搜索与图论(1)
目录
1.深度优先搜索(DFS)
2.宽度优先遍历(BFS)
3.树与图的储存
4.树与图的深度优先遍历
5.树与图的宽度优先遍历
6.拓扑排序
1.深度优先搜索(DFS)
深搜,顾名思义,就是优先考虑搜索的深度,尽量往深了搜,就像一个执着的人,一条道走到黑。如果没有路可走了就往回退一步,继续寻找可以走的路,同时还要恢复搜索之前的一切(恢复现场),这就是回溯。
如图所示:
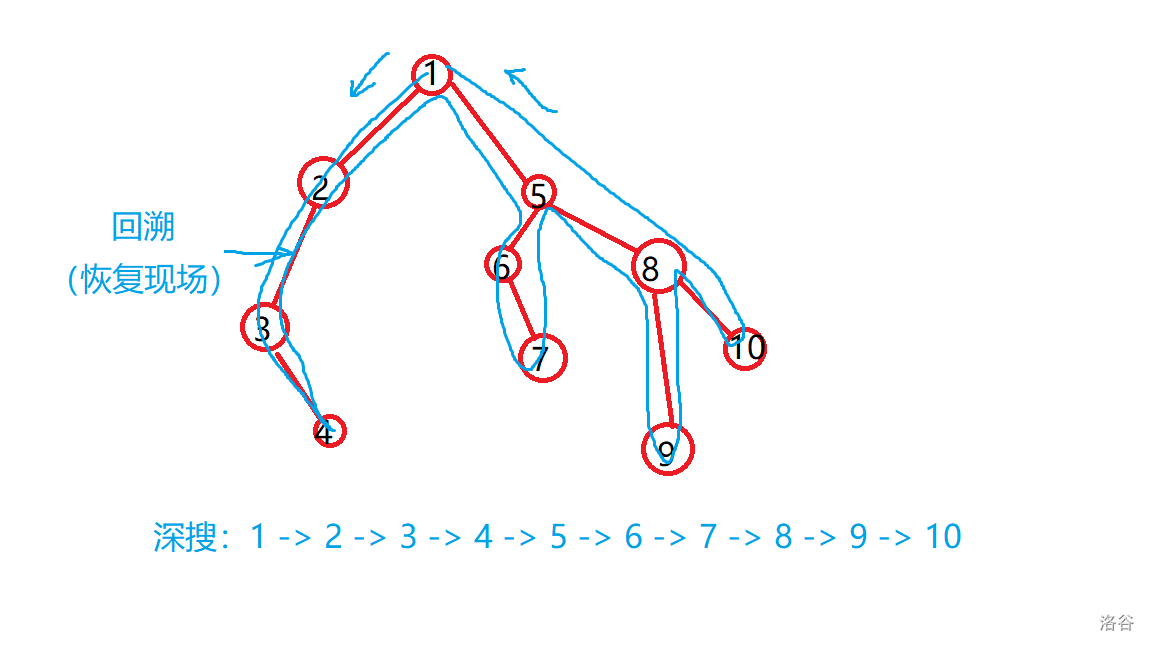
搜索轨迹看起来就像一棵树,虽然图有点丑,但确实有一点像吧。
代码实现:
void dfs(int u) {
if(u == n) { //如果搜到终点
//输出答案
return ;
}
for(int i = 1; i <= n; i++) {
if(!vis[i]) { //如果没有访问过
//记录
vis[i] = true; //标记已经走过
dfs(u + 1); //往深的一层继续搜索
//如果没路了
//撤销记录
vis[i] = 0; //恢复现场
}
}
}
------------
2.宽度优先搜索(BFS)
也叫广度优先搜索,即广搜。它的搜索顺序与深搜不同,它优先考虑的是搜索的宽度,就像一个稳重的人,先搜索下一步所有的可能,再在每种可能的基础上进行扩展,直到搜到答案。
如图所示:
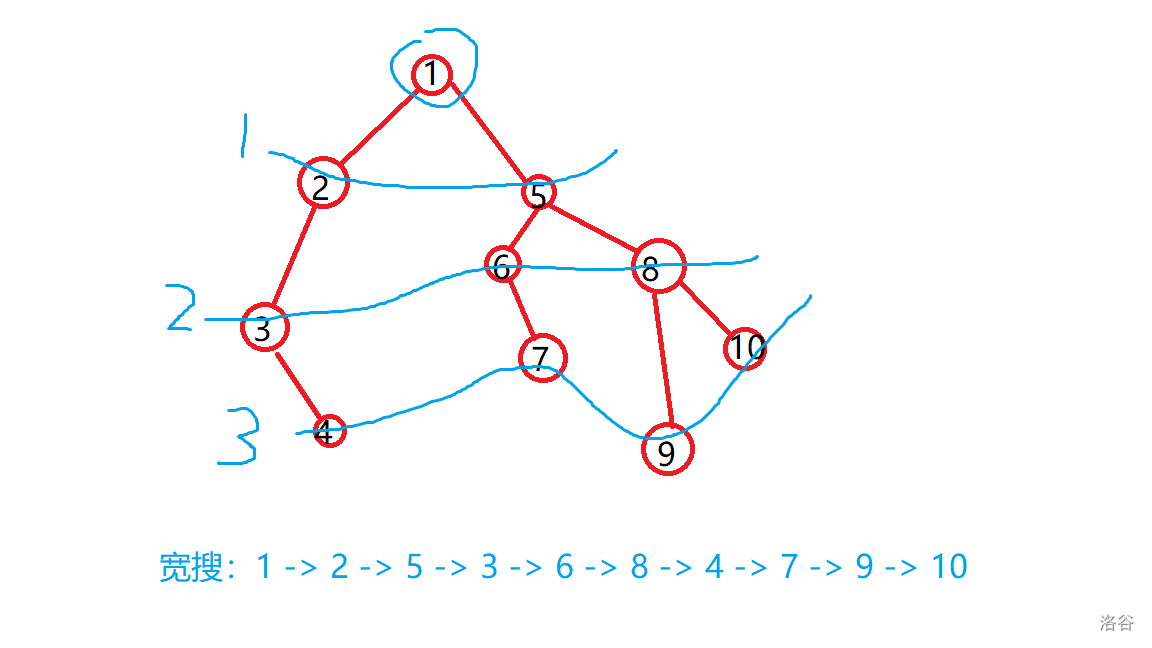
搜索轨迹看起来像水波,逐渐向远处扩散。
代码实现:
void bfs() { //宽搜
//宽搜要用队列哦
q.push(1); //压入起点
while(!q.empty()) { //若队列不空
int t = q.front(); //取出队头
q.pop(); //弹掉
