SP17123 解题报告
题目传送门
扫描线是一种求矩形面积并或周长并的好方法。
假设在一个平面上有几个矩形,要求它们共覆盖了多大的面积。由于矩形可能会有重叠的地方,所以最后要求的图形就是一个不规则的图形。
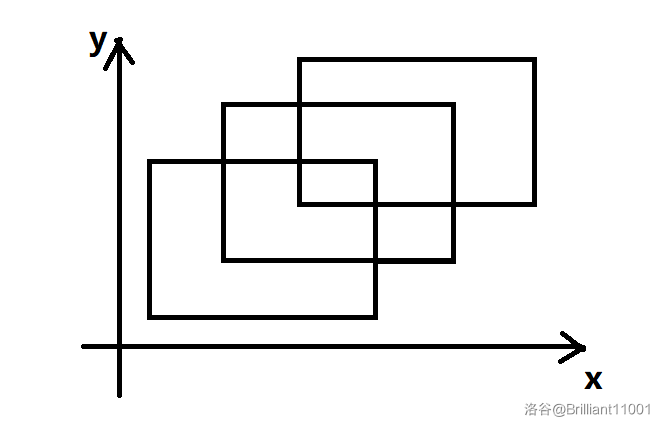
要求它的面积十分复杂,特别是在矩形数量很大时。为了解决这个问题,扫描线法应运而生。
想象一下,有一根看不见的直线从下到上扫过这个平面。在扫描的过程中,直线上的一些线段会被给定的矩形覆盖。如果我们将这些覆盖的线段长度进行积分,就可以得到矩形的面积之和。
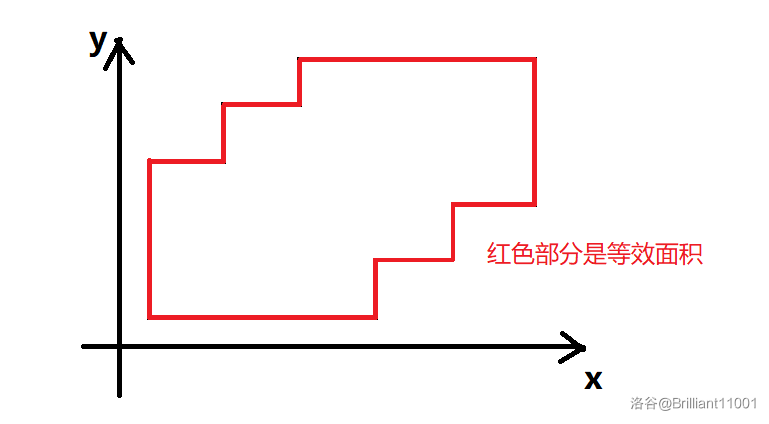
如图所示:

图是我从 OI WiKi 上偷的。
这时候就有一个疑问了:这玩意儿和线段树有什么关系呢?
先别慌,我们慢慢分析。
由图可知:直线上被并集图形覆盖的长度只会在每个矩形的上下边界处发生变化。换言之,整个并集图形可以被分成
为了快速计算出截线段长度,可以将横边赋上不同的权值,具体为:对于一个矩形,其下边权值为
然后把所有的横边按照
我们维护一条扫描线,将这条线逐渐向上平移,遇到每一根横着的线就停下来,算算目前扫描线上被覆盖的长度和与上次停下相比走过了多少距离,两者相乘后累加到 ans 里。
然后再看目前遇到的这根线,如果是
朴素的做法是维护一个数组
这样,每遇到一条
这样做的时间复杂度最坏为
考虑优化。
容易发现这个算法的瓶颈在于朴素的区间加和区间减,所以用线段树来维护。
建立一棵线段树,维护两个值:
-
该线段被覆盖的次数;
-
该线段被覆盖的长度。
那线段树该怎么建立?
细节一:
一般这种类型的题矩形的坐标要么就特别大,要么就可能是小数,这时候就需要进行离散化。一定要注意下标的转化!
值得注意,线段树中的叶子节点表示的区间
考虑把线段树每个节点
细节二:
虽然有区间修改操作,但是并不需要懒标记。
因为只有当该线段被覆盖的次数大于
那为什么是正确的呢?
