
SQL Server 一些使用小技巧
1、查询的时候把某一个字段的值拼接成字符串
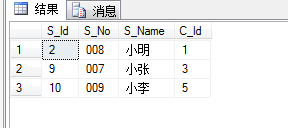
以下是演示数据。
第一种方式:使用自定义变量
DECLARE @Names NVARCHAR(128) SET @Names='' -- 需要先赋值为空字符串,不然结果会是 null SELECT @Names=@Names+S_Name+',' -- S_Name 类型为字符串类型,如果不能隐示转换,就需要强制转换 FROM Student SELECT @Names
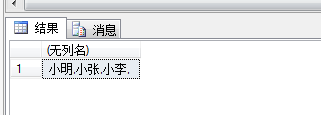
这种方法有一个好处就是,拼接出来的字符串可以赋值给变量或直接插入表中指定字段,可以适用于存储过程之类的。
第二种方式:转换为 XML 格式
SELECT t.S_Name + ',' FROM ( SELECT S_Name FROM Student ) t FOR XML PATH('')
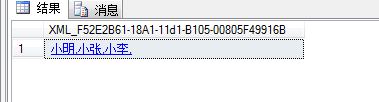
使用这种方式有一个缺点就是,不能直接赋值给变量或插入表,适用于查看时使用。
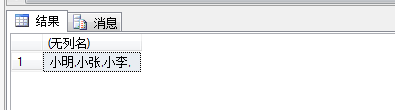
如果想要使之能够赋值给变量或插入表中,那就需要转换一下。如下:
DECLARE @Names NVARCHAR(128) SET @Names='' SELECT @Names= ( SELECT t.S_Name + ',' FROM ( SELECT S_Name FROM Student ) t FOR XML PATH(''),TYPE ).value('.','NVARCHAR(128)') SELECT @Names
2、查询一个字段同时满足多个条件的方法
举个栗子:比如现在有一些订单,而每一个订单有多个产品,现在我要查出同时具有某几个产品的订单。
再拿学生和课程来举例,一个学生可以选择多门课程,而每一门课程也可以同时被多个学生所选择,那么我现在要查出选择了某几门课程的学生。
下面是演示数据。
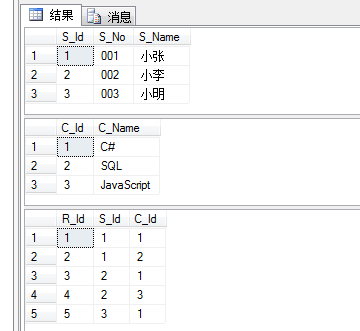
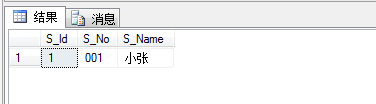
现在我要查出同时选择了 C# 和 SQL 课程的学生信息。如下:
SELECT s.S_Id,s.S_No,s.S_Name FROM Student s INNER JOIN Student_Course_Relation r ON s.S_Id=r.S_Id INNER JOIN Course c ON r.C_Id=c.C_Id WHERE c.C_Name='C#' OR c.C_Name='SQL' GROUP BY s.S_Id,s.S_No,s.S_Name HAVING COUNT(1) >= '2' -- 这个数字是根据 where 条件来定
3、SQL Server 实现多行转列
之前也写过一篇博客,SQL Server 使用 Pivot 和 UnPivot 实现行列转换,但是之前都是相对于“单列”的转换,于是最近碰到一个需要两列的问题。最后在网上找了一些相关资料,得出了下面的解决方法。下面先建立一个表,插入一些模拟的数据。如下:
create table OrderDemo ( ID int not null identity(1,1) primary key, CustomerCode nvarchar(16) not null, OrderCount int not null default(0), TotalAmount decimal(13,3) not null default(0), YearDate nvarchar(8) null, MonthDate nvarchar(8) null ) insert into OrderDemo ( CustomerCode, OrderCount, TotalAmount, YearDate, MonthDate ) select 'A001','23','28.650','2017','1' union all select 'A001','67','123.123','2017','2' union all select 'A002','12','28.320','2017','1' union all select 'A002','37','51.221','2017','2' union all select 'A003','89','452.200','2017','1' union all select 'A003','134','523.210','2017','2' union all select 'A004','78','230.220','2017','1' union all select 'A004','95','180.567','2017','2' union all select 'A005','128','230.789','2017','1' union all select 'A005','256','340.450','2017','2' select * from OrderDemo
