
[软件工程]——代码练习之图片分类
CNN vs FCLayer for MNIST
这里,我们使用MNIST数据集,对卷积神经网络和全连接神经网络进行对比。
准备工作
导入相关库
import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torchvision import datasets, transforms import matplotlib.pyplot as plt import numpy # 一个函数,用来计算模型中有多少参数 def get_n_params(model): np=0 for p in list(model.parameters()): np += p.nelement() return np # 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
加载MNIST数据集
具体的使用方法就不再解释了。提一点的话,DataLoader是一个类,提供的常用操作有:batch_size(每个batch的大小), shuffle(是否进行随机打乱顺序), num_workers(加载数据时使用几个子进程)
input_size = 28*28 # MNIST上的图像尺寸是 28x28 output_size = 10 # 类别为 0 到 9 的数字,因此为十类 train_loader = torch.utils.data.DataLoader( datasets.MNIST('./data', train=True, download=True, transform=transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])), batch_size=64, shuffle=True) test_loader = torch.utils.data.DataLoader( datasets.MNIST('./data', train=False, transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])), batch_size=1000, shuffle=True)
接下来,我们创建神经网络。分别把全连接网络和卷积网络以类的形式构造好
class FC2Layer(nn.Module): def __init__(self, input_size, n_hidden, output_size): # nn.Module子类的函数必须在构造函数中执行父类的构造函数 # 下式等价于nn.Module.__init__(self) super(FC2Layer, self).__init__() self.input_size = input_size # 这里直接用 Sequential 就定义了网络,注意要和下面 CNN 的代码区分开 self.network = nn.Sequential( nn.Linear(input_size, n_hidden), nn.ReLU(), nn.Linear(n_hidden, n_hidden), nn.ReLU(), nn.Linear(n_hidden, output_size), nn.LogSoftmax(dim=1) ) def forward(self, x): # view一般出现在model类的forward函数中,用于改变输入或输出的形状 # x.view(-1, self.input_size) 的意思是多维的数据展成二维 # 代码指定二维数据的列数为 input_size=784,行数 -1 表示我们不想算,电脑会自己计算对应的数字 # 在 DataLoader 部分,我们可以看到 batch_size 是64,所以得到 x 的行数是64 # 大家可以加一行代码:print(x.cpu().numpy().shape) # 训练过程中,就会看到 (64, 784) 的输出,和我们的预期是一致的 # forward 函数的作用是,指定网络的运行过程。这个全连接网络可能看不出啥意义, # 下面的CNN网络可以看出 forward 的作用。 x = x.view(-1, self.input_size) return self.network(x) class CNN(nn.Module): def __init__(self, input_size, n_feature, output_size): # 执行父类的构造函数,所有的网络都要这么写 super(CNN, self).__init__() # 下面是网络里典型结构的一些定义,一般就是卷积和全连接 # 池化、ReLU一类的不用在这里定义 self.n_feature = n_feature self.conv1 = nn.Conv2d(in_channels=1, out_channels=n_feature, kernel_size=5) self.conv2 = nn.Conv2d(n_feature, n_feature, kernel_size=5) self.fc1 = nn.Linear(n_feature*4*4, 50) self.fc2 = nn.Linear(50, 10) # 下面的 forward 函数,定义了网络的结构,按照一定顺序,把上面构建的一些结构组织起来 # 意思就是,conv1, conv2 等等的,可以多次重用 def forward(self, x, verbose=False): x = self.conv1(x) x = F.relu(x) x = F.max_pool2d(x, kernel_size=2) x = self.conv2(x) x = F.relu(x) x = F.max_pool2d(x, kernel_size=2) x = x.view(-1, self.n_feature*4*4) x = self.fc1(x) x = F.relu(x) x = self.fc2(x) x = F.log_softmax(x, dim=1) return x
# CNN结构 可以看出是一个 卷积,ReLU激活,池化,卷积,ReLU激活,池化,全连接,ReLu激活,全连接的过程。
定义训练和测试函数,暂且略过。
对比训练结果
全连接网络:
n_hidden = 8 # number of hidden units
model_fnn = FC2Layer(input_size, n_hidden, output_size)
model_fnn.to(device)
optimizer = optim.SGD(model_fnn.parameters(), lr=0.01, momentum=0.5)
print('Number of parameters: {}'.format(get_n_params(model_fnn)))
train(model_fnn)
test(model_fnn)
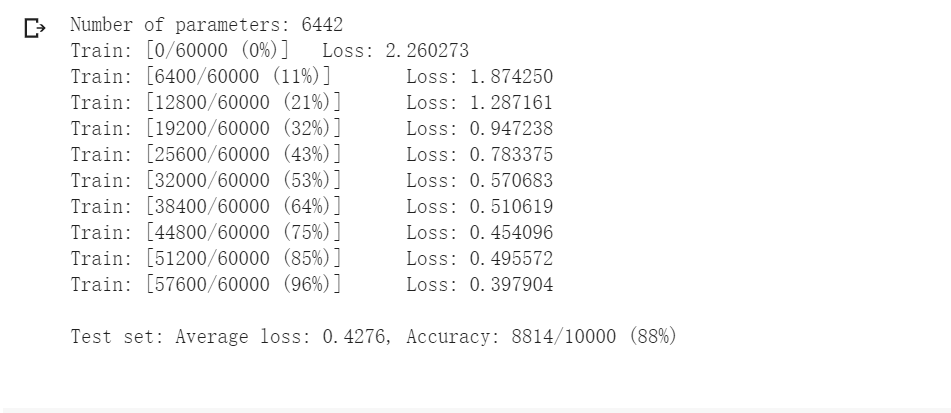
卷积神经网络:
# Training settings n_features = 6 # number of feature maps model_cnn = CNN(input_size, n_features, output_size) model_cnn.to(device) optimizer = optim.SGD(model_cnn.parameters(), lr=0.01, momentum=0.5) print('Number of parameters: {}'.format(get_n_params(model_cnn))) train(model_cnn) test(model_cnn)

可以明显看出,在两种网络参数数量相近的情况下,卷积神经网络具有更好的效果。
卷积神经网络的卷积过程,关注了输入的局部特征,降低了参数数量。因此,我们把输入的像素打乱,破坏局部特征,再观察两种网络的效果。

全连接网络:

卷积神经网络:

可以看到,打乱像素后,卷积神经网络的识别准确率反而低于了全连接网络。
CNN for CIFAR10
我们再使用CIFAR10数据集,使用卷积神经网络进行训练。
CIFAR数据集

定义如下的卷积神经网络
class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) # 卷积,ReLU激活,池化 x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) #展成二维 x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x
经过十次重复训练后,loss仍在1附近。感觉训练效果并不咋样。

观察一下该神经网络对某一组图像的识别效果
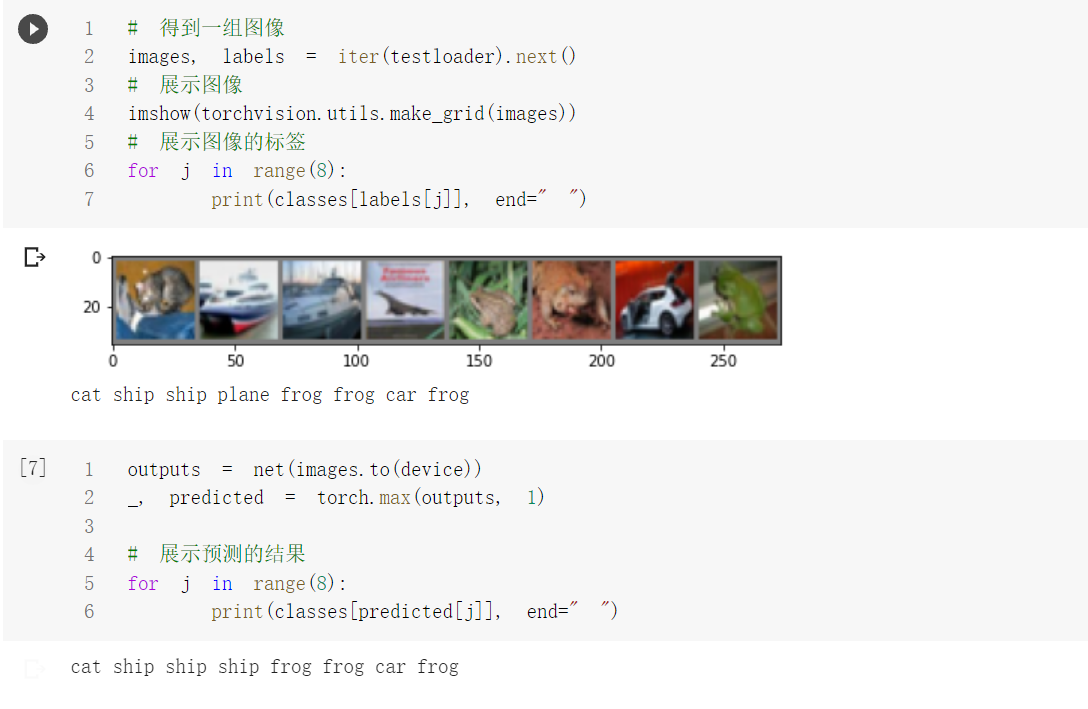
对这一组的识别效果竟然还不错,只有一个出现了识别错误。
但是其整体的准确率只有63%左右

VGG16 for CIFAR10
上个实验的卷积神经网络的识别效果并不好,这次采用新的网络结构VGG16。但毕竟VGG16比较复杂,所以要简化一下,方便训练。
class VGG(nn.Module): def __init__(self): super(VGG, self).__init__() self.cfg = [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'] self.features = self._make_layers(self.cfg) #1 self.classifier = nn.Linear(512, 10) #2 def forward(self, x): out = self.features(x) out = out.view(out.size(0), -1) out = self.classifier(out) return out def _make_layers(self, cfg): layers = [] in_channels = 3 for x in cfg: if x == 'M': layers += [nn.MaxPool2d(kernel_size=2, stride=2)] else: layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1), nn.BatchNorm2d(x), nn.ReLU(inplace=True)] in_channels = x layers += [nn.AvgPool2d(kernel_size=1, stride=1)] return nn.Sequential(*layers)
给出的demo中存在一点小错误,在代码中已经改正。
#1 一个是cfg未定义,在self._make_layers() 参数传递时,需要调用的参数应该是 self.cfg。
#2 self.classifier = nn.Linear(2048, 10) ,在后续执行过程中,遇到 RuntimeError: CUDA error: CUBLAS_STATUS_INVALID_VALUE。经查阅,通常为线性层nn.Linear 定义时数据维度参数与实际数据维度不匹配。
根据cfg中的基本结构,将2048*10修改成512*10。
最后经过10次重复训练,最终的识别成功率提高了不少,达到了84%左右。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号