搜索与图论(2)最短路
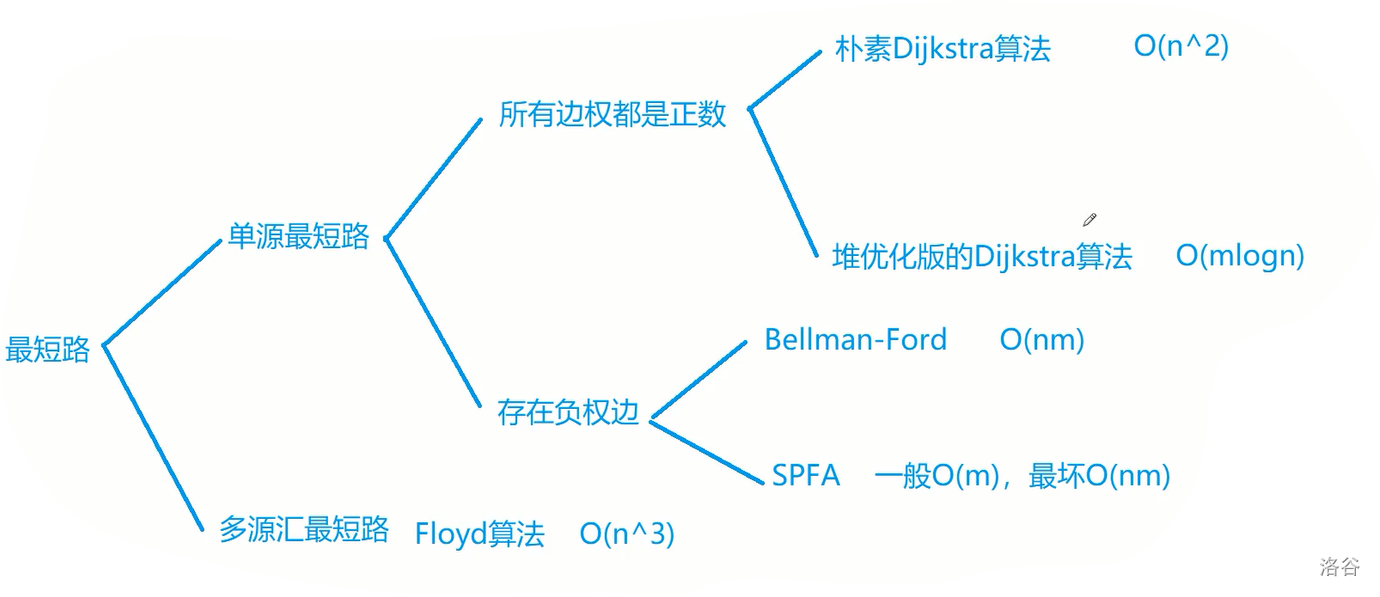
知识结构
图的复杂程度
图的复杂程度分为两种:稀疏图和稠密图。稀疏图是指在一张有
一些新概念
源点又称起点,汇点又称终点,所以单源最短路指的是求一个起点到其它点的最短路,多源汇最短路是求不同起点到其它点的最短路。
以上这么多算法分别是面对不同情况时使用。其中稀疏图用堆优化版的 Dijkstra 算法,稠密图用朴素 Dijkstra 算法,存在负权边时用 SPFA 算法,求不超过
一定要用对应的算法写对应的题!
最短路问题
考察的侧重点为建图,即如何把原问题抽象成为一个最短路问题,所以我们要想清楚如何定义图中的点和边,使得它变成一个最短路问题,然后再套用模板来将它完成。
1.Dijkstra 算法
- 1.朴素版本
首先初始化距离,将

