SegFormer: 轻量级语义分割Transformer学习与实现
SegFormer是一种简单高效的Transformer语义分割网络,发表在NeurlPS'21(SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers)上()。
在Vision Transformer在计算机视觉领域大获成功后,越来越多的视觉工作也转移到了Transformer架构上来。SegFormer就是一种简单高效的,将Transformer和轻量级的MLP相结合的语义分割框架,在ADE20k、Cityscapes等数据集上取得了相当优越的结果。
标准的Vision Transformer存在以下一些局限:
-
ViT对截取固定大小的Patch,将图像转化成token。这种操作使得整个过程中,特征的分辨率大小是固定的,对于语义分割等密集预测任务来说不够友好。
-
ViT能够处理的图像分辨率相对固定。当输入更高分辨率图像时,在每个Patch大小不变时,图像序列的尺寸会变大。此时需要对原来的位置编码进行插值,会造成精度上的损失。
-
ViT的计算量相当大,对图片做自注意力运算,计算开销是像素平方级增长,很不友好。
![]() 图1 标准vit架构
图1 标准vit架构
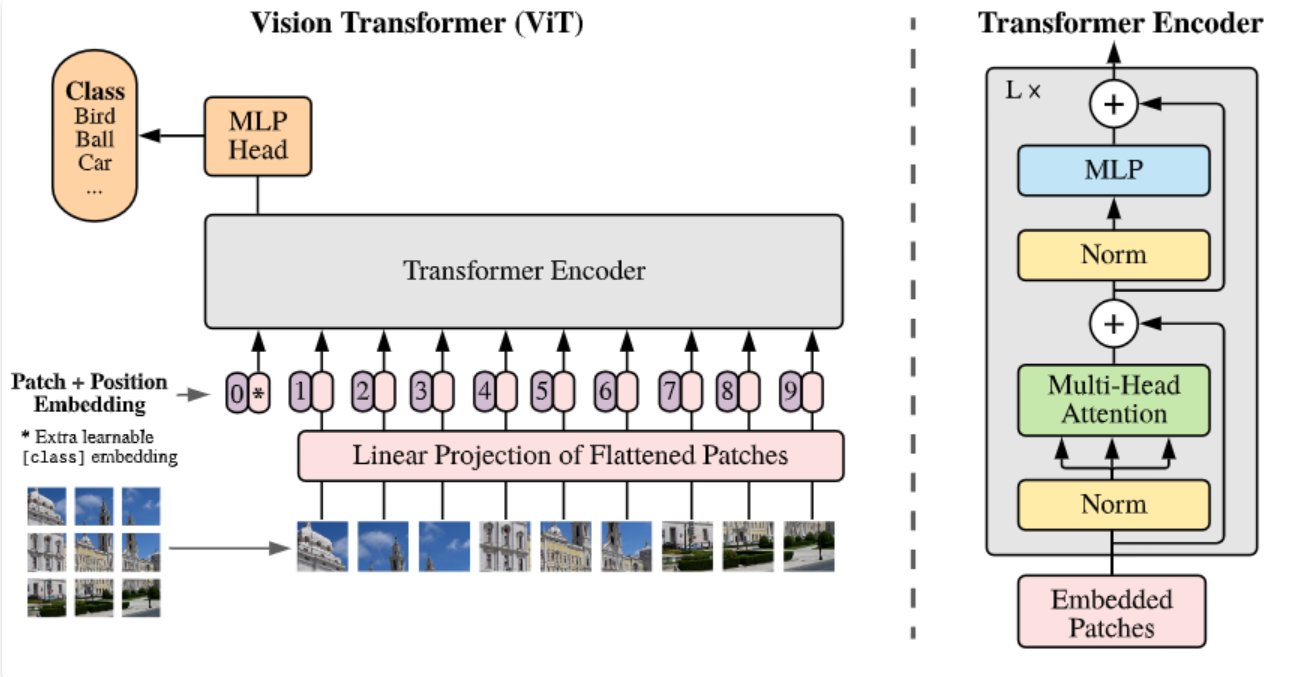
在语义分割等任务中,多尺度特征往往对精度是有帮助的。大多数网络的设计也遵循了这一原则。像PVT(pyramid vision Transformer)和Swin Transformer也都是使用分层特征的Transformer架构。但是它们重视于Transformer Encoder的设计,忽视了Decoder的作用。
因此,针对以上问题,SegFormer出现。总体而言,SegFormer有以下优点:
-
分层分辨率的Transformer Encoder结构,同时不需要位置编码。
-
使用轻量级的全MLP Decoder结构,无需复杂、计算量大的模块即可产生强大的特征表示。
方法
SegFormer的结构如图2,包含4个Transformer Block。
在经过每个Block时,先经过Overlap Patch Merging操作,融合patch从而产生不同大小的分辨率特征。之后就是Transformer经典的多头注意力以及前馈神经网络FFN(源码中的做法是这样的,与图中所给的步骤有些不一样)。
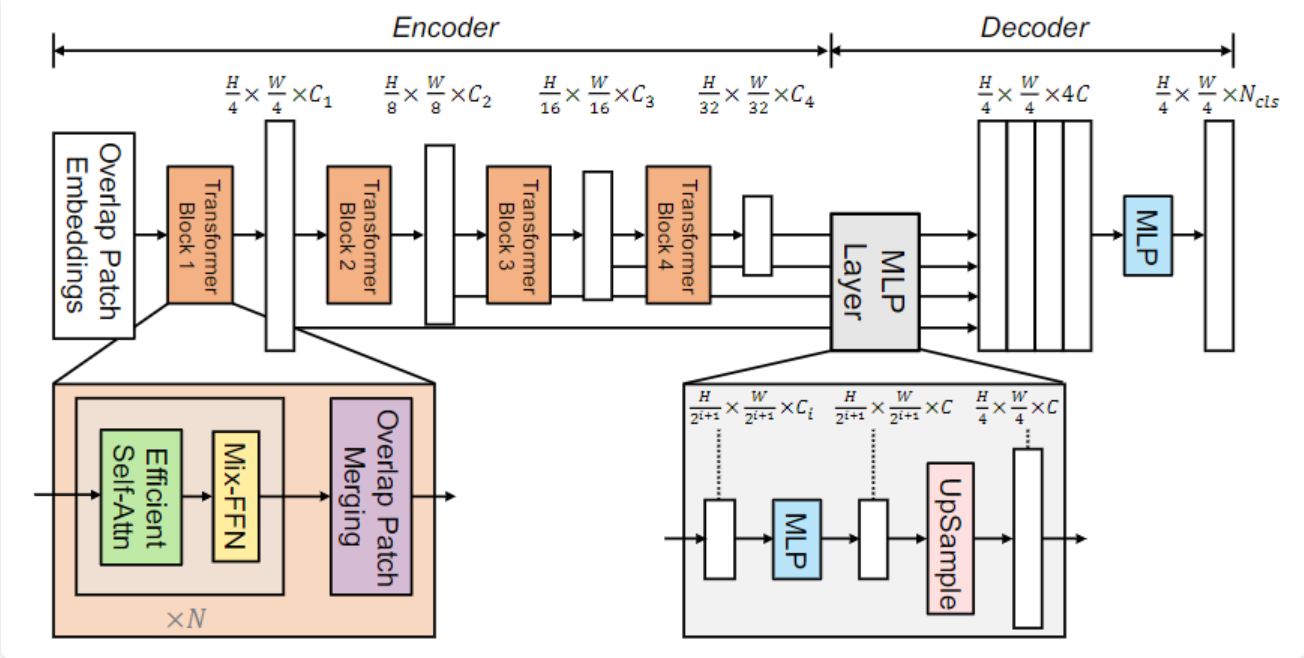
接下来将具体介绍SegFormer内相关的方法。
Encoder
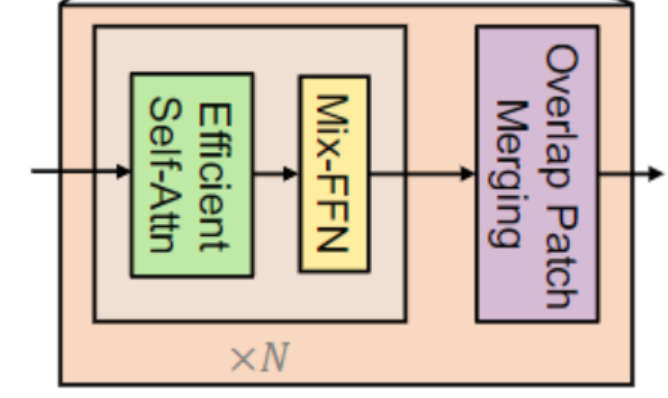
Overlap Patch Merge
在ViT中使用patch merge,可以轻易地将特征张量缩小。但是此过程最初旨在组合非重叠的图像或特征块,不能保持patch周围的局部连续性。因此SegFormer使用Overlap Patch Merge,进行特征融合从而取得分层的特征。
在具体实现中,是使用卷积操作进行的Patch Merge,即通过设计卷积核大小和步幅,来降低特征分辨率。同时卷积应该也实现了Embedding操作,将其投射到给定维度。
class OverlapPatchEmbed(nn.Module):
def __init__(self, patch_size=7, stride=4, in_channels=3, embed_dim=768):
super().__init__()
patch_size = (patch_size, patch_size)
self.proj = nn.Conv2d(in_channels, embed_dim,
kernel_size=patch_size, stride=stride,
padding=(patch_size[0]//2, patch_size[1]//2))
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x): # x (b, c, h, w)
x = self.proj(x) # x (b, embed, h/4, w/4) default
_, _, H, W = x.shape
x = x.flatten(2).transpose(1, 2) # x (b, h*w/16, embed)
x = self.norm(x) # x (b, h*w/16, embed) (b, n, c)
