_sizes进行缩放处理,得到最终的边界框坐标、类别名称、预测分数detections。
最后将detections绘制到原图即可。
损失计算
Faster R-CNN的损失包括两个部分,训练过程中,在第一阶段RPN产生区域提议和第二阶段进行目标预测都会有损失计算,而网络推理时,是不需要进行损失计算的。
Region Proposal Network
在RPN网络中,我们得到了proposals和对应的score。要想让RPN网络生成更加准确的proposals和score,需要对其生成的anchor回归参数以及类别进行训练。
Assgin Targets to Anchors
通过assign_targets_to_anchors函数,计算每个anchor最匹配的ground truth box,将anchor划分为正负样本,用于后续的RPN网络训练。
def assign_targets_to_anchors(self, anchors, targets):
# type: (List[Tensor], List[Dict[str, Tensor]]) -> Tuple[List[Tensor], List[Tensor]]
labels = []
matched_gt_boxes = []
# 遍历每张图像的anchors和targets
for anchors_per_image, targets_per_image in zip(anchors, targets):
gt_boxes = targets_per_image["boxes"]
if gt_boxes.numel() == 0:
device = anchors_per_image.device
matched_gt_boxes_per_image = torch.zeros(anchors_per_image.shape, )
labels_per_image = torch.zeros((anchors_per_image.shape[0],), )
else:
# 计算anchors与gtbox的iou, shape=(num_gt, num_anchors)
match_quality_matrix = box_ops.box_iou(gt_boxes, anchors_per_image)
# 计算每个anchors与gt匹配iou最大的索引(iou<0.3索引置为-1,0.3<iou<0.7索引为-2)
matched_idxs = self.proposal_matcher(match_quality_matrix)
# 这里使用clamp设置下限0是为了方便取每个anchors对应的gt_boxes信息
# 负样本和舍弃的样本都是负值,所以为了防止越界直接置为0
# 计算目标边界框回归损失时只会用到正样本。
matched_gt_boxes_per_image = gt_boxes[matched_idxs.clamp(min=0)]
# 记录所有anchors匹配后的标签(正样本处标记为1,负样本处标记为0,丢弃样本处标记为-2)
labels_per_image = matched_idxs >= 0
labels_per_image = labels_per_image.to(dtype=torch.float32)
# background (negative examples)
bg_indices = matched_idxs == self.proposal_matcher.BELOW_LOW_THRESHOLD # -1
labels_per_image[bg_indices] = 0.0
# discard indices that are between thresholds
inds_to_discard = matched_idxs == self.proposal_matcher.BETWEEN_THRESHOLDS
