数据结构复习
大纲:

1.链表
- 单向链表
它是一种由节点构成的数据结构,每个节点都有对应的值和一个指向下一个点的指针,就像用链子串联起来一样。
如图所示:
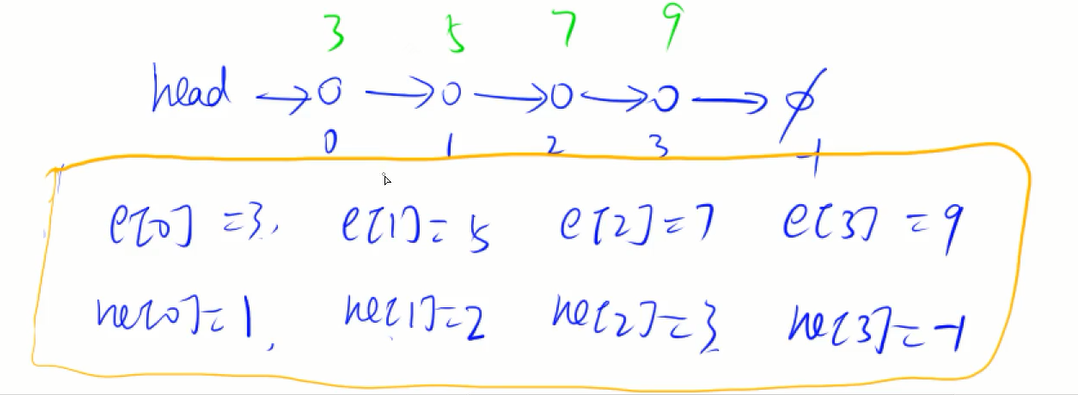
用数组模拟单向链表需要如下定义:
int head, e[N], ne[N], idx;
//head是头指针,初始指向空,e[i]表示第i个插入的点的值,ne[i]表示第i个插入
的点的下一个点的下标,idx记录现在插入了几个点
以下是各种简单操作:
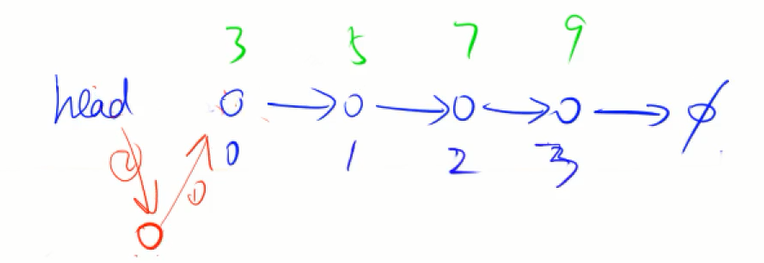
//在第a个节点插入b
void add(int a, int b) {
e[idx] = b, ne[idx] = ne[a], ne[a] = idx++;
}
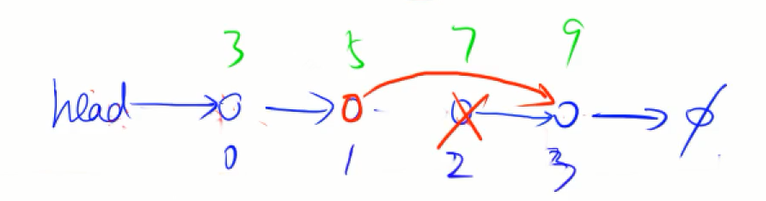
//删除第k个节点的后面的节点
void remove(int k) {
ne[k] = ne[ne[k]];
}
//查询第k个节点后的节点
void find(int k) {
cout << e[ne[k]] << endl;
}
B3631 单向链表
- 双向链表
单向链表的升级版,每个节点有两个指针,一个指向前节点,一个指向后节点;
如图所示:
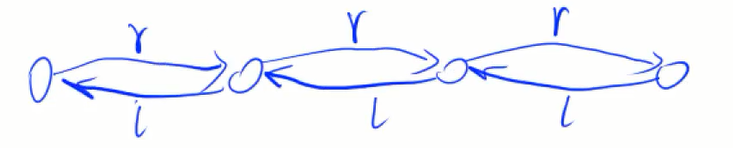
以下是各种简单操作:
//初始化
void init() {
r[0] = 1, l[1] = 0;
