

图像处理那些事儿——图像读取、保存、处理
在计算机视觉中,总少不了与图像打交道。最近在处理血管瘤分割时,需要用到不少内容,包括图像增强、图像可视化、在图像上显示掩模等。正好在这里记录一下平时常用的处理方法,包括但不限于图像读取、图像转换、图像处理、图像保存。
import os import cv2 import torch import numpy as np from torchvision import transforms from PIL import Image import matplotlib.pyplot as plt
图像打开
PIL读取
path = './data/Angeioma/img/11.png' pil = Image.open(path) plt.imshow(pil) print('size: ', pil.size) array = np.asarray(pil) print('shape: ', array.shape)
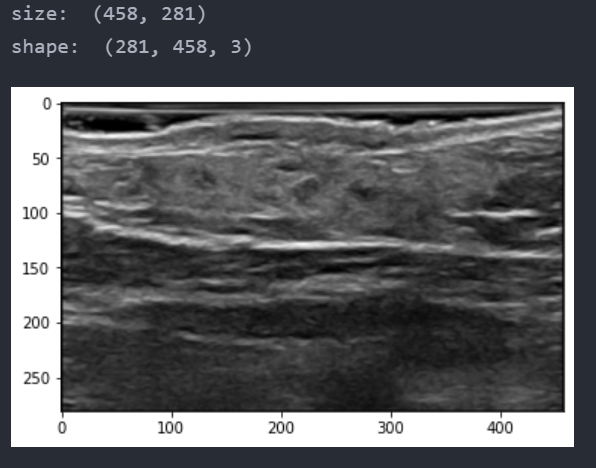
此时的img是一个PIL对象,可以直接由matplotlib展示出来。img常用的属性有size,返回一个图片(宽,高)的元组。
若要进行进一步的操作,可以将PIL对象转换成numpy数组,即
pil = np.asarray(pil)
opencv读取

path = './data/Angeioma/img/11.png' cv = cv2.imread(path) cv = cv2.cvtColor(cv ,cv2.COLOR_BGR2RGB) print('type: ', type(cv)) print('shape: ', cv.shape) plt.imshow(cv)
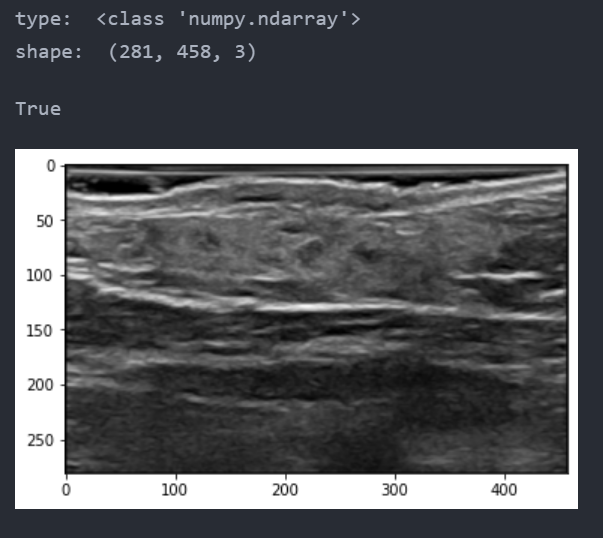
此时的img是一个numpy数组,也可以直接由matplotlib展示。常用的属性有shape,返回这个图片numpy数组的(高、宽、通道)元组。
但是由cv2.imread读取的图片,图像通道是BGR格式,一般情况下需要我们转变成RGB格式,即通过
img = cv2.CvtColor(img, cv2.COLOR_BGR2RGB)。
注意
-
opencv读取图片时,默认情况会读取3通道,若是灰度图,则会将其复制三次,需要指定。
-
通过这两种方式最后得到的numpy图像数组,像素取值是0-255之间的整数(np.uint8)
-
numpy数组的格式是(height, width, channel
图像保存
PIL保存
对于Image对象而言,图像保存可以通过调用Image.save(),即
save = './data/Angeioma/img/pic_save.jpg' image.save(save)
opencv保存
对于numpy数组,可以通过opencv的imwrite保存
save = './data/Angeioma/img/pic_save.jpg' cv2.imwrite(save, img)
注意
对于opencv而言,图像存储时,也应将图像转换成BGR通道。像素灰度值应该是uint8类型,即[0—255]的整型数
图像处理
Resize
更改图像尺寸,是计算机视觉任务中常见的操作。
在PIL、opencv、torchvision中,均有Resize操作。
在PIL中
pil = Image.open(path)
pil = pil.resize((100, 200))