labels_per_image[inds_to_discard] = -1.0
labels.append(labels_per_image)
matched_gt_boxes.append(matched_gt_boxes_per_image)
return labels, matched_gt_boxesproposal_matcher,将计算得到的iou矩阵在dim=0处取最大值,计算每个proposals的最佳匹配ground truth。得到matched_vals, matches (value, index)。
然后将iou<low_threshold的索引设置为-1,为负样本;将iou在low_threshold和high_threshold之间的anchors索引设置为-2,为丢弃样本。(此时若正样本数量过少,可以通过set_low_quality_matches_,将iou低于给定阈值的anchors依旧设置为正样本)
通过得到的索引,就可以得到每个图像匹配到的ground truth box。
最终返回labels(所有anchors的标签)matched_gt_boxes (每个anchor匹配到的gt box,非正样本为首个gt box)。
Box Coder Encode
Anchor Generator生成的所有anchor与上一步得到的anchors对应的ground truth boxes,计算边界框的回归参数。计算公式即为RPN部分Box Coder Decode中所给的公式。
Sampler
在计算RPN部分的损失时,首先要区分正负样本。
通过fg_bg_sampler函数将labels分为正负样本,即得到sampled_pos_inds, sampled_neg_inds。
在fg_bg_sampler内,统计正样本和负样本。(借助labels的索引,大于0为正,等于0为负)
在训练策略中,每个图像默认使用256个样本进行训练,正负1比1。若正样本不够,就将所有的正样本都加入训练,剩下的负样本补齐,反之同理。
使用torch.randperm生成随机序列,用于打乱正负样本的索引。
最后使用anchors长度的mask,将正负样本对应的索引处标为1,非样本处标为0,得到sampled_pos_inds, sampled_neg_inds。
得到正负样本的index后,将所有正负样本索引拼接在一起,得到sampled_pos_inds,用于回归损失。然后将objectness展平,用于分类损失。
Loss Compute
L(\{p_i\},\{t_i\}) = \frac{1}{N_{cls}}\sum_{i}L_{cls}(p_i,p_i^*) \\ \qquad\qquad\qquad\quad +\lambda \frac{1}{N_{reg}}\sum_{i}p_i^*L_{reg}(t_i,t_i^*)
$$
损失包括两个内容,一个是目标分类损失,一个是预测边界框的回归损失。
分类损失使用的是二值交叉熵损失。
L_{cls}=-p_i^*log(p_i) + (1-p_i^*)log(1-p_i^*)
$$
其中,$ p_i $表示第i个anchor预测有目标的概率;$ p_i^* $表示真值,正样本为1,负样本为0。
回归损失使用的是Smooth L1 损失。
L_{reg}(t_i, t_i^*)=\sum_{i}smooth_{L_1}(t_i - t_i^*)
$$
其中,$ t_i $表示第i个anchor的预测回归参数;$ t_i^* $表示第i个样本的真值,由GT box 和该anchor计算得出。
smooth_{L_1}= \begin{cases} 0.5x^2 \qquad \lvert x \rvert \leq 1 \\[2ex] \lvert x \rvert-0.5 \quad otherwise \end{cases}
$$