return x, H, WEfficient Self-Attention
对于相同尺寸的QKV(NxC),其中N=HxW,标准的Attention运算是
Attention(Q,K,T) = Softmax(\frac{Q K^T} {\sqrt{d_{head}}})V
$$
计算复杂度是N的平方级别。为了提高运算效率,引入一个缩放因子R。
\hat{K} = Reshape( \frac{N}{R}, C·R)(K)\\ K = Linear(C·R, C)( \hat{K}),
$$
即将K的特征维度缩小R倍,以降低注意力运算的复杂度。
具体实现中涉及了大量的张量尺寸的转换,还是比较复杂的。在代码中,是使用卷积实现的维度缩小。
class EfficientSelfAttention(nn.Module): # 感觉基本借鉴了PVT的注意力实现
def __init__(self, dim, num_heads, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__()
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5 # sqrt
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.sr_ratio = sr_ratio
if sr_ratio > 1:
self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio) # reduction
self.norm = nn.LayerNorm(dim)
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x, H, W): # x (b, n, c)
B, N, C = x.shape
# q (b, n, c) -> (b, n, heads, c/heads) -> (b, heads, n, c/heads) 产生多个头
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
if self.sr_ratio > 1: # reduction 维度收缩
# x_ (b, c, n) -> (b, c, h, w)
x_ = x.permute(0, 2, 1).reshape(B, C, H, W)
# x_ (b, c, h/r, w/r) -> (b, c, h*w/R) -> (b, h*w/R, c)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1) #
x_ = self.norm(x_)
# kv (b, n/R, c*2) -> (b, n/R, 2, heads, c/heads) -> (2, b, heads, n/R, c/heads)
kv = self.kv(x_).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
else:
# kv (b, h*w, c*2) -> (b, n, 2, heads, c/heads) -> (2, b, heads, n, c/heads)
kv = self.kv(x).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
#k, v (b, heads, n/R, c/heads)
k, v = kv[0], kv[1]
# attn (b, heads, n, c/heads) * (b, heads, c/heads, n/R) -> (b, heads, n, n/R)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
# x (b, heads, n, n/R) * (b, heads, n/R, c/heads) -> (b, heads, n, c/heads)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
# x (b, n, heads, c/heads) -> (b, n, c)
x = self.proj(x)
x = self.proj_drop(x)
# x (b, n, c)
return x
Mix-FFN
