P11244 解题报告
题目传送门
题目大意已经很清楚,不再赘述。
思路:
将所有序列的状态分为
先给出一个定义,序列的跨度:
定义一个序列
第一阶段:
首先注意到
第二阶段:
当所有序列都有序后再进行操作
第三阶段:
这时候操作
那么为什么第二阶段的归并次数不会超过
这里我用了数学归纳法来证明。
命题:有
当
当
那么当
引理1:
设两个序列为且 的跨度不是包含关系, 的跨度的右端点大于等于 的跨度右端点,则对于操作 进行了有效归并操作后,设原来的跨度分别为 ,新得到的跨度分别为 ,则有 证明:
设
中的最大值为 ,最小值是 , 中的最大值为 ,最小值是 ,那么 的跨度为 , 的跨度为 。 因为只有当
时才归并,且归并必定将足够多的等于 的项移到 中,也必定会将足够多的等于 的项移到 中。 设新得到的
的跨度分别为 ,那么必然有 ,而 这两个不会变,故有 。 证明完毕。
这说明:当所有操作的两个序列跨度不相互包含时,设势能函数
并且根据引理
但是还有一种可能:当两个序列的跨度相互包含的情况呢?
显然上述引理就不满足了,比如归并
表面上看起来第二个序列变为了
先考虑以下这种情况:
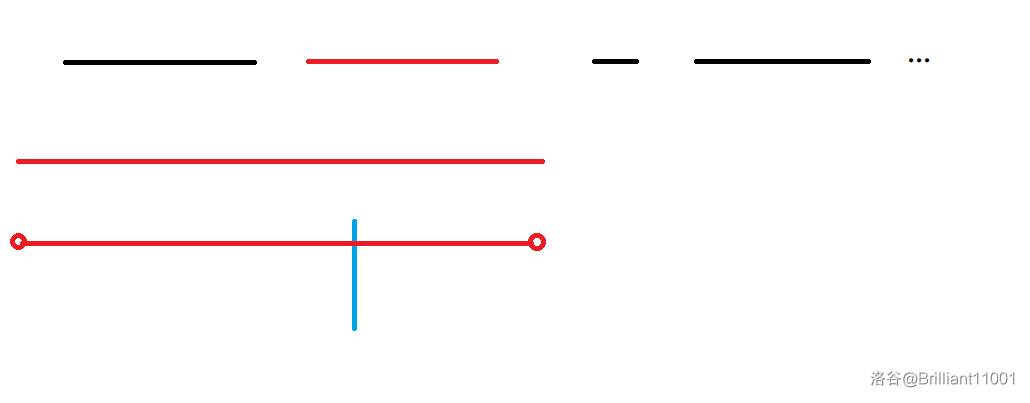
第一行表示的是已经互不相交的
左红圈表示
那么很轻松就能得出蓝色线一定是在
当蓝线往左移动时,
证明完毕。
综上所述:总的时间复杂度不会超过
非常感谢你还能看到这里,本人实力有限,这种证明方法感觉太过繁琐,不如官方题解的证明。
(先猜后证)
#include <queue>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 2000010;
int n, m, q;
int a[21][N];
bool st[N];
int tmp[N << 1];
int id[21];
int main() {
scanf("%d%d%d", &n, &m, &q);
for(int i = 1; i <= m; i++)
for(int j = 1; j <= n; j++)
scanf("%d", &a[i][j]);
for(int i = 1; i <= m; i++) id[i] = i;
int op, x, y;
while(q--) {
scanf("%d%d%d", &op, &x, &y);
if(op == 1) {
int xx = x, yy = y;
x = id[x], y = id[y];
if(st[x] && st[y]) {
if(a[x][n] > a[y][1]) {
if(a[x][1] >= a[y][n])
swap(id[xx], id[yy]);
else {
int pos1 = lower_bound(a[x] + 1, a[x] + n + 1, a[y][1]) - a[x];
int pos2 = lower_bound(a[y] + 1, a[y] + n + 1, a[x][n]) - a[y];
if(a[x][pos1] == a[y][1]) pos1++;
if(a[y][pos2] == a[x][n]) pos2--;
if(pos2 == n + 1) pos2--;
int p1 = pos1, p2 = 1, top = 0;
while(p1 <= n && p2 <= pos2) {
if(a[x][p1] < a[y][p2]) tmp[++top] = a[x][p1++];
else tmp[++top] = a[y][p2++];
}
while(p1 <= n) tmp[++top] = a[x][p1++];
while(p2 <= pos2) tmp[++top] = a[y][p2++];
top = 1;
for(int i = pos1; i <= n; i++)
a[x][i] = tmp[top++];
for(int i = 1; i <= pos2; i++)
a[y][i] = tmp[top++];
}
}
}
else {
if(!st[x]) sort(a[x] + 1, a[x] + n + 1);
if(!st[y]) sort(a[y] + 1, a[y] + n + 1);
st[x] = st[y] = true;
int pos1 = lower_bound(a[x] + 1, a[x] + n + 1, a[y][1]) - a[x];
int pos2 = lower_bound(a[y] + 1, a[y] + n + 1, a[x][n]) - a[y];
if(a[x][pos1] == a[y][1]) pos1++;
if(a[y][pos2] == a[x][n]) pos2--;
if(pos2 == n + 1) pos2--;
int p1 = pos1, p2 = 1, top = 0;
while(p1 <= n && p2 <= pos2) {
if(a[x][p1] < a[y][p2]) tmp[++top] = a[x][p1++];
else tmp[++top] = a[y][p2++];
}
while(p1 <= n) tmp[++top] = a[x][p1++];
while(p2 <= pos2) tmp[++top] = a[y][p2++];
top = 1;
for(int i = pos1; i <= n; i++)
a[x][i] = tmp[top++];
for(int i = 1; i <= pos2; i++)
a[y][i] = tmp[top++];
}
}
else printf("%d\n", a[id[x]][y]);
}
return 0;
}
其实也可以用 vector 直接
这一场怎么这么奇怪?


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!
2023-11-03 CSP-J/S 2023 游记