Fast R-CNN Detector
Select Training Samples
在RPN网络中,生成了2000个proposals。为了训练和计算损失,依旧需要划分正负样本。
首先将ground turth boxes拼接到proposals后,充当一部分正样本(满足正样本条件的proposals可能很少)。
然后调用assign_targets_to_proposal函数,为每个proposals匹配对应的gt box,得到matched_idxs, labels(与RPN部分的方法基本相同)。
def assign_targets_to_proposals(self, proposals, gt_boxes, gt_labels):
# type: (List[Tensor], List[Tensor], List[Tensor]) -> Tuple[List[Tensor], List[Tensor]]
matched_idxs = []
labels = []
# 遍历每张图像的proposals, gt_boxes, gt_labels信息
for proposals_in_image, gt_boxes_in_image, gt_labels_in_image in zip(proposals, gt_boxes, gt_labels):
if gt_boxes_in_image.numel() == 0: # 该张图像中没有gt框,为背景
# background image
device = proposals_in_image.device
clamped_matched_idxs_in_image = torch.zeros((proposals_in_image.shape[0],), )
labels_in_image = torch.zeros((proposals_in_image.shape[0],),)
else:
# 计算proposal与每个gt_box的iou, shape=(num_gt, num_proposals)
match_quality_matrix = box_ops.box_iou(gt_boxes_in_image, proposals_in_image)
# 计算proposal与每个gt_box匹配的iou最大值,并记录索引,
# iou<low_threshold索引值为 -1,low_threshold<=iou<high_threshold索引值为 -2
matched_idxs_in_image = self.proposal_matcher(match_quality_matrix)
# 限制最小值,防止匹配标签时出现越界的情况
# 注意-1, -2对应的gt索引会调整到0,获取的标签类别为第0个gt的类别(实际上并不是),后续处理
clamped_matched_idxs_in_image = matched_idxs_in_image.clamp(min=0)
# 获取proposal匹配到的gt对应标签
labels_in_image = gt_labels_in_image[clamped_matched_idxs_in_image]
labels_in_image = labels_in_image.to(dtype=torch.int64)
# label background (below the low threshold)
# 将gt索引为-1的类别设置为0,即背景,负样本
bg_inds = matched_idxs_in_image == self.proposal_matcher.BELOW_LOW_THRESHOLD
labels_in_image[bg_inds] = 0
# label ignore proposals (between low and high threshold)
# 将gt索引为-2的类别设置为-1, 即废弃样本
ignore_inds = matched_idxs_in_image==self.proposal_matcher.BETWEEN_THRESHOLDS