SegFomer认为位置编码不是语义分割任务所必须的。因此放弃了位置编码,在前馈神经网络中融合了0填充的3x3卷积,通过这种方式汇入位置信息。
x_{out} = MLP(GELU(Conv3×3(MLP(x_{in})))) + x_{in},
$$
class DWConv(nn.Module): # 使用卷积获取位置信息,融合在mix-ffn里
def __init__(self, dim=768):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, 3, 1, 1, bias=True, groups=dim)
def forward(self, x, H, W): # x (b, n, c)
B, N, C = x.shape
x = x.transpose(1, 2).view(B, C, H, W) # x (b, c, h, w)
x = self.dwconv(x) # x(b, dim, h, w)
x = x.flatten(2).transpose(1, 2) # x (b, n, dim)
return x
class FFN(nn.Module):
def __init__(self, in_features, hidden_feaures=None, out_features=None, act_layer=nn.GELU(), drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_feaures = hidden_feaures or in_features
self.fc1 = nn.Linear(in_features, hidden_feaures)
self.dwconv = DWConv(hidden_feaures)
self.act = act_layer
self.fc2 = nn.Linear(hidden_feaures, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x, H, W): # x (b, n, in_c)
x = self.fc1(x)
x = self.dwconv(x, H, W)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x # x (b, n, out_c)
那么整个Encoder Block就通过以上三个主要结构堆叠。
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio, qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU(), norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim) # (b, n, c) -> (b, n, c)
self.attn = EfficientSelfAttention(dim=dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio)
self.norm2 = norm_layer(dim)
self.mlp = FFN(in_features=dim, hidden_feaures=(dim * mlp_ratio), act_layer=act_layer, drop=drop)
# DropPath和Dropout思想类似,将多分支结构的子路径"随机删除"
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x, H, W): # x (b, n, c)
x = x + self.drop_path(self.attn(self.norm1(x), H, W)) # x (b, n, c)
x = x + self.drop_path(self.mlp(self.norm2(x), H, W))
return x #(b, n, c)Full Structure
整体的MixVisionTransformer,堆叠四个Encoder Block块。通过调整每个Block块的参数,即可实现不同参数大小的mit Encoder网络。
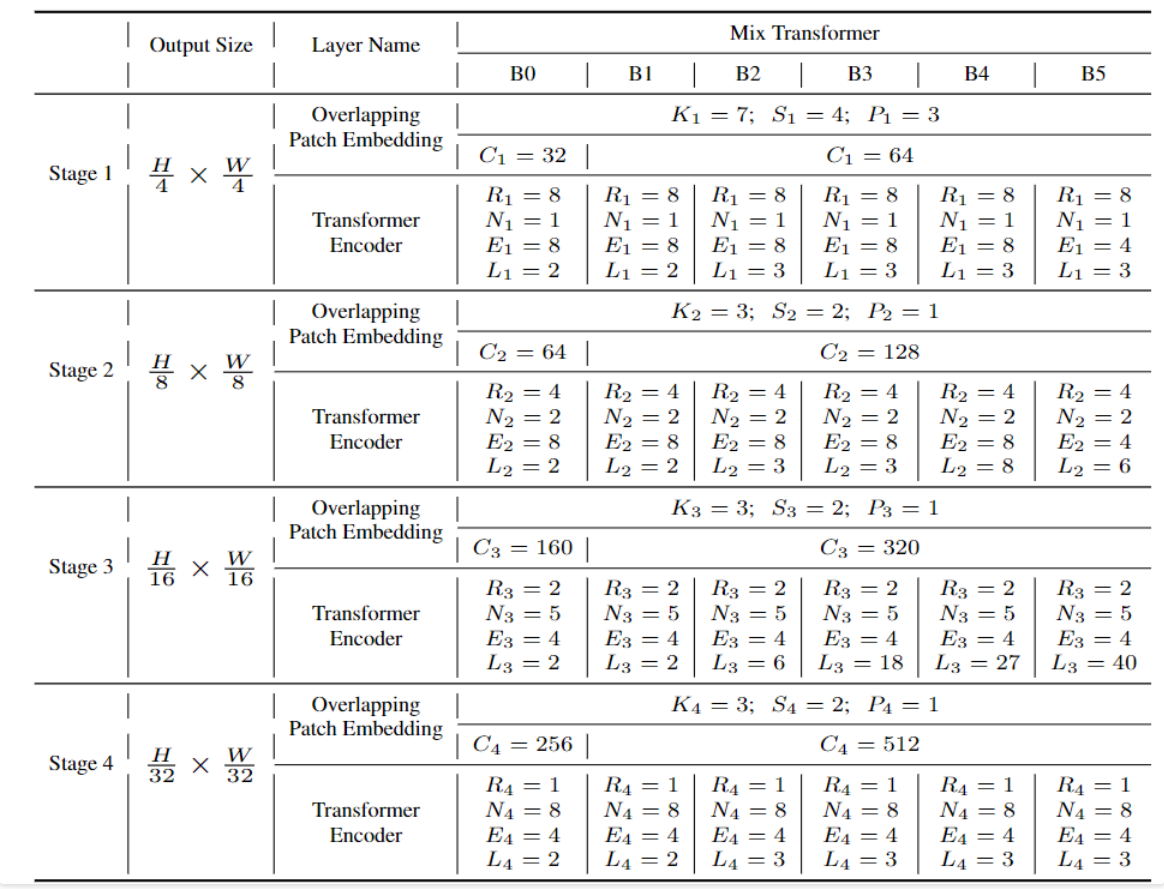
在每个Block(stage)中,先进行一个Overlap Patch Embed,将patch的特征融合嵌入,生成更小尺度的特征。然后再利用transformer模块进行特征提取。