if(……) { //若搜到答案
//输出答案
return ;
}
//扩展队列
}
}
还能再具体一点吗?
宽搜实现过程如图:
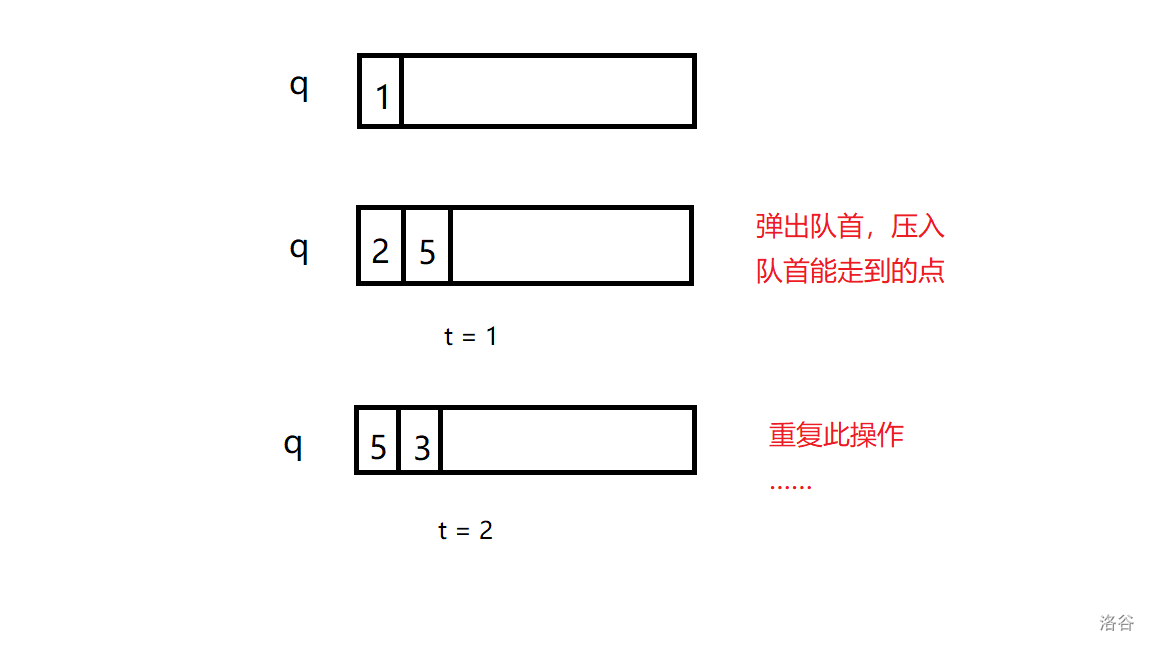
在此总结一下深搜和宽搜的区别:
深搜对应的数据结构是 stack(栈),空间复杂度
宽搜对应的数据结构是 queue(队列),空间复杂度
3.树与图的储存
因为树是一种特殊的图(无环连通图),图分为两种,有向图和无向图,无向图又是一种特殊的有向图,所以这里我们只用考虑有向图的储存方式即可触类旁通。
有向图的存储通常有两种方式,分别为邻接矩阵、邻接表。
邻接矩阵
这是一种使用较少的方法,它的实质是定义一个二维数组用于储存这张图的信息。比如定义
邻接表
它的实质是对于每个节点,都定义了一个单链表,用于存储这个点可以走到哪个点。
如图所示:
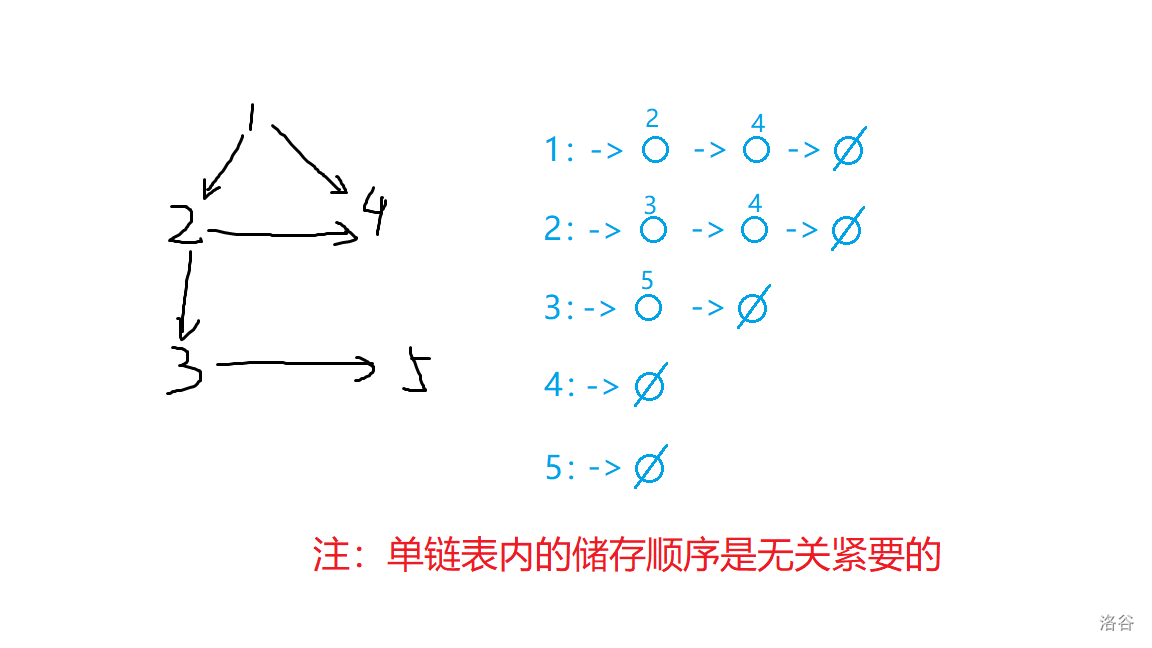
以上两种存储方式的空间复杂度都为
我们将邻接表进行优化,便得到了一个新方式:链式前向星。
与普通邻接表不同,链式前向星是一个链式结构,而普通邻接表是线性结构,无论是时间上还是空间上,链式前向星都完胜普通邻接表。
那我们怎么来实现它呢?代码如下:
const int N = 10010;
int h[N], e[N], ne[N], idx; //h[N]记录每个节点的最后一条出边,e[N]记录每
条边要到达的点,ne[N]记录了从相同节点出发的下一条边在e[N]数组中的储存位置,
idx表示读到了第几条边
void add(int a, int b) { //插入一条由a指向b的边
e[idx] = b, ne[idx] = h[a], h[a] = idx++;
}
这里有更加详细的介绍