labels_in_image[ignore_inds] = -1 # -1 is ignored by sampler
matched_idxs.append(clamped_matched_idxs_in_image)
labels.append(labels_in_image)
return matched_idxs, labels然后通过subsmaple划分正负样本。subsmaple内的核心函数即为RPN使用过的fg_bg_sampler,得到sampled_pos_inds, sampled_neg_inds。然后记录所有样本的索引,总合成sampled_inds(每个图像共512个样本,正负比1:3,某一类不足用另一类补全)。
然后遍历batch内的每张图像,获取该图像的正负样本索引,以及proposals、labels、对应的ground truth box 索引、以及对应正负样本的ground truth box 坐标。
使用Box Coder Encode,根据ground truth boxes坐标和生成的proposals坐标计算ground truth boxes的回归参数。
最终得到proposals,labels,regression_targets,都是长度为batch的列表。列表的每一个元素都是对应图像的相关tensor信息(例如proposals[0]: Tensor (512, 4) )。
Loss Compute
在预测阶段,Faster R-CNN使用的其实还是Fast R-CNN的检测头,需要预测proposals的类别和边界框回归参数,因此也是一个多任务损失,沿用了前代Fast R-CNN的损失函数。
L(p,u,t^u,v)=L_{cls}(p,u)+\lambda[u \ge 1]L_{loc}(t^u, v) \tag{1}
$$
其中,$ p $ 是Predictor预测的softmax概率分布,$ u $ 是目标真实类别标签。
$ t^u $是Predictor预测的对应类别为u(预测器为每个类别都预测一组回归参数)的边界框回归参数,v是对应真实目标的边界框回归参数。
分类损失,多类别交叉熵损失。
L_{cls}(p,u)=-\log{p_u}\tag{2}
$$
标准的交叉熵损失函数为$ L=-\sum_{i}u_i log({p_i}) $。
当类别i不为u时,显然$ u_ilog{p_i} $为0。仅保留非零项,即预测到类别u时,可以得到损失函数(2)。
回归损失,Smooth L1损失。
L_{loc}(t^u,v)=\sum_{i\in\{x,y,w,h\}}smooth_{L_1}(t_i^u-v_i) \tag{3}
$$
其中回归损失的系数是艾弗森括号,如果方括号内的条件满足则为1,不满足则为0,即正样本才计算定位损失。
那么因此,class_logits与labels,box_regression与regression_targes分别进行损失计算即可。
总结
至此,Faster R-CNN的整个网络流程就结束了,相关细节也基本都涉及到。
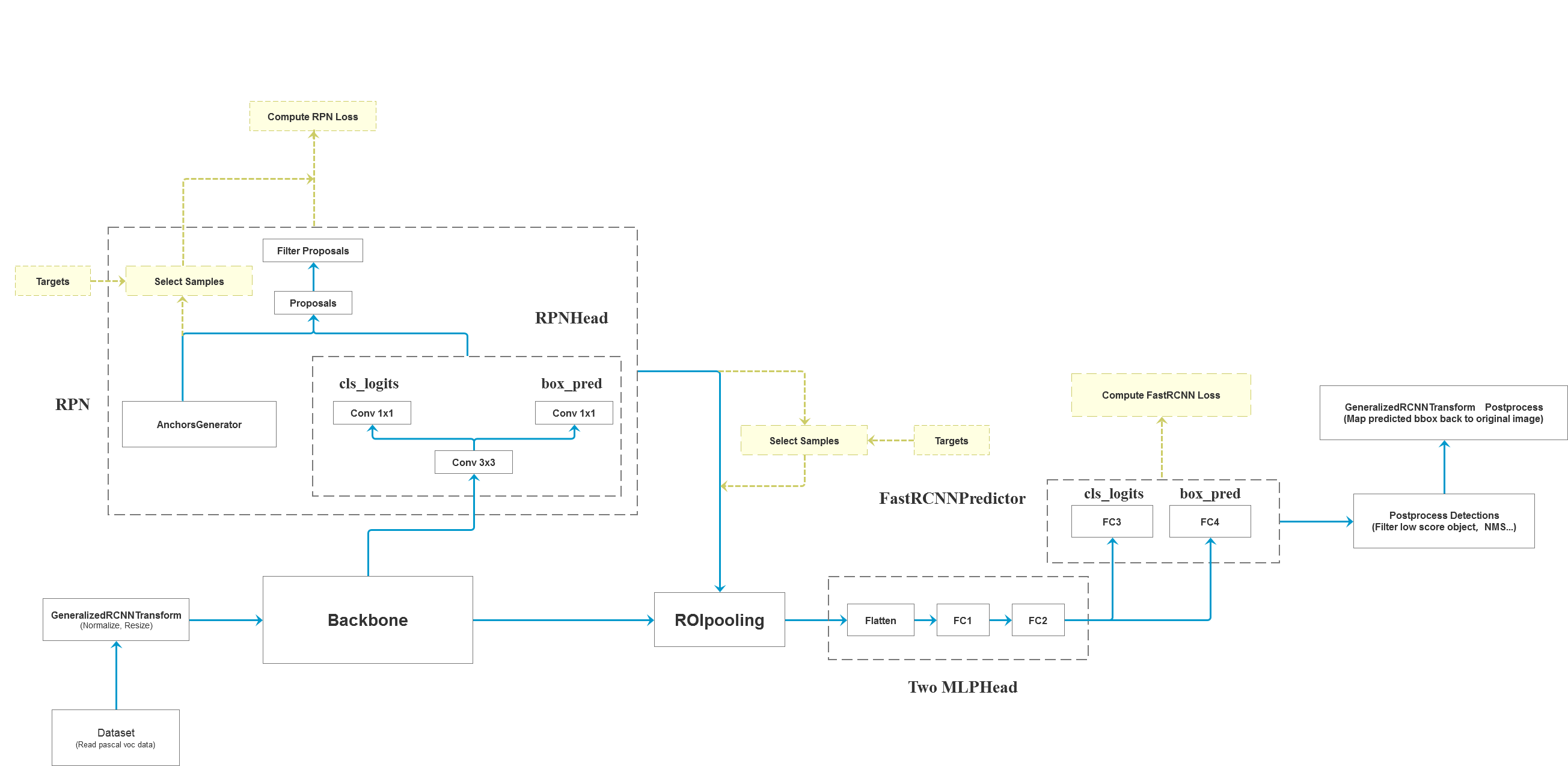
最后补充一张Faster R-CNN的流程图,来自于。
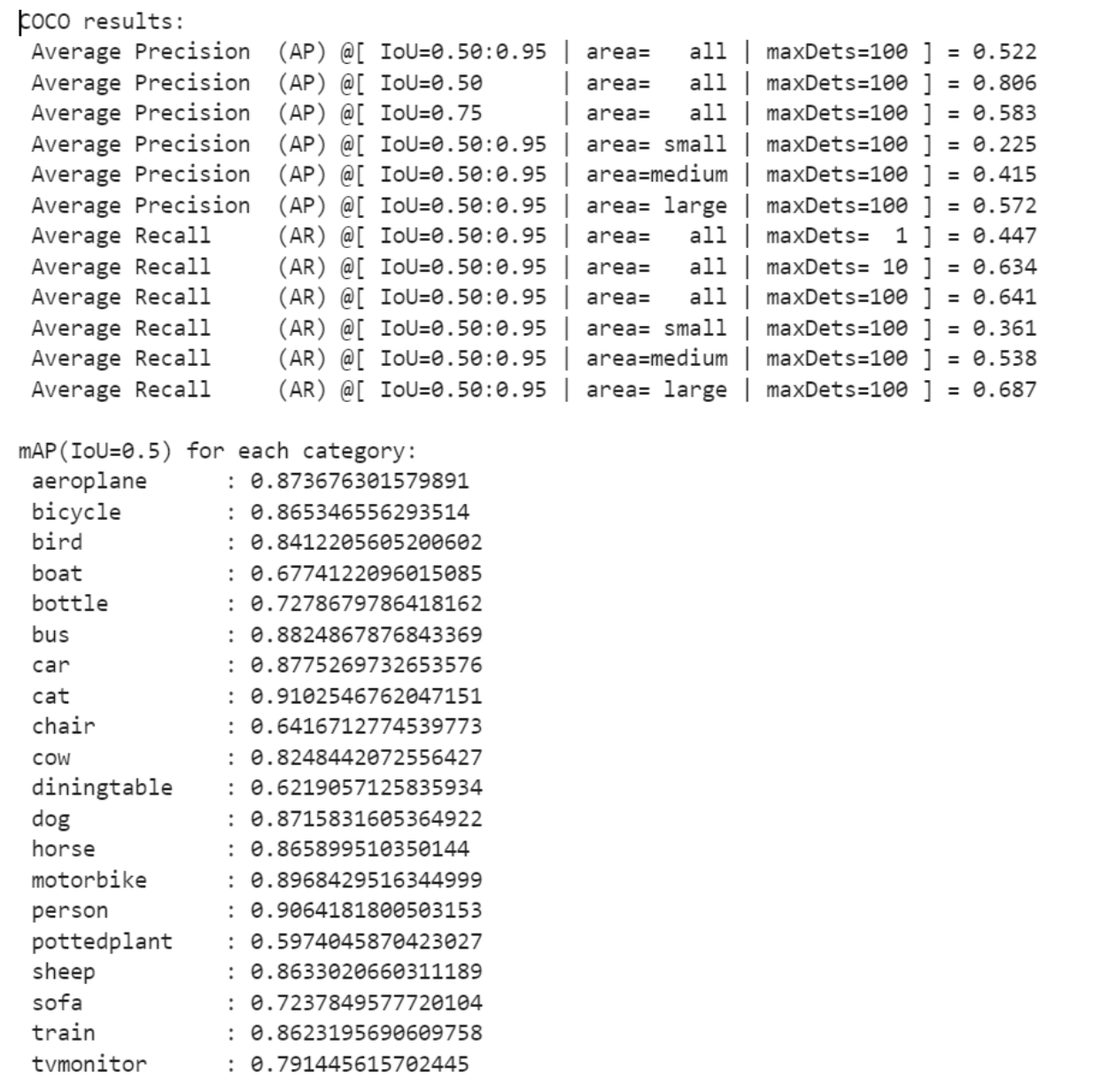
Faster R-CNN是目标检测的经典力作,技术相对成熟,而且至今仍有较为不错的精度,应用广泛。个人在VOC2012训练集上进行训练,在验证集上进行验证,可以达到80.65%的mAP(Iou=0.5)。
以下是对于一幅图像的检测,可以看到非常精准。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}