class MixVisionTransformer(nn.Module):
def __init__(self, in_channels=3, num_classes=1000, embed_dims=[32, 64, 160, 256],
num_heads=[1, 2, 4, 8], mlp_ratios=[4, 4, 4, 4], qkv_bias=False, qk_scale=None, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1]):
super().__init__()
self.num_classes = num_classes
self.depths = depths
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
# block1
self.patch_embed1 = OverlapPatchEmbed(patch_size=7, stride=4, in_channels=in_channels, embed_dim=embed_dims[0])
cur = 0
self.block1 = nn.ModuleList(
[
Block(dim=embed_dims[0], num_heads=num_heads[0], mlp_ratio=mlp_ratios[0], qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i],
norm_layer=norm_layer, sr_ratio=sr_ratios[0])
for i in range(depths[0])
]
)
self.norm1 = norm_layer(embed_dims[0])
# block2
self.patch_embed2 = OverlapPatchEmbed(patch_size=3, stride=2, in_channels=embed_dims[0], embed_dim=embed_dims[1])
cur += depths[0]
self.block2 = nn.ModuleList(
[
Block(dim=embed_dims[1], num_heads=num_heads[1], mlp_ratio=mlp_ratios[1], qkv_bias=qkv_bias,
qk_scale=qk_scale,drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i],
norm_layer=norm_layer, sr_ratio=sr_ratios[1])
for i in range(depths[1])
]
)
self.norm2 = norm_layer(embed_dims[1])
# block3
self.patch_embed3 = OverlapPatchEmbed(patch_size=3, stride=2, in_channels=embed_dims[1], embed_dim=embed_dims[2])
cur += depths[1]
self.block3 = nn.ModuleList(
[
Block(dim=embed_dims[2], num_heads=num_heads[2], mlp_ratio=mlp_ratios[2], qkv_bias=qkv_bias,
qk_scale=qk_scale,drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i],
norm_layer=norm_layer, sr_ratio=sr_ratios[2])
for i in range(depths[2])
]
)
self.norm3 = norm_layer(embed_dims[2])
# block4
self.patch_embed4 = OverlapPatchEmbed(patch_size=3, stride=2, in_channels=embed_dims[2], embed_dim=embed_dims[3])
cur += depths[2]
self.block4 = nn.ModuleList(
[
Block(dim=embed_dims[3], num_heads=num_heads[3], mlp_ratio=mlp_ratios[3], qkv_bias=qkv_bias,
