暴力数据结构——ODT 珂朵莉树
有人为了 CF896C 发明了这个算法,这道题又和珂朵莉有关,所以这个算法叫做珂朵莉树。
另外,由于发明者
也有个正统名字叫颜色段均摊,但是还是叫珂朵莉树好听。
之所以突然想学这个数据结构是因为之前做了一道题 SP13015,看到的第一眼就是线段树,等到把这道题 A 了之后打开标签才发现是珂朵莉树,出于好奇心的驱使,才有了这篇博客。
珂朵莉可爱捏!
前置芝士:
Warning!
但要求数据随机,随机下跑得很快,开了
数据不随机时间复杂度就是
对一个序列,进行一个区间推平操作。就是把一个范围内,比如
由于区间推平操作,所以序列中的数是一段一段的,而且每一段是同一个数。
所以我们将每个这样的区间打包成一个三元组
这样的话,只需要一个结构体就行了。
struct node{
int l, r;
mutable ll val; //mutable 方便以后修改
node(int l_ = 0, int r_ = -1, ll val_ = 0) :l(l_), r(r_), val(val_) {}
bool operator <(const node &other) const{ //重载成小于
return l < other.l;
}
};
typedef set<node>::iterator IT;
set <node> s;
借大佬的图一用
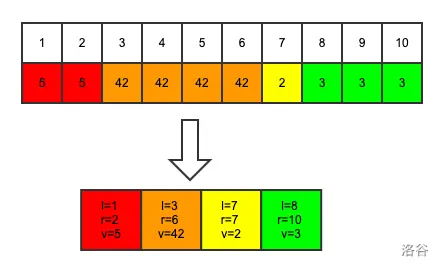
核心操作:
在推平操作的进行中,一些区间可能要被合并成一个区间,也可能被分成几个新区间。
这时候就需要用到
IT split(int pos) {
IT it = s.lower_bound(node(pos)); //按 l 找包含 pos 的 node
if(it != s.end() && it -> l == pos) return it; //若 pos 是一个区间的开头,就直接返回该区间迭代器
--it; //由于找到的是 pos 后面的区间,所以要先--才是包含它的区间
int l = it -> l, r = it -> r;
ll val = it -> val;
s.erase(it); //先把此区间删除
s.insert(node(l, pos - 1, val)); //插入切割后的第一个区间
return s.insert(node(pos, r, val)).first; //插入切割后的第二个区间并返回值
//insert函数返回pair,其中的first是新插入结点的迭代器
}
那么我们按照
还有两种情况是,我们找到的这个区间是正好比包含
对应区间推平操作。因为区间
void assign(int l, int r, ll val) {
IT itr = split(r + 1), itl = split(l);
s.erase(itl, itr);
s.insert(node(l, r, val));
}
注意: 必须要先
比如现在要从
其他操作
void change(int l, int r, ll val) { //暴力套就完事了
IT itr = split(r + 1), itl = split(l);
for(IT it = itl; it != itr; it++) {
//to do
}
}
珂朵莉树只有当数据随机时才有比较好的表现,这是因为她的时间复杂度是期望复杂度。比如一共有
以上只是我方便自己理解的粗略证明,严谨、正确性方面不保证。
好好好,正确又严谨的证明如下:(再次借大佬的图)





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】