idx = 2;
}
//在第k个节点的后面插入x
void add(int k, int x) {
e[idx] = x;
l[idx] = k;
r[idx] = r[k];
l[r[k]] = idx; //必须先这一步再修改r[k]
r[k] = idx;
}
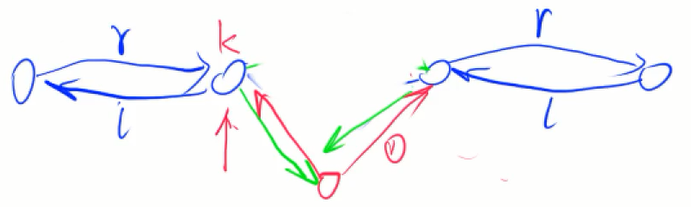
//删掉第k个节点
void remove() {
r[l[k]] = r[k];
l[r[k]] = l[k];
}
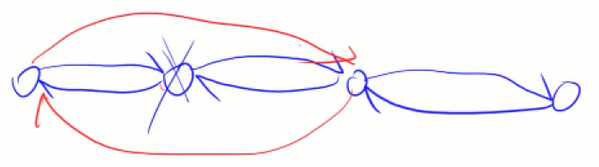
2.栈、队列
栈:先进先出。
队列:后进后出。
(由于对这两个数据结构的基础再熟悉不过了,其实每天都在复习,所以就不妨放在这里了,直接讲进阶知识)
单调栈
P5788 【模板】单调栈
本蒟蒻认为它和单调队列都比较抽象
对于这个问题如果采用暴力做法,写两层循环,则在最坏情况的时间复杂度为
如图所示:
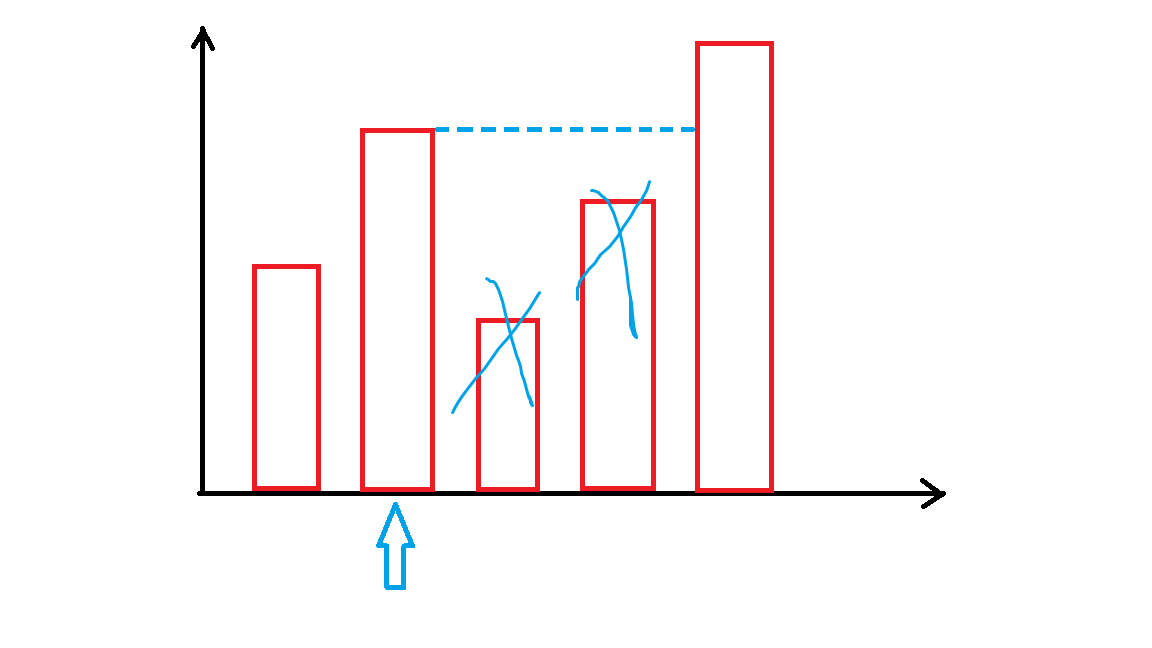
然后又因为删除时是从前面弹出,这和栈结构十分相似,所以称之为单调栈。
如图所示:
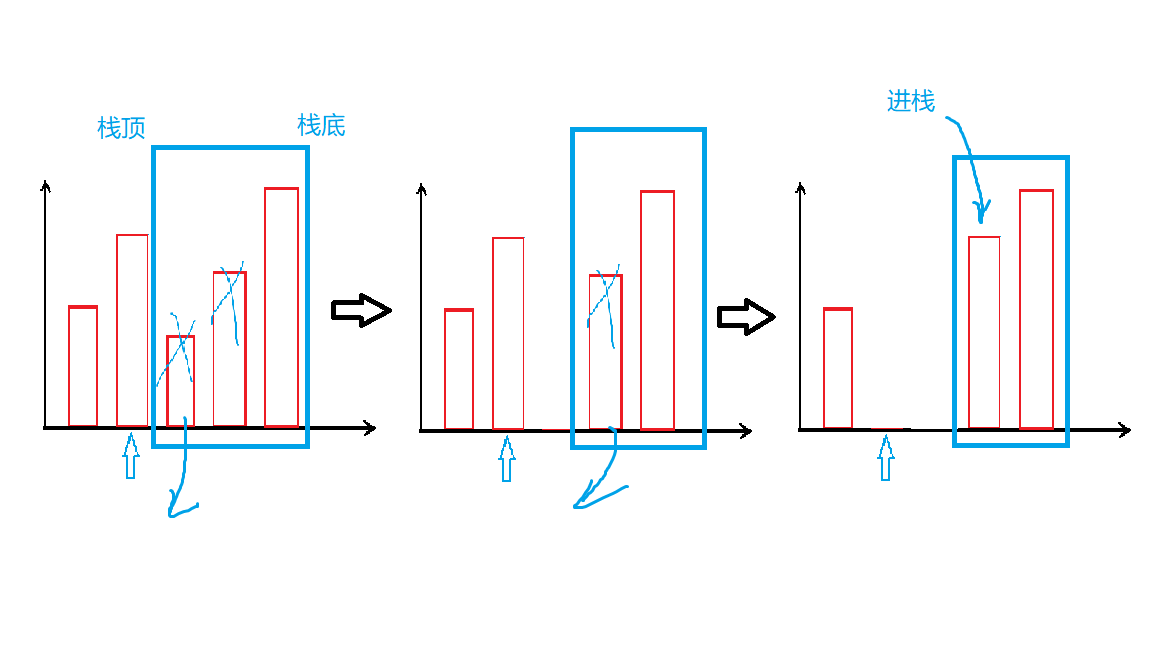
代码:
#include <iostream>
using namespace std;
const int N = 3000010;
long long n, tt, a[N], stk[N], ans[N];
int main() {
cin >> n;