qk_scale=qk_scale,drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i],
norm_layer=norm_layer, sr_ratio=sr_ratios[3])
for i in range(depths[3])
]
)
self.norm4 = norm_layer(embed_dims[3])
def forward(self, x):
B = x.shape[0]
outs = []
# block1
# x (b, 3, 512, 512) -> (b, embed[0], 128, 128) -> (b, 16384, embed[0])
x, H, W = self.patch_embed1(x)
# x (b, 16384, embed[0]) -> (b, 16384, embed[0])
for i, blk in enumerate(self.block1):
x = blk(x, H, W)
x = self.norm1(x)
# x (b, 16384, embed[0]) -> (b, embed[0], 128, 128)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() # 深拷贝
outs.append(x)
# block2
# x (b, embed[0], 128, 128) -> (b, embed[1], 64, 64) -> (b, 4096, embed[1])
x, H, W = self.patch_embed2.forward(x)
# x (b, 4096, embed[1]) -> (b, 4096, embed[1])
for i, blk in enumerate(self.block2):
x = blk.forward(x, H, W)
x = self.norm2(x)
# x (b, 4096, embed[1]) -> (b, embed[1], 64, 64)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
outs.append(x)
# block3
# x (b, embed[1], 64, 64) -> (b, embed[2], 32, 32) -> (b, 1024, embed[2])
x, H, W = self.patch_embed3.forward(x)
# x (b, 1024, embed[2]) -> (b, 1024, embed[2])
for i, blk in enumerate(self.block3):
x = blk.forward(x, H, W)
x = self.norm3(x)
# x (b, 1024, embed[2]) -> (b, embed[2], 32, 32)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
outs.append(x)
# block4
# x (b, embed[2], 32, 32) -> (b, embed[3], 16, 16) -> (b, 256, embed[3])
x, H, W = self.patch_embed4.forward(x)
# x (b, 256, embed[3]) -> (b, 256, embed[3])
for i, blk in enumerate(self.block4):
x = blk.forward(x, H, W)
x = self.norm4(x)
# x (b, 256, embed[3]) -> (b, embed[3], 16, 16)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
outs.append(x)
return outs
# 以mit_b0为例
class mit_b0(MixVisionTransformer):
def __init__(self):
super(mit_b0, self).__init__(
embed_dims=[32, 64, 160, 256], num_heads=[1, 2, 5, 8], mlp_ratios=[4, 4, 4, 4],