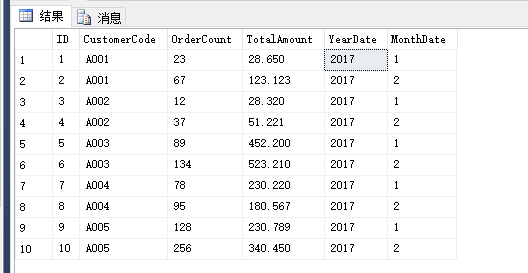
以上的数据是模拟的按客户、订单年份和订单月份统计的订单数量和金额,由于年月的时间段非固定的,所以这里使用的是动态sql,下面直接上代码:
declare @strSql nvarchar(1024) declare @strWhere nvarchar(1024) set @strWhere='' -- 用作转换之后的列头 select @strWhere = @strWhere+TitleCount+','+TitleAmount+',' from ( select distinct '['+YearDate+'年'+MonthDate+'月'+'数量'+']' TitleCount,'['+YearDate+'年'+MonthDate+'月'+'金额'+']' TitleAmount from OrderDemo ) t -- 去掉最后一个逗号 if(CHARINDEX(',',REVERSE(@strWhere))=1) begin set @strWhere=SUBSTRING(@strWhere,1,len(@strWhere)-1) end set @strSql='select * from ( select CustomerCode,ComDate+ColumnName ComDate,CountAndAmount from ( select CustomerCode,YearDate+''年''+MonthDate+''月'' ComDate, cast(OrderCount as nvarchar) ''数量'', cast(TotalAmount as nvarchar) ''金额'' from OrderDemo ) a UNPIVOT ( CountAndAmount for ColumnName IN ([数量],[金额]) ) b ) c pivot ( max(CountAndAmount) for ComDate in ('+ @strWhere +') ) d ' exec (@strSql)
结果如下:
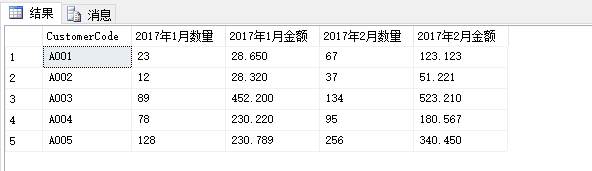
既然两列可以这么实现,那么如果在多一列呢,或者多很多列。这里我稍稍修改了一下,多增加了一列进行测试(多列同理),修改之后的代码如下:
create table OrderDemo ( ID int not null identity(1,1) primary key, CustomerCode nvarchar(16) not null, OrderCount int not null default(0), ProductCount int not null default(0), TotalAmount decimal(13,3) not null default(0), YearDate nvarchar(8) null, MonthDate nvarchar(8) null ) insert into OrderDemo ( CustomerCode, OrderCount, ProductCount, TotalAmount, YearDate, MonthDate ) select 'A001','23','35','28.650','2017','1' union all select 'A001','67','75','123.123','2017','2' union all select 'A002','12','18','28.320','2017','1' union all select 'A002','37','42','51.221','2017','2' union all select 'A003','89','98','452.200','2017','1' union all select 'A003','134','150','523.210','2017','2' union all select 'A004','78','99','230.220','2017','1' union all select 'A004','95','102','180.567','2017','2' union all select 'A005','128','138','230.789','2017','1' union all select 'A005','256','280','340.450','2017','2' select * from OrderDemo declare @strSql nvarchar(1024) declare @strWhere nvarchar(1024) set @strWhere='' -- 