for(int i = 1; i <= n; i++) cin >> a[i];
for(int i = n; i >= 1; i--) {
while(tt > 0 && a[stk[tt]] <= a[i]) tt--;//如果栈不空且
栈顶下标对应的数比当前的数小,就没用了,弹出
ans[i] = stk[tt];//由于这道题要求输出下标并倒序输出,所以将下标作为栈中元素并记录在数组中
stk[++tt] = i;//将当前下标进栈
}
for(int i = 1; i <= n; i++) cout << ans[i] << " ";
return 0;
}
单调队列
和单调栈原理差不多,一般用来解决滑动窗口中的最大最小值问题,可用来优化多重背包。
P1886 滑动窗口 /【模板】单调队列
如果采用暴力做法,对窗口里的数进行遍历,遍历n次,那么时间复杂度为
我们来考虑优化。先考虑最小值,以样例为例,当窗口滑动到如下位置时,

按照这样的方法,把序列中所有的逆序数删完后,整个序列变成了一个单调序列,这里是单调递增。那么求最小值就简单了,其实就是队首的值。求最大值反过来就行了。
代码:
#include <iostream>
using namespace std;
const int N = 1000010;
int hh, tt = -1, q[N], n, k;
int a[N];
int main() {
cin.tie(0);
cin >> n >> k;
for(int i = 1; i <= n; i++) cin >> a[i];