4.树与图的深度优先遍历
同上,我们只考虑如何遍历有向图。实现方式和深搜类似。
时间复杂度:
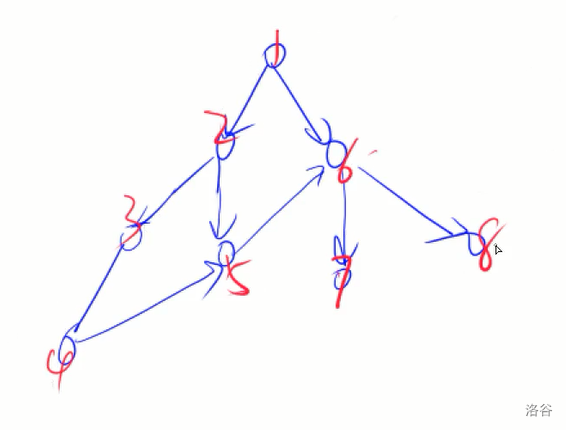
代码实现:
void dfs(int u) { //从节点u开始
vis[u] = true; //标记已被访问过
for(int i = h[u]; i != -1; i = ne[i]) { //遍历此节点的每一条边
int j = e[i];
if(!vis[j]) dfs(j); //若未被访问,则继续深搜
}
}
5.树与图的宽度优先遍历
实现方式和宽搜类似。
时间复杂度:
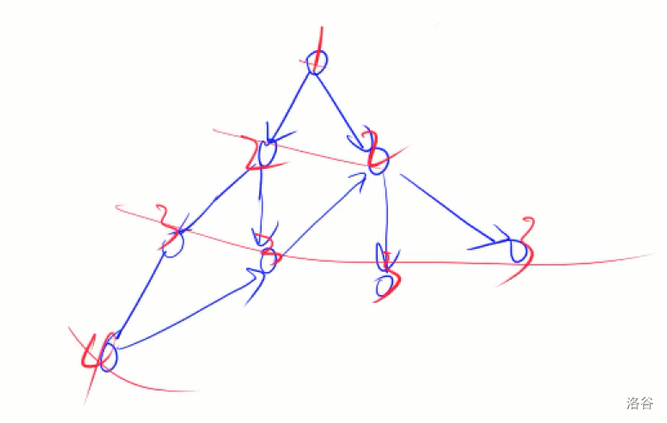
代码实现:
int d[N]; //储存第一个节点到其他节点的距离(最小距离)
void bfs() {
q.push(1);
memset(d, -1, sizeof(d));
d[1] = 0; //第一个点到自己的距离当然为0
while(!q.empty()) {
int t = q.front();
for(int i = h[t]; i != -1; i = ne[i]) {
int j = e[i];
if(d[j] == -1) { //若第一次搜到
d[j] = d[t] + 1; //记录距离
q.push(j); //扩展队列
}
}
}
printf("%d", d[n]); //输出
}
6.拓扑排序
拓扑序列是针对有向图说的,无向图是没有拓扑序列的。它的定义是:如果一个由点组成的序列

为什么说“一个拓扑序列”呢?我们不难发现,对于某些有向无环图,不只有一个拓扑排序,比如:
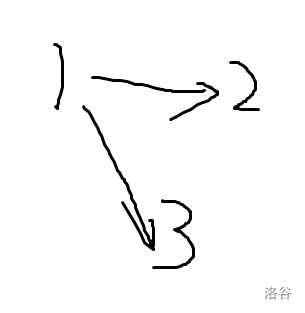