我们维护了两个值:
-
当
-
当
综上所述,不需要
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
const int N = 100010;
typedef long long ll;
struct Segment{
int y, x1, x2;
int val;
bool operator <(const Segment &o) const {
return y < o.y;
}
}seg[N << 1];
struct node{
int l, r;
//线段树的节点tr[u]表示的线段树Node区间[tr[u].l,tr[u].r]维护离散化后的区间 --> [y_l, y_r + 1]
int cnt;
int len;
#define l(x) tr[x].l
#define r(x) tr[x].r
#define cnt(x) tr[x].cnt
#define len(x) tr[x].len
}tr[N << 4];
vector<int> xs;
int n;
inline int ls(int p) {return p << 1;}
inline int rs(int p) {return p << 1 | 1;}
int find(int x) { //返回x在vector中储存的下标
return lower_bound(xs.begin(), xs.end(), x) - xs.begin();
}
void pushup(int p) {
if(cnt(p)) len(p) = xs[r(p) + 1] - xs[l(p)]; //若全部覆盖,被覆盖的长度就是区间长度
else if(l(p) != r(p)) {
// 如果tr[u].cnt等于0其实有两种情况:
// 1. 完全覆盖. 这种情况由modify的第一个if进入.
// 这时下面其实等价于把"由完整的l, r段贡献给len的部分清除掉",
// 而留下其他可能存在的子区间段对len的贡献
// 2. 不完全覆盖, 这种情况由modify的else最后一行进入.
// 表示区间并不是完全被覆盖,可能有部分被覆盖,所以要通过儿子的信息来更新
len(p) = len(ls(p)) + len(rs(p));
}
else len(p) = 0; //表示为叶子节点且该线段没被覆盖,为无用线段,长度变为0
}
void build(int p, int l, int r) {
l(p) = l, r(p) = r;
if(l != r) {
int mid = l + r >> 1;
build(ls(p), l, mid);
build(rs(p), mid + 1, r);
}
}
void modify(int p, int l, int r, int val) { //表示从线段树中l点到r点的出现次数 + val
if(l <= l(p) && r >= r(p)) {
cnt(p) += val;
pushup(p); //更新该节点的len
return ;
}
int mid = l(p) + r(p) >> 1;
if(l <= mid) modify(ls(p), l, r, val);
if(r > mid) modify(rs(p), l, r, val);
pushup(p);
}
int main() {
scanf("%d", &n);
int x1, x2, y1, y2;
for(int i = 0, j = 0; i < n; i++) {
scanf("%d%d%d%d", &x1, &y1, &x2, &y2);
seg[j++] = {y1, x1, x2, 1};
seg[j++] = {y2, x1, x2, -1};
xs.push_back(x1);
xs.push_back(x2);
}
sort(seg, seg + n * 2); //将横着的线段按照y坐标从小到大排序
sort(xs.begin(), xs.end());
xs.erase(unique(xs.begin(), xs.end()), xs.end()); //离散化去重
//离散化后纵坐标有2n个点, 2n-1个区间,构建线段树,线段树的节点维护这些区间tr[i] --> [y_i, y_i+1],所以线段树的节点个数与区间个数相同2n-1
build(1, 0, xs.size() - 2); //共有xs.size() - 1个y点位,就会构成xs.size() - 2条线段
ll res = 0;
for(int i = 0; i < n * 2; i++) {
if(i > 0) res += 1ll * tr[1].len * (seg[i].y - seg[i - 1].y);
modify(1, find(seg[i].x1), find(seg[i].x2) - 1, seg[i].val); //更新
//这里一定要把原区间 变换到 线段树表示的区间
//线段树的节点 维护 离散化后的区间:tr[u] --> [tr[u].l,tr[u].r] --> [xs_l, xs_r + 1]
//原区间: seg[i].x1 ~ seg[i].x2
//离散化后的区间: find(seg[i].x1) ~ find(seg[i].x2)
//线段树中的区间: find(seg[i].x1) ~ find(seg[i].x2) - 1
}
printf("%lld\n", res);
return 0;
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】