qkv_bias=True, norm_layer=nn.LayerNorm, depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1],
drop_rate=0.0, drop_path_rate=0.1)
Decoder
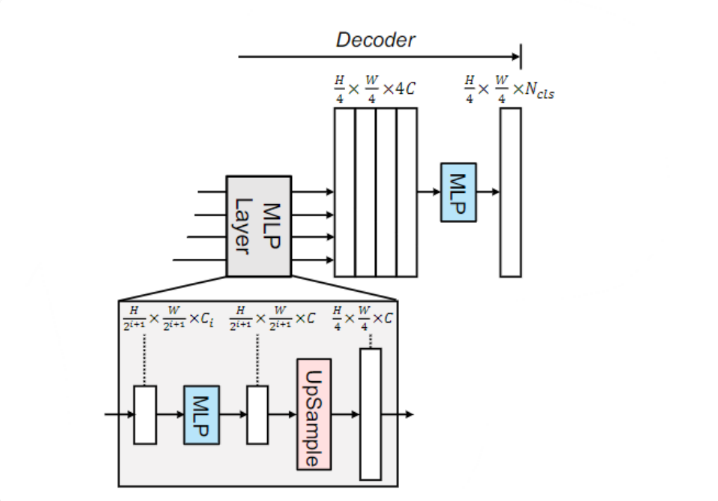
SegFormer的Decoder是简单的MLP结构。在Encoder中,4个Transformer Block 生成4组分辨率不同的特征。
\hat{Fi} = Linear(Ci, C)(Fi), ∀i\\ \hat{Fi} = Upsample( \frac{W}{4} ×\frac{W}{4} )(\hat{Fi}), ∀i\\ F = Linear(4C, C)(Concat(\hat{Fi})), ∀i \\ M = Linear(C, Ncls)(F ),
$$
每组特征先进入MLPLayer,通过一个线性层将其投射到固定的维度。然后使用双线性插值上采样,至第一个Block的特征分辨率。
最后将MLP layer输出的4组特征在通道维度concatenate起来,经过一个线性层进行语义分割预测。
MLP
SegFormer的Decoder是All-MLP结构,不同的位置作用不同。
在图中MLP Layer内,MLP用于将Encoder的特征投射到固定的维度。
class MLP(nn.Module):
def __init__(self, input_dim=2048, embed_dim=768):
super().__init__()
self.proj = nn.Linear(input_dim, embed_dim)
def forward(self, x): # x (b, c, h, w)
x = x.flatten(2).transpose(1, 2) # x (b, n, c)
x = self.proj(x) # x (b, n, embed)
return x下面的mlp操作是通过卷积实现的,将经过线性变换的特征融合。在很多情况下,mlp操作都可以看成是一种1x1的卷积。
class ConvModule(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=0, g=1, act=True):
super(ConvModule, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, p, groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2, eps=0.001, momentum=0.03)
self.act = nn.ReLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))Decoder
此外,在Decoder的最后一层,也是使用MLP进行语义分割预测,即将特征维度数量投射到类别。
class Decoder(nn.Module):
def __init__(self, num_classes=20, in_channels=[32, 64, 160, 256], embedding_dim=768, dropout_ratio=0.1):
super(SegFormerHead, self).__init__()
c1_in_channels, c2_in_channels, c3_in_channels, c4_in_channels = in_channels
self.linear_c4 = MLP(input_dim=c4_in_channels, embed_dim=embedding_dim)
self.linear_c3 = MLP(input_dim=c3_in_channels, embed_dim=embedding_dim)
self.linear_c2 = MLP(input_dim=c2_in_channels, embed_dim=embedding_dim)
self.linear_c1 = MLP(input_dim=c1_in_channels, embed_dim=embedding_dim)
self.linear_fuse = ConvModule(
c1=embedding_dim * 4, c2=embedding_dim, k=1,
)
