二叉搜索树(BST)
二叉搜索树的定义及性质
二叉搜索树(
给定一棵二叉树,树上的每一个节点带有一个权值。所谓“
- 该节点的权值不小于它的左子树中任意节点的权值;
- 该结点的权值不大于它的右子树中任意节点的权值。
满足上述性质的二叉树就是一棵 “二叉查找树”(
比如:
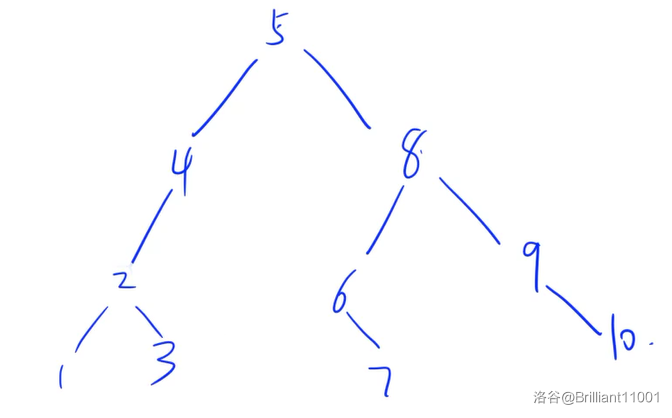
同时珂以发现,它的中序遍历为
二叉搜索树的一些操作
1. 建立
为了避免越界,减少边界情况的特殊判断,一般在
仅由这两个节点构成的
为了方便起见,在接下来的操作中,假设
struct BST {
int ls, rs;
int val;
int cnt;
int siz;
}a[N];
int tot, root, inf = 0x7fffffff;
int New(int val) {
a[++tot].val = val;
return tot;
}
void build() {
New(-inf);
New(inf);
root = 1, a[1].rs = 2;
}
2. 检索
这个比较简单,就不放代码了,只给出思路。
假如说要找一个权值为
设当前搜索到的节点为
-
若
-
若
(1)若
(2)若
-
若
(1)若
(2)若
3. 插入
在
与
在发现要走向的
void insert(int &p, int val) { //注意p是引用,其父节点的 l 或 r 值会被同时更新
if(p == 0) {
p = New(val);
return ;
}
if(val == a[p].val) {
a[p].cnt++;
return ;
}
if(val < a[p].val) insert(a[p].l, val);
else insert(a[p].r, val);
}
4. 求前驱/后缀
以求前驱为例,先初始化
检索完成后,有三种可能的结果:
-
没有找到
-
找到了权值为
-
找到了权值为
int get_pre(int val) { //求前驱
int ans = 1; //a[1].val = -0x7fffffff
int p = root;
while(p) {
if(val == a[p].val) { //检索成功
if(a[p].ls) {
p = a[p].ls; //从左子节点出发
while(a[p].rs) p = a[p].rs; //一直向右走
ans = p;
}
break;
}
//每经过一个点,都尝试更新前驱
if(val > a[p].val && a[p].val > a[ans].val) ans = p;
p = val > a[p].val ? a[p].rs : a[p].ls; //检索
}
return ans;
}
int get_next(int val) { //求后继
int ans = 2; //a[2].val = 0x7fffffff
int p = root;
while(p) {
if(val == a[p].val) {
if(a[p].rs) {
p = a[p].rs;
while(a[p].ls) p = a[p].ls;
ans = p;
}
break;
}
if(val < a[p].val && a[p].val < a[ans].val) ans = p;
p = val > a[p].val ? a[p].rs : a[p].ls;
}
return ans;
}
//递归写法
int get_pre(int p, int val) {
if(!p) return -inf;
if(val <= tr[p].val) return get_pre(tr[p].ls, val);
return max(tr[p].val, get_pre(tr[p].rs, val));
}
int get_next(int p, int val) {
if(!p) return inf;
if(val >= tr[p].val) return get_next(tr[p].rs, val);
return min(tr[p].val, get_next(tr[p].ls, val));
}
5. 删除
从
首先通过检索找到权值为
若
若
若
void remove(int &p, int val) {
if(p == 0) return ;
if(val == a[p].val) {
if(!a[p].ls) p = a[p].rs; //没有左子树,则右子树代替 p 的位置,注意 p 是引用
else if(!a[p].rs) p = a[p].ls; //没有右子树,则左子树代替 p 的位置,注意 p 是引用
else { //有两个儿子
//求后继节点
int next = a[p].rs;
while(a[next].ls > 0) next = a[next].ls;
//next 一定无左子树
remove(a[p].rs, a[next].val);
//让节点 next 代替节点 p 的位置
a[next].ls = a[p].ls, a[next].rs = a[p].rs;
p = next;
}
return ;
}
if(val < a[p].val) remove(a[p].ls, val);
else remove(a[p].rs, val);
}
二叉搜索树的时间复杂度
在随机数据中,
而为了维持


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App