for(int i = 1; i <= n; i++) {
//判断队头是否滑出窗口,队中存下标
if(hh <= tt && i - k + 1 > q[hh]) hh++;
while(hh <= tt && a[q[tt]] >= a[i]) tt--; //若队尾大于当
前的数,则队尾没用,删去
q[++tt] = i; //先将当前的数的下标放入队列再输出,否则可
能a[i]太小将队列清空,输出的就是不明所以的东西了
if(i >= k) cout << a[q[hh]] << " "; //因为窗口的左端点是
从第一个数开始的,所以要特判从第k位开始输出
}
return 0;
}
3.KMP字符串匹配大法
这位更是重量级,第一次学时根本听不懂,太抽象了
P3375 【模板】KMP 字符串匹配
朴素算法的话就是写两层循环,将母串一位一位往后推,一次一次地从字串头开始匹配,若不匹配就 break 掉。但是这样时间复杂度为

怎么优化呢?其实我们发现,按照朴素做法,在某一次匹配失败后字串将向后移一位,但是其实已经匹配了很多位了,不需要再从头开始。
如图所示:
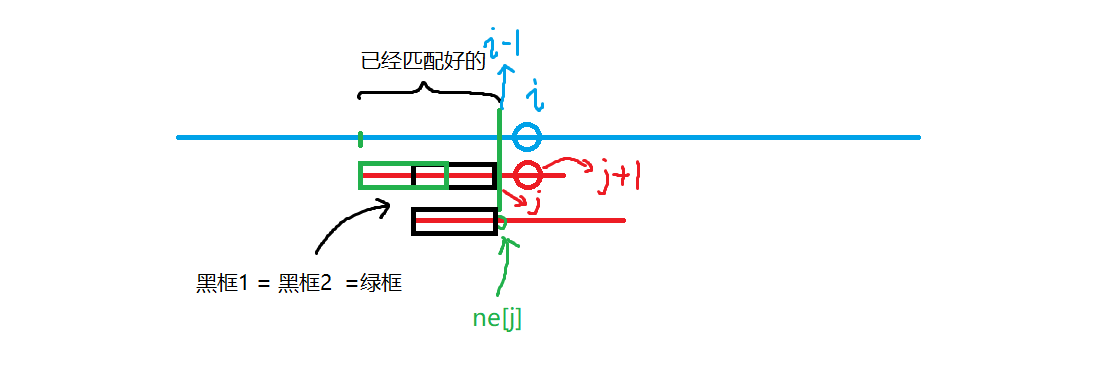
假设母串匹配到第
怎么实现呢?定义一个数组
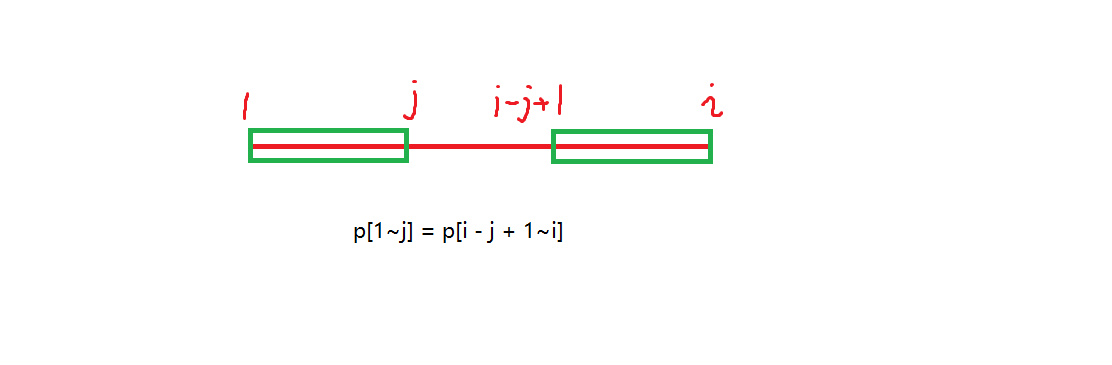
现在的问题就是怎么求出这个数组。其实这是个递推的过程,假设我们求到了
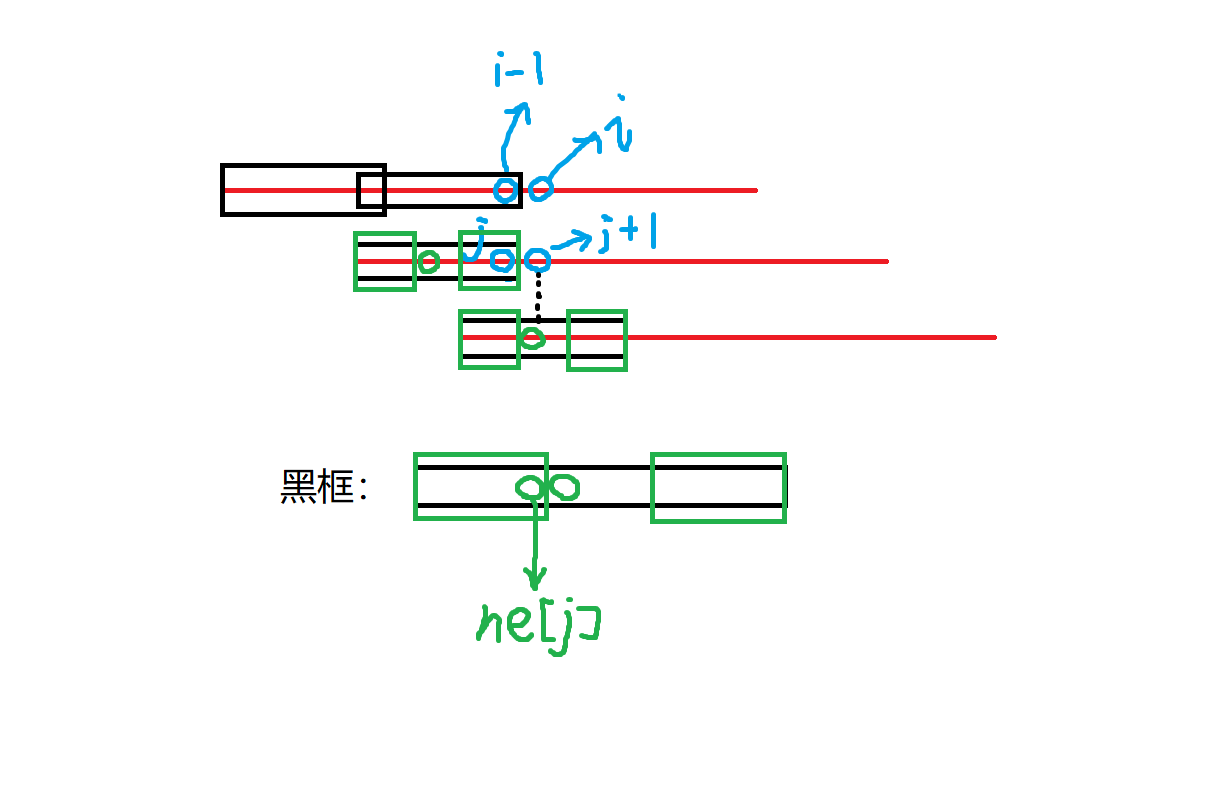
代码:
#include <iostream>
#include <cstring>
using namespace std;
const int N = 1000010;
int lens, lenp, ne[N];
char s[N], p[N];
int main() {
cin.tie(0);
cin >> s + 1 >> p + 1; //下标从1开始
lens = strlen(s + 1), lenp = strlen(p + 1);
//求next数组
for(int i = 2, j = 0; i <= lenp; i++) {
while(j && p[i] != p[j + 1]) j = ne[j]; //若还能退且失配
,则退而求其次
if(p[i] == p[j + 1]) j++; //若匹配了,则前进一步
ne[i] = j; //记录
}
//KMP匹配过程
for(int i = 1, j = 0; i <= lens; i++) {
while(j && s[i] != p[j + 1]) j = ne[j]; //若还能退且失配,则退而求其次
if(s[i] == p[j + 1]) j++; //若匹配了,则前进一步
if(j == lenp) { //匹配成功
cout << i - lenp + 1 << endl;
j = ne[j]; //继续退,寻找其他匹配成功的情况
}
}
for(int i = 1; i <= lenp; i++) {
cout << ne[i] << " ";
}
return 0;
}
4.