self.linear_pred = nn.Conv2d(embedding_dim, num_classes, kernel_size=1) # 也是通过1x1卷积实现的mlp
self.dropout = nn.Dropout2d(dropout_ratio)
def forward(self, inputs):
c1, c2, c3, c4 = inputs
n, _, h, w = c4.shape
# (b, c, 32, 32) -> (b, 1024, embed) -> (b, embed, 1024) -> (b, embed, 32, 32)
_c4 = self.linear_c4(c4).permute(0,2,1).reshape(n, -1, c4.shape[2], c4.shape[3])
# (b, embed, 32, 32) -> (b, embed, 128, 128)
_c4 = F.interpolate(_c4, size=c1.size()[2:], mode='bilinear', align_corners=False)
_c3 = self.linear_c3(c3).permute(0,2,1).reshape(n, -1, c3.shape[2], c3.shape[3])
_c3 = F.interpolate(_c3, size=c1.size()[2:], mode='bilinear', align_corners=False)
_c2 = self.linear_c2(c2).permute(0,2,1).reshape(n, -1, c2.shape[2], c2.shape[3])
_c2 = F.interpolate(_c2, size=c1.size()[2:], mode='bilinear', align_corners=False)
_c1 = self.linear_c1(c1).permute(0,2,1).reshape(n, -1, c1.shape[2], c1.shape[3])
_c = self.linear_fuse(torch.cat([_c4, _c3, _c2, _c1], dim=1))
x = self.dropout(_c)
x = self.linear_pred(x)
return xSegFormer
将MixVisionTransformer和SegformerDecoder组合起来,将最后的结果插值到输入的原图像大小。
class SegFormer(nn.Module):
def __init__(self, num_classes = 21, phi = 'b0', pretrained = False):
super(SegFormer, self).__init__()
self.in_channels = {
'b0': [32, 64, 160, 256], 'b1': [64, 128, 320, 512], 'b2': [64, 128, 320, 512],
'b3': [64, 128, 320, 512], 'b4': [64, 128, 320, 512], 'b5': [64, 128, 320, 512],
}[phi]
self.mit = {
'b0': mit_b0, 'b1': mit_b1, 'b2': mit_b2,
'b3': mit_b3, 'b4': mit_b4, 'b5': mit_b5,
}[phi](pretrained)
self.embedding_dim = {
'b0': 256, 'b1': 256, 'b2': 768,
'b3': 768, 'b4': 768, 'b5': 768,
}[phi]
self.decoder = Decoder(num_classes, self.in_channels, self.embedding_dim)
def forward(self, inputs):
H, W = inputs.size(2), inputs.size(3)
x = self.mit(inputs)
x = self.decoder(x)
x = F.interpolate(x, size=(H, W), mode='bilinear', align_corners=True) # 上采样至原图大小
return x
总结
总体而言,SegFormer是一个用于语义分割的轻量级Transformer架构。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号