实现代码如下:
void dijkstra() {
memset(dis, 0x3f, sizeof(dis)); //初始化成正无穷
dis[1] = 0; //起点与自己的距离为1
for(int i = 1; i < n; i++) { //已经加入一个点了,那么就只剩n - 1
个点了
int t = -1;
for(int j = 1; j <= n; j++) { //找不属于集合s且在所有除
起点的节点中它到起点的距
离最小的节点
if(!vis[j] && (t == -1 || dis[j] < dis[t])) t = j;
}
vis[t] = true; //标记已经确定最短距离
for(int j = h[t]; j != -1; j = ne[j]) { //遍历与j相连的节点
int k = e[j];
dis[k] = min(dis[k], dis[t] + w[j]); //更新距离
}
}
if(dis[n] == 0x3f3f3f3f) printf("-1"); //若不能到达则输出-1
else printf("%d\n", dis[n]); //否则输出最小距离
}
- 2.堆优化版本
看一下算法的时间复杂度:
for(i:1 ~ n)//n次
{
t <- 没有确定最短路径的节点中距离源点最近的点;//每次遍一遍历dist数组,
n次的复杂度是O(n^2)
state[t] = 1;
更新 dist;//每次遍历一个节点的出边,n次遍历了所有节点的边,复杂度为O(e)
}
算法的主要耗时的步骤是从
在一组数中每次能很快的找到最小值,可以使用堆来进行优化。可以使用库中的小根堆(推荐)或者手写堆。
减少慢步骤的运行时间,就能达到优化整个时间的效果,这和加快化学反应速率多么地相似!
代码如下:
#include <cstring>
#include <iostream>
#include <algorithm>
#include <queue>//堆的头文件
using namespace std;
typedef pair<int, int> PII;//堆里存储距离和节点编号
const int N = 1e6 + 10;
int n, m;//节点数量和边数
int h[N], w[N], e[N], ne[N], idx;//链式前向星存储图
int dist[N];//存储距离
bool st[N];//存储状态
void add(int a, int b, int c) {
e[idx] = b, w[idx] = c, ne[idx] = h[a], h[a] = idx++ ;
}
int dijkstra() {
memset(dist, 0x3f, sizeof dist);//距离初始化为无穷大
dist[1] = 0;
priority_queue<PII, vector<PII>, greater<PII>> heap;//堆
heap.push({0, 1});//插入距离和初始节点编号
while(heap.size()){
PII t = heap.top();//取距离源点最近的点
heap.pop();
int ver = t.second;//ver:节点编号
if(st[ver]) continue;//如果距离已经确定,则跳过该点
st[ver] = true;
for(int i = h[ver]; i != -1; i = ne[i]) {//更新ver所指向的节点距离
int j = e[i];
if(dist[j] > dist[ver] + w[i]) {
dist[j] = dist[ver] + w[i];
heap.push({dist[j], j});//距离变小,则入堆
}
}
}
if(dist[n] == 0x3f3f3f3f) printf("-1");
printf("%d\n", dist[n]);
}
int main() {
scanf("%d%d", &n, &m);
memset(h, -1, sizeof h);
for(int i = 1; i <= m; i++) {
int a, b, c;
scanf("%d%d%d", &a, &b, &c);
add(a, b, c);
}
dijkstra();
return 0;
}
使用堆后,找到
2.Bellman-Ford 算法
以下是主要思路:

代码:
int bellman_ford() {
memset(dist, 0x3f, sizeof dist);
for(int i = 1; i <= k; i++) { //当迭代k次时,可求经过边为k时的最
短路
memcpy(backup, dist, sizeof dist); //备份,因为每次只能
调用之前的dist
for(int j = 1; j <= m; j++) {
int a = edge[j].a, b = edge[j].b, w = edge[j].w;
dist[b] = min(dist[b], backup[a] + w); //松弛操作
}
}
if(dist[n] > 0x3f3f3f3f / 2) return -1;
return dist[n];
}
3.SPFA 算法
SPFA 算法是对 Bellman-Ford 算法的一个优化。
(话说为什么 Dijkstra 优化后叫堆优化 Dijkstra,而 Bellman-Ford 优化后叫 SPFA)
Bellman-Ford 算法会遍历所有的边,但是有很多的边遍历了其实没有什么意义,我们只用遍历那些到源点距离变小的点所连接的边即可,只有当一个点的前驱结点更新了,该节点才会得到更新。因此考虑到这一点,我们将创建一个队列每一次加入距离被更新的结点。这种优化方式有点像广搜。

代码:
int spfa() {
queue <int> q;
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
q.push(1);
vis[1] = true; //标记1已经放入,防止重复放入
while(!q.empty()) {
int t = q.front();
q.pop();
vis[t] = false; //队首已经弹出,将它标记成false
for(int i = h[t]; i != -1; i = ne[i]) { //遍历每条边
int j = e[i];
if(dist[j] > dist[t] + w[i]) { //松弛操作
dist[j] = dist[t] + w[i];
if(!vis[j]) { //如果j未被放入,则放入
q.push(j);
vis[j] = true;
}
}
}
}
return dist[n];
}
如何判断负环?
前一篇文章说过,根据抽屉原理,如果路径上至少存在
代码:
bool spfa() { //cnt用于记录走过的边数
queue <int> q;
for(int i = 1; i <= n; i++) {
q.push(i);
vis[i] = true;
} //由于从每个点出发都可能遇到负环,所以将每个点都放入队列
while(!q.empty()) {
int t = q.front();
q.pop();
vis[t] = false;
for(int i = h[t]; i != -1; i = ne[i]) {
int j = e[i];
if(dist[j] > dist[t] + w[i]) {
dist[j] = dist[t] + w[i];
cnt[j] = cnt[t] + 1; //走过去
if(cnt[j] >= n) return true; //如果边数大于n,则有负环
if(!vis[j]) {
q.push(j);
vis[j] = true;
}
}
}
}
return false; //否则则无
}
4.
基于动态规划。状态表示是三维,
dist[k, i, j] = dist[k - 1, i, k] + dist[k - 1, k, j];
其中第一维可以优化掉,变成
dist[i, j] = min(dist[i, k] + dist[k, j])
就可以看成是看从
代码:
void floyd() {
for(int k = 1; k <= n; k++) {
for(int i = 1; i <= n; i++) {
for(int j = 1; j <= n; j++) {
dist[i][j] = min(dist[i][j], dist[i][k] + dist[k][j]);
//k为中间点,看从i到k再到j和直接从i到j哪个更短
}
}
}
}
学了三天最短路,大脑都快短路了(lll¬ω¬)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!