如图所示:
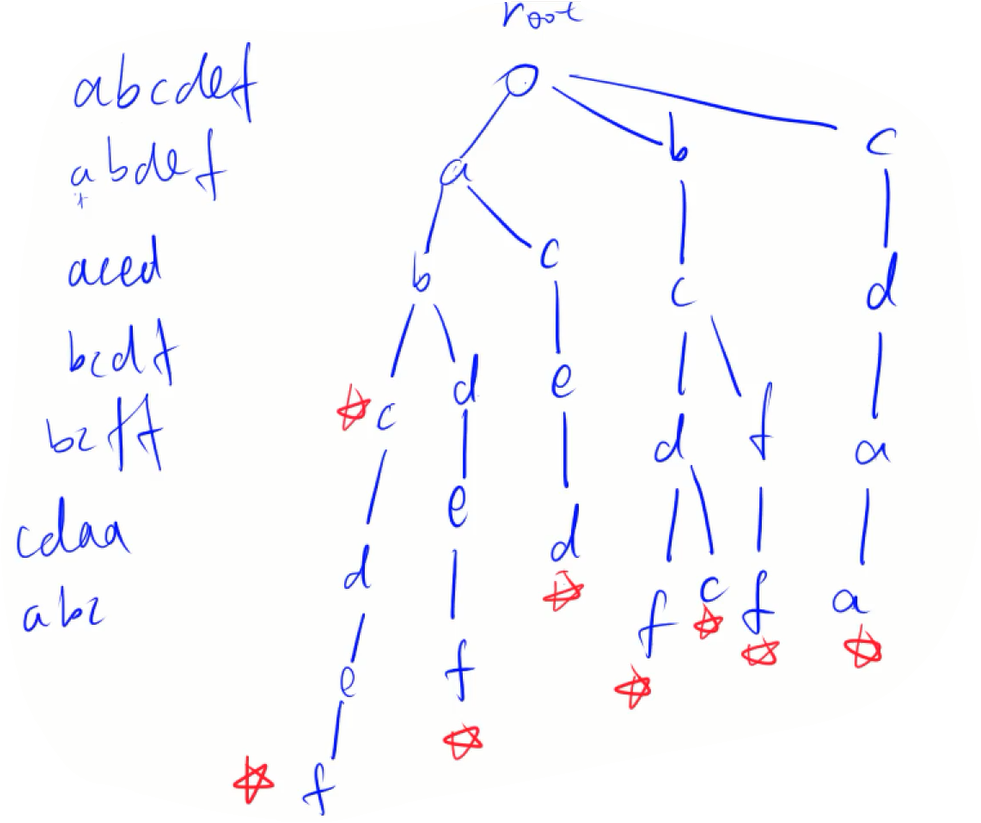
比如插入第一个字符串
再看第二个字符串
再比如我要查找是否存在字符串
假如我要查找字符串
再假如我要查找字符串
问题来了,该怎么实现?
首先我们得先把所有的字符映射成数字,代码如下:
//映射字符
int mapping(char c) { //0~25是小写字母,26~51是大写字母,52~61是数字0~9
if(c >= 'A' && c <= 'Z') {
return c - 'A';
}
else if(c >= 'a' && c <= 'z') {
return c - 'a' + 26;
}
else return c - '0' + 52;
}
然后定义数组
int trie[N][65], cnt[N], idx;
各种简单操作:
//插入一个字符串
void insert(char str[]) {
int p = 0; //从根节点开始
for(int i = 0; str[i]; i++) {
int u = mapping(str[i]); //映射字符
if(!trie[p][u]) trie[p][u] = ++idx; //若无此子节点,添加
p = trie[p][u]; //走过去
}
cnt[p]++; //以该末尾字符结尾的字符串又多了一个
}
//查询某个字符串的出现次数
int query(char str[]) {
int p = 0;
for(int i = 0; str[i]; i++) {
int u = mapping(str[i]);
if(!trie[p][u]) return 0; //如果有一个字符不同就不存在
p = trie[p][u];
}
return cnt[p]; //返回出现次数
}
废话不多说,直接上模板题。
P8306 【模板】字典树
这道题还有点不同,是看作为前缀的出现次数,但其实比较简单,只需要将插入函数改成这样:
void insert(char str[]) {
int p = 0;
for(int i = 0; str[i]; i++) {
int u = mapping(str[i]);
if(!trie[p][u]) trie[p][u] = ++idx;
p = trie[p][u];
cnt[p]++; //移到循环内部,表示有多少个字符串经过它
}
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】