数据结构复习2
5.并查集
它有两个功能:将两个集合合并和询问两个元素是否在同一个集合内。
不妨设想一下,假如不使用并查集,用暴力的做法,那么第一个操作的时间复杂度约为
但如果使用了并查集,则可以将近
基本原理:用树的形式来维护每个集合,集合的编号就是根节点的编号。对于树的每一个节点都记录它的父节点,
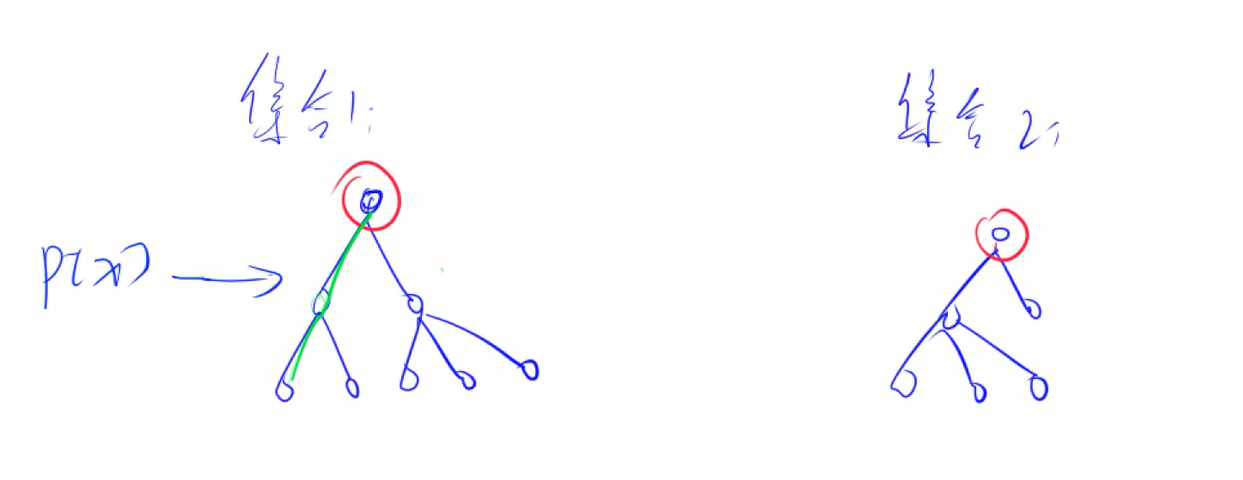
Q1:如何判断树根?
A1:对于每个非树根点,它的父节点都不是它本身,树根的父节点是它本身。
if(p[x] == x)
Q2:如何求x的集合编号?
A2:
while(p[x] != x) x = p[x];
Q3:如何合并两个集合?
A3:假设
但是求集合编号的时间复杂度还是挺高的,优化:路径压缩。就是说当搜到根节点后,将搜索时经过的点的父节点直接指向根节点。
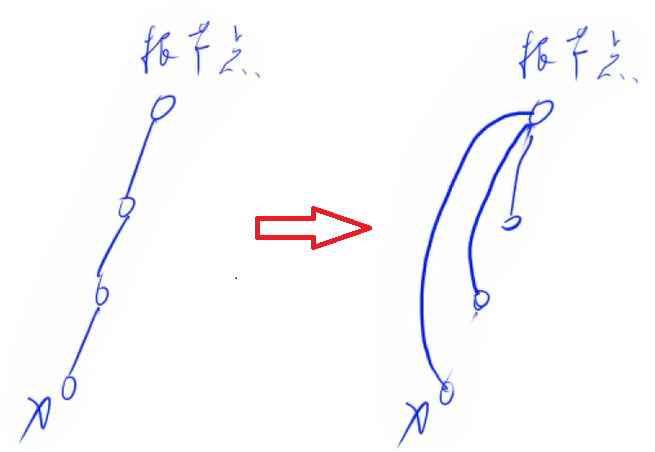
上模板题!
P3367 【模板】并查集
6.堆
堆是一棵完全二叉树,同时它的每棵子树也是堆。
总结得太全面啦!
(这里复习手写堆)
手写堆支持
1.插入一个数
2.求集合当中的的最小值
3.删除最小值
4.删除任意一个元素
5.修改任意一个元素
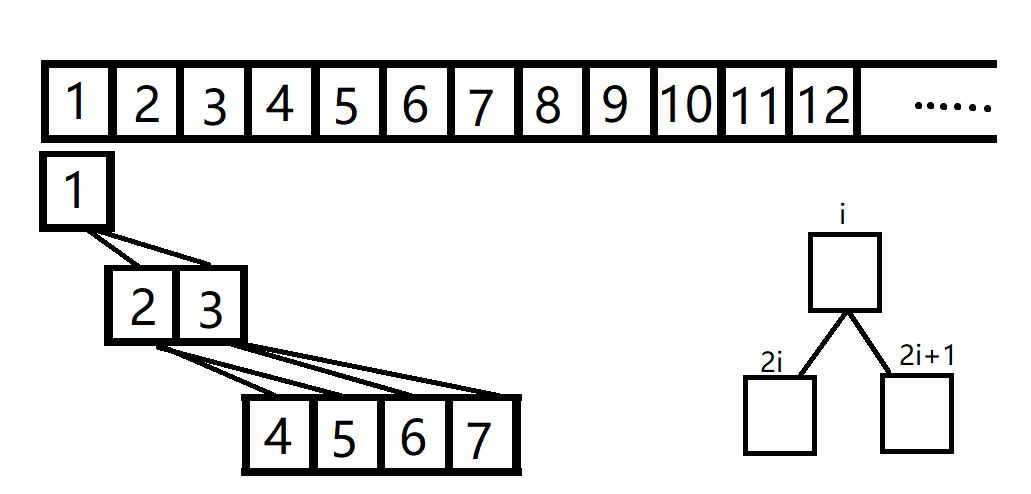
堆的储存:用一维数组来储存堆,其中,根节点储存在下标
如图所示:
基本操作:(以小根堆为例)
-
-
比如:
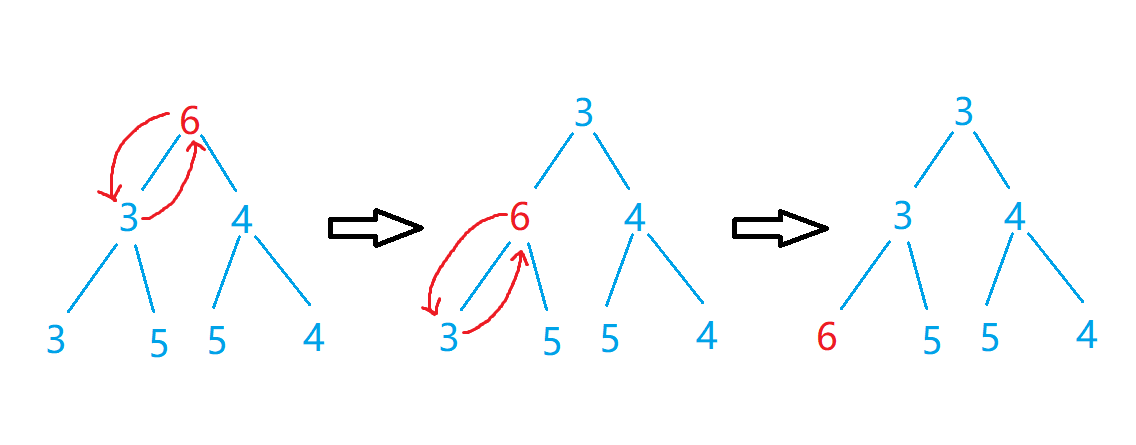
//插入一个数
heap[++size] = x, up(size);
//求集合当中的的最小值
cout << heap[1] << endl;
//删除最小值
heap[1] = heap[size], size--, down(1);
//删除任意一个元素
heap[x] = heap[size], size--, down(x), up(x);
//修改任意一个元素
heap[x] = k, down(x), up(x);
//上移
void up(int x) { //O(log n) (大根堆反过来)
while(x / 2 && heap[x] < heap[x / 2]) { //若父节点大于子节点
swap(heap[x], heap[x / 2]); //交换
x /= 2; //向上走
}
}
//下移
void down(int x) { //O(log n)(大根堆反过来)
int t = x;
if(x * 2 <= size && heap[t] > heap[x * 2]) t = 2 * x; //若左儿子存在且小于父节点,记录
if(x * 2 + 1 <= size && heap[t] > heap[x * 2 + 1]) t = 2 * x + 1; //若右儿子存在且小于父节点,记录
if(t != x) { //若子节点满足条件
swap(heap[t], heap[x]); //交换
down(t); //向下走
}
}
7.Hash表
哈希表也叫散列表,是一种数据结构,它提供了快速的插入操作和查找操作,无论哈希表总中有多少条数据,插入和查找的时间复杂度都近似为
哈希表也有自己的缺点,哈希表是基于数组的,我们知道数组创建后扩容成本比较高,所以当哈希表被填满时,性能下降的比较严重。
哈希表采用的是一种转换思想,其中一个重要的概念是如何将「键」或者「关键字」转换成数组下标。就比如普通数组的下标是 int 类型的,但哈希表可以把 string 类型的转换成下标。
用于转换的函数就是哈希函数,比如一个哈希函数
哈希函数通常形式:
但是这样会有一个问题,在映射时可能会出现两个不同的数映射成同一个下标,这种情况被称为哈希冲突。哈希冲突是不可避免的,解决方法有两种:
1.拉链法
2.开放寻址法
下面就分别讲一下两种方法。
拉链法顾名思义,就是把冲突的数在此下标处拉一条链表来记录。
比如
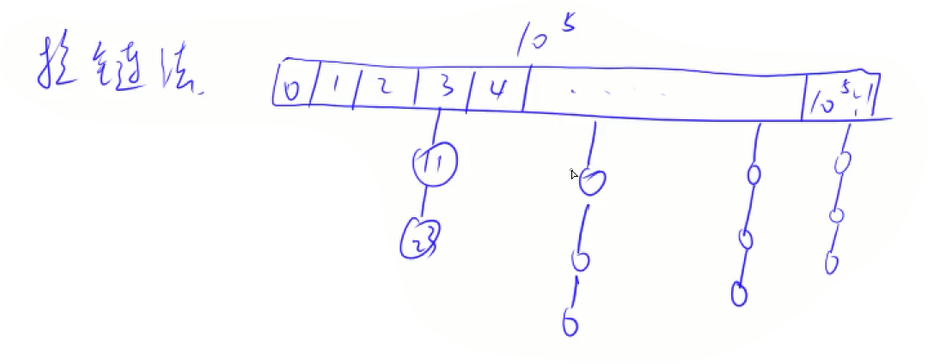
代码:
int h[N], e[N], ne[N], idx;
void insert(int x) {
int k = (x % N + N) % N; //防止当x为负数时模出来为负
e[idx] = x, ne[idx] = h[k], h[k] = idx++; //链表的插入操作
}
bool find(int x) {
int k = (x % N + N) % N;
for(int i = h[k]; i != -1; i = ne[i]) { //遍历链表1
if(e[i] == x) return true; //找到
}
return false; //未找到
}
开放寻址法
只开一个一维数组,但长度要开到
插入:若
查找:从下标
删除:按照查找的方式找到
代码:
int find(int x) {
int k = (x % N + N) % N;
while(h[k] != null && h[k] != x) {
k++;
if(k == n) k = 0; //循环看第一个位置
}
return k; //若未被占用则表示x应该放的位置,若找到则表示x的位置
}
字符串哈希方式:字符串前缀哈希法。
举个例子:字符串
h[0] = 0;
h[1] = "A"的hash值
h[2] = "AB"的hash值
h[3] = "ABC"的hash值
h[4] = "ABCD"的hash值
它们的 hash 值该怎么求?其实把每一个字符串看成是一个
注:
1.不能将字母映射成
2.我们人品足够好, 不会发生冲突当
当我们知道
不妨先画个图:

由图可知,想要求出
所以在对一个字符串的 hash 值进行预处理时可以:
h[0] = 0; //千万不要忘记!
for(int i = 1; i < len; i++) {
h[i] = h[i - 1] * p + str[i];
}
模板题:P3370 【模板】字符串哈希
7.STL 容器的使用
1.vector
变长数组,使用了倍增的思想。
头文件:#include <vector>
2.string
字符串,substr(), c_str()
3.queue,priority_queue
队列,push(), front(), pop()
4.stack
栈,push(), top(), pop()
5.deque
双端队列
6.set, map, multiset, multimap
基于平衡二叉树(红黑树),动态维护有序序列。
7.unordered_map, unordered_set, unordered_multimap, unordered_multimap
哈希表
8.bitset
压位


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】