用作转换之后的列头 select @strWhere = @strWhere+TitleCount+','+TitleAmount+','+TitleProduct+',' from ( select distinct '['+YearDate+'年'+MonthDate+'月'+'数量'+']' TitleCount, '['+YearDate+'年'+MonthDate+'月'+'金额'+']' TitleAmount, '['+YearDate+'年'+MonthDate+'月'+'产品数量'+']' TitleProduct from OrderDemo ) t -- 去掉最后一个逗号 if(CHARINDEX(',',REVERSE(@strWhere))=1) begin set @strWhere=SUBSTRING(@strWhere,1,len(@strWhere)-1) end set @strSql='select * from ( select CustomerCode,ComDate+ColumnName ComDate,CountAndAmount from ( select CustomerCode,YearDate+''年''+MonthDate+''月'' ComDate, cast(OrderCount as nvarchar) ''数量'', cast(TotalAmount as nvarchar) ''金额'', cast(ProductCount as nvarchar) ''产品数量'' from OrderDemo ) a UNPIVOT ( CountAndAmount for ColumnName IN ([数量],[金额],[产品数量]) ) b ) c pivot ( max(CountAndAmount) for ComDate in ('+ @strWhere +') ) d ' exec (@strSql)
PS:需要注意的是当需要转换的列的数据类型不同时需要转换为同一种类型,比如这里的 “数量、金额、产品数量”。
4、在子查询中使用 Order By
比如,我现在有这样一些数据。如下:
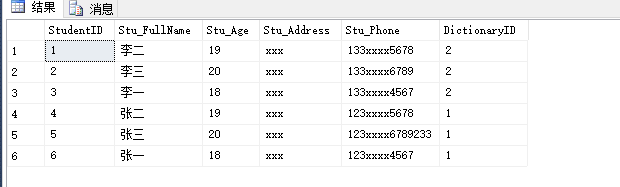
我现在想要使用子查询按字段 “Stu_Age” 排序,那么就有了如下代码:
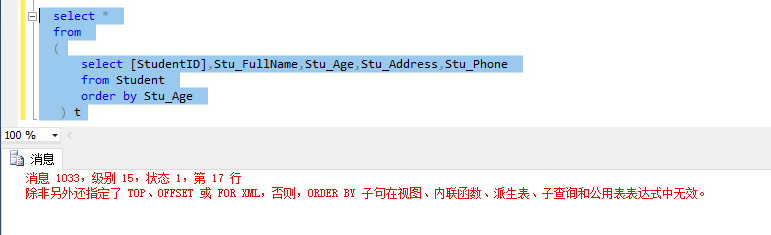
可以看见这样是有错误的,那么下面有两种解决办法。
第一种: row_number() over() 排名开窗函数
select * from ( select [StudentID],Stu_FullName,Stu_Age,Stu_Address,Stu_Phone, ROW_NUMBER() over(order by Stu_Age) RowNum from Student ) t
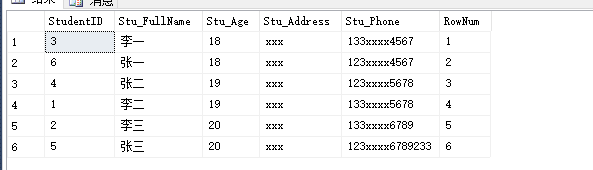
第二种:TOP 100 PERCENT,英语比较好的朋友就知道 percent 就是百分比的意思,结果显而易见。top 100 percent 就表示百分之百,即全部的数据。
select * from ( select top 100 percent [StudentID],Stu_FullName,Stu_Age,Stu_Address,Stu_Phone from Student order by Stu_Age ) t
其实我个人的话还是喜欢第一种方式,第二种也是偶尔看到的。
5、删除所有字段都相同的重复的数据
首先创建一个临时表并插入一些数据,用于模拟该场景。
create table #temp ( ID int not null, Name varchar(20) null ) insert into #temp(ID,Name) values('1','测试'); insert into #temp(ID,Name) values('1','测试'); insert into #temp(ID,Name) values('2','测试'); select * from #temp
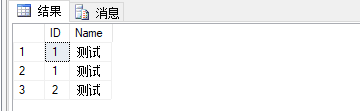
类似于上面这种数据,第一条和第二条数据明显属于完成重复,故需要删除其中一条。
刚开始第一时间想到的方式是,把两条数据全部删除,然后再插入一条。
后来又想到了下面这种方式,个人觉得还不错。
with tes as ( select ID,Name,row_number() over(partition by ID,Name order by ID) RowNum from #temp ) delete from tes where RowNum > 1 select * from #temp
到此结束,最后再删除临时表。
drop table #temp

 浙公网安备 33010602011771号
浙公网安备 33010602011771号