在opencv中
cv = cv2.imread(path) cv = cv2.CvtColor(cv, cv2.COLOR_BGR2RGB) cv = cv2.resize(cv, (100, 200))
在torchvision中,用于resize的是transforms.Resize()。可以处理PILimage,tensor
pil = Image.open(path)
pil = transforms.Resize((100, 200))(pil)
注意,在PIL和opencv中,resize 的参数是先宽后高。在transofroms.Resize中,是先高后宽。
不同的数据类型
在深度学习中,图像一般由tensor(张量)表示。将PILImage或numpy数组与Tensor进行相互转换的工具一般是
transforms.ToTensor()和transforms.ToPILImage
pil = Image.open(path) cv = cv2.imread(path) pil_tensor = transforms.ToTensor()(pil) print(pil_tensor.shape) pil_re = transforms.ToPILImage()(pil_tensor) plt.imshow(pil_re)
由PIL图像转成的tensor,取值在0-1之间。tensor的形状是由(height,width,channel)变成了(channel,height,width)
图像tensor可以由transforms.ToPILImage直接变换成PILiamge。
同理,numpy数组也可以有类似的操作。
cv = cv2.imread(path) cv = cv2.cvtColor(cv, cv2.COLOR_BGR2RGB) cv_tensor = transforms.ToTensor()(cv) cv_re = transforms.ToPILImage()(cv_tensor) plt.imshow(cv_re)
注意
-
在transforms.ToTensor中,将元素缩放至0-1之间并不是都会发生。只有在处理的对象是PILimage或者dtype=np.uint8时,才会进行缩放。
-
在transfroms.ToPILImage中。可以将tensor转换成PILImage,也可以将numpy数组转换成PILImage。形状都是从(C,H,W)到(H,W,C)
可视化掩模
最近在做语义分割的项目,我们会将预测的mask与图片一起显示。
这里有两种处理方式。
通过图像与mask融合
即 混合图像为 mix = image * (1 - alpha) + mask * alpha
需要使image和mask保证形状一致
img_path = './data/Angeioma/img/102.png' msk_path = './data/Angeioma/mask/102.png' img = Image.open(img_path) msk = Image.open(msk_path).convert('RGB').resize(img.size) plt.figure(figsize=(16, 12)) plt.subplot(1, 3, 1) plt.imshow(img) plt.subplot(1, 3, 2) plt.imshow(msk, cmap='gray') mix = Image.blend(img, msk, alpha=0.3) plt.subplot(1, 3, 3) plt.imshow(mix)

这种做法可能会导致原图的部分像素变暗。
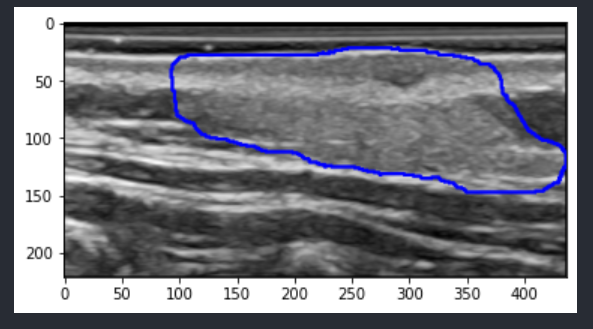
通过mask轮廓
使用cv2.findContours得到mask的轮廓,然后使用cv2.drawContours将轮廓绘制到image中。
img_path = './data/Angeioma/img/108.png' msk_path = './data/Angeioma/mask/108.png' img = Image.open(img_path) msk = Image.open(msk_path).convert('RGB').resize(img.size) img = np.asarray(img) msk = np.asarray(msk)[:, :, 0] # BGR 三层通道相等,取一个通道 contours, _ = cv2.findContours(msk, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) img_copy = img.copy() cv2.drawContours(img_copy, contours, -1, (0, 0, 255), 2) # 原图,轮廓,轮廓编号,颜色,线宽 plt.imshow(img_copy)
后记
对于上述的各个操作,只描述了一些常用的操作和属性,还有更多的细节有待补充。
如果所写内容有误,敬请批评指正。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix