[软件工程]——深度学习绪论及概述
最近学习了深度学习相关课程的两个视频,算是对深度学习有了一定的理解,现在就写一下总结吧。
主要是挑着感觉有用的和能看得懂的来总结,内容可能有些乱hhh
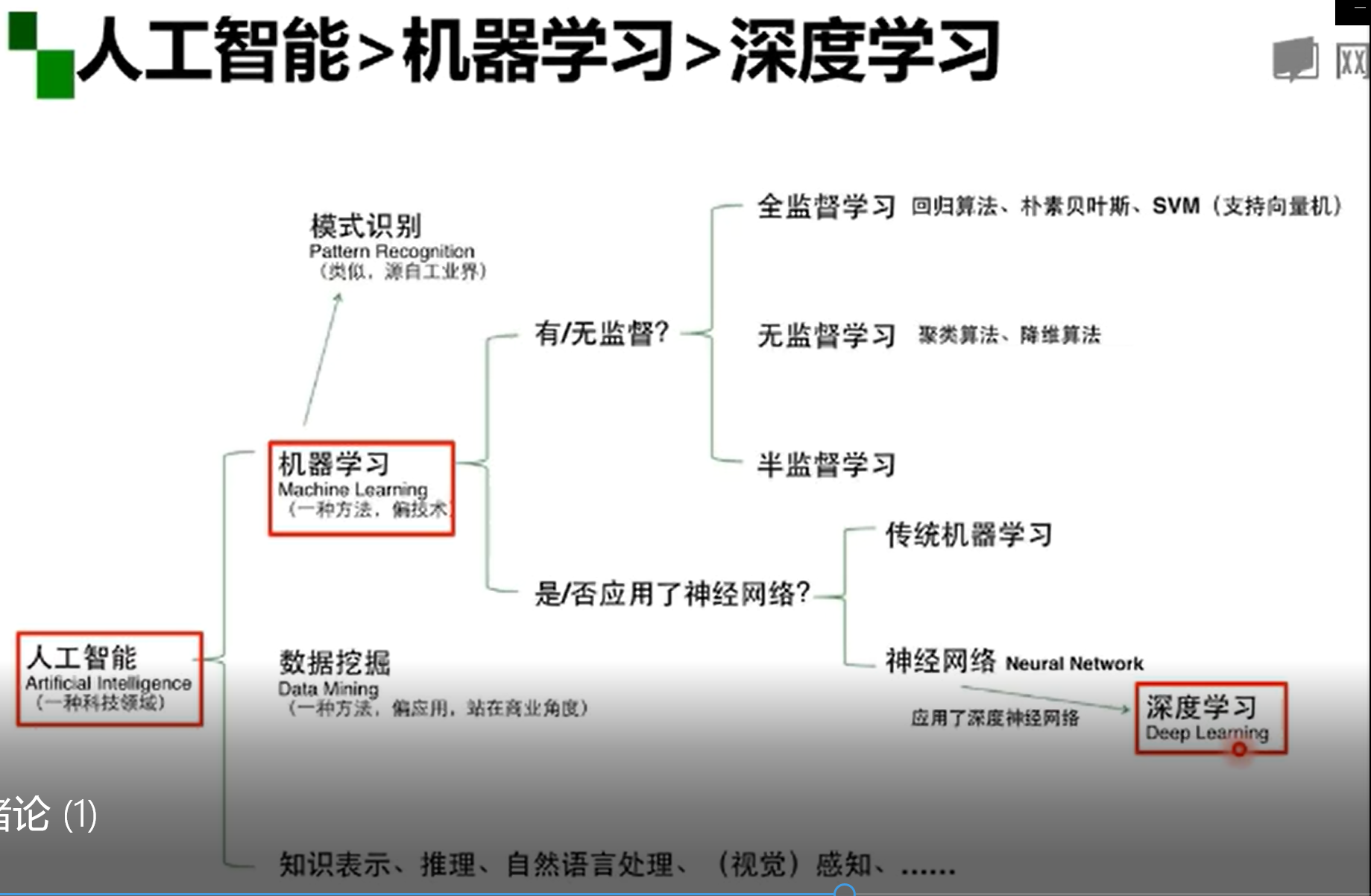
人工智能、机器学习、深度学习
谈到深度学习,我们往往会想到其他各种名词:人工智能、机器学习等等。那么怎么更明确地区分一下呢,它们大概是一个包含关系,即:
人工智能是一个领域,一个目标。机器学习是实现人工智能这个目标的一类方法。而深度学习只是机器学习中很小的一个点。
图灵测试
谈到上述那些名词,就不得不提图灵测试了。图灵测试由艾伦·麦席森·图灵提出,指测试者与被测试者(一个人和一台机器)隔开的情况下,通过一些装置(如键盘)向被测试者随意提问。
进行多次测试后,如果机器让平均每个参与者做出超过30%的误判,那么这台机器就通过了测试,并被认为具有人类智能。这可以称得上是人工智能的开端了。
机器学习
机器学习就是:计算机利用经验提高自身性能,基于经验数据的函数估计问题,理解数据。总结一下就是从数据中自动提取有意义的模式。
学什么?
机器学习适合学习数据规模大、规则复杂而且有意义的模式。例如:预测婴儿性别等。
怎么学?
机器学习需要模型,策略和算法。

根据数据标记、数据分布、和建模对象可以分许多种模型。
数据标记可以分为监督学习模型、无监督学习模型,以及半监督学习模型和强化学习模型。
数据分布可以分为参数模型和非参数模型。
建模对象可以分为判别模型和生成模型。
深度学习
一般是在机器学习中,使用了深度神经网络的学习称之为深度学习。(Deep Learning)
深度学习比较通俗的做法可以被很简单地概括。

浅层神经网络
生物神经元 多输入单输出,空间整合和时间整合、兴奋输入/抑制输入,阈值特性。我们根据这些特点,可以构建出人工神经元(MP神经元)。
它们是神经网络的基本零部件。
激活函数
用于神经元继续传递信息、产生新连接的概率。
没有激活函数,层层之间相当于矩阵相乘,多层和一层一样,只能拟合线性函数。
常见的激活函数有:Sigmoid函数、tanh函数、ReLU修正线性单元、Leaky ReLU。

感知器
可以学习的人工神经网络
单层感知器可以实现逻辑与或非功能,但实现不了异或问题。于是出现了多层感知器。
万有逼近定理
神经网络学习如何利用矩阵的线性变换加激活函数的非线性变换,将原始输入空间投影到线性可分的空间去分类、回归。
一个隐层包含足够多的神经元,三层前馈神经网络(输入—隐层—输出),能以任意精度逼近任意预定的连续函数
隐层足够宽时,双隐层感知器(输入—隐层1—隐层2—输出),可以逼近任意非连续函数
增加节点数:增加维度,线性转换能力。
增加层数:层架激活函数的次数,增加非线性转换次数。
深度和宽度对函数复杂度的贡献是不同的,深度贡献是指数级增长的,一般更倾向于“瘦高”的网络。
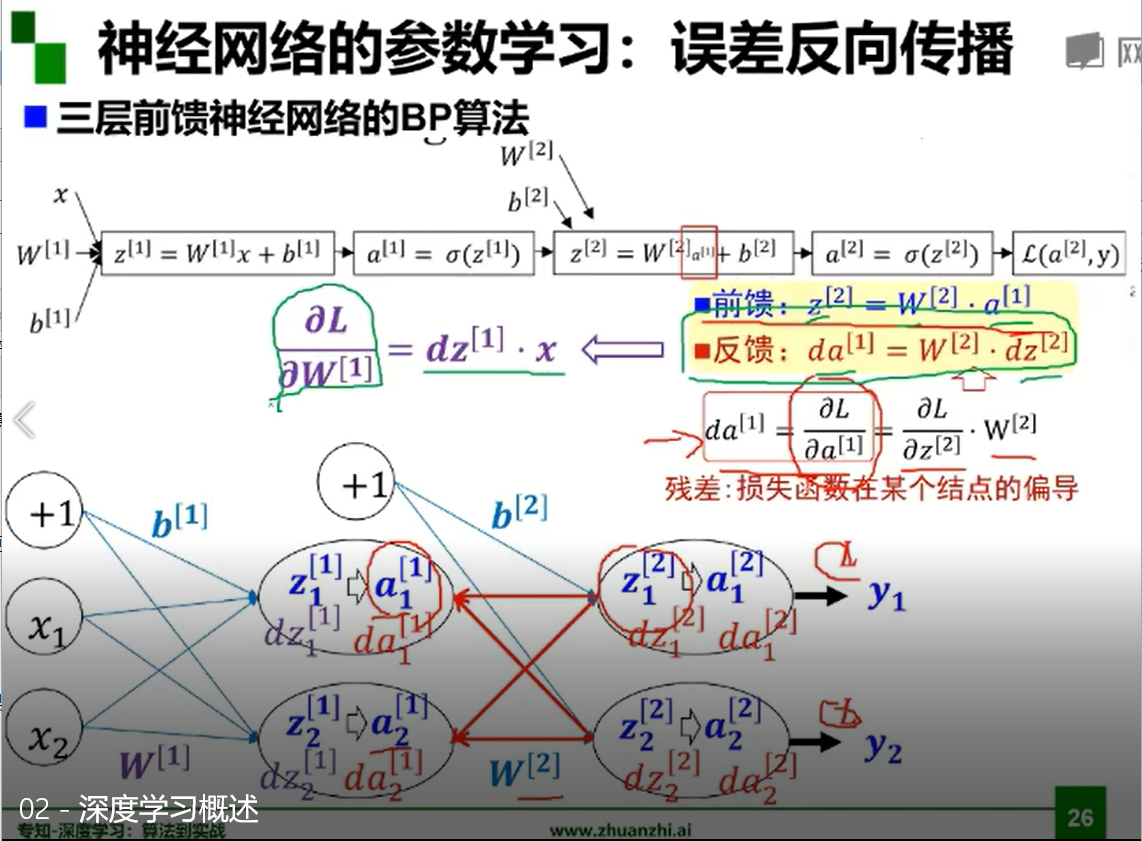
误差反向传播
多层神经网络可以看成是一个复合的非线性多元函数。
输入数据后进行前向传播,在最后一层有输出,最后的输出和期待的正确结果会有损失,或者误差。利用这个误差回传,更新神经网络。
误差的反向传播用到了梯度。
梯度、梯度下降和梯度消失
梯度:方向是最大方向导数的方向,模为方向导数的最大值。
参数沿负梯度方向更新可以使函数值下降。
增加深度会造成梯度消失,误差无法传播,多层网络容易陷入局部极值,难以训练。

根据激活函数的选择,某些点的导数会很小,最终导致梯度的消失。
遇到的问题
感觉在视频学习中确实是学习到了不少内容,对深度学习之类的理论有了更清晰的了解。但是也遇到了不少问题。
首先是不少数学知识都忘了个差不多,在误差反向传播这部分内容里,听不太懂,也跟不上公式讲解的速度,然后理解的就不透彻。
然后是对梯度那个地方也有些问题。参数沿负梯度方向更新可以使函数值下降,会找到局部极值,乃至最小值。但是我不太明白这个最小值的意义是什么。
最后就是玻尔兹曼机这个地方吧,还是因为数学那块忘的有点多加上内容有点多,没咋听懂。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号