这个图就有两个拓扑序列,分别为
我们如何求一个有向无环图的拓扑序列呢?
其实需要用到上面讲的宽度优先遍历。首先我们思考,什么样的节点可以放在序列的前面呢?显然,所有入度为
你看,所有入度为
代码实现如下:
int h[N], e[N], ne[N], idx;
int n, m, d[N];
int q[N];
void topsort() {
int hh = 0, tt = -1; //手写队列
for(int i = 1; i <= n; i++) { //所有入度为0的点入队
if(!d[i]) q[++tt] = i;
}
while(hh <= tt) {
int t = q[hh++];
for(int i = h[t]; i != -1; i = ne[i]) { //遍历队头节点的
所有出边
int j = e[i];
d[j]--; //删除此边
if(!d[j]) q[++tt] = j; //若B也变成入度为0的点,
则将B放入队列
}
}
for(int i = 0; i < n; i++) {
printf("%d ", q[i]); //输出(这里体现出了手写队列的好处,弹出操作只是将队头指针往后移动,但排好序的序列刚好是从下标0开始的,没有被“弹掉”
}
return ;
}
这时候就有有一个疑问了,这样做真的可以使这个有向无环图的所有节点入队吗?答案是可以的。我们可以浅浅地证明一下。
这里采用反证法来证明(主要是蒟蒻不知道怎么从正面证明)首先,只有入度为
这样一来,我们不仅证明了这个方法的可行性,还得到了一条重要性质:对于所有的有向无环图,至少存在一个入度为


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!