[机器学习]-[数据预处理]-中心化 缩放 KNN(一)
据预处理是总称,涵盖了数据分析师使用它将数据转处理成想要的数据的一系列操作。例如,对某个网站进行分析的时候,可能会去掉 html 标签,空格,缩进以及提取相关关键字。分析空间数据的时候,一般会把带单位(米、千米)的数据转换为“单元性数据”,这样,在算法的时候,就不需要考虑具体的单位。数据预处理不是凭空想象出来的。换句话说,预处理是达到某种目的的手段,并且没有硬性规则,一般会跟根据个人经验会形成一套预处理的模型,预处理一般是整个结果流程中的一个环节,并且预处理的结果好坏需要放到到整个流程中再进行评估。
本次,只使用缩放数值数据来说明预处理的重要性,数值数据:值包含数字,缩放:使用基本的运算来改变数据的范围。最后,将会使用真实的数据来演示缩放预处理提升了结果。
首先,简单说一下机器学习和 KNN(k-Nearest Neighblors)的分类问题,分类问题是他们里面最简单的算法。为了体现缩放数据的重要性,还会介绍模型评估方式和训练集、测试集的概念。这些概念和操作都会在分类红酒质量的时演示。演示的时候会看到预处理前后对结果的影响。
机器学习分类问题简介
分类和标记问题是一个们古老的艺术。比如,亚里士多德构建的生物分类系统。现在,分类一般都是作为机器任务任务的一个通用框架,特别是监督学习。监督学习的基本概念也不复杂,这样的数据中包含预测参数和预测目标结果,监督学习的目标是构建善于通过给出的预测参参数预测目标结果的模型。如果目标结果包含分类信息(如,‘good’,'bad'),这就是所说分类学习任务。如果目标结果是不断变化的,这就是一个回归任务。
介绍一个有用的数据集:心脏病数据集,其中有 75 个预测参数,如,‘age’,‘sex’以及目标结果,心脏病患病概率范围是0(无病)-4。对这个数据集的大部分分析集中在预测是否出现心脏病。这就是一个分类任务。如果是预测0-4的实际值,那么,就是回归问题。以后再讨论回归问题。这次主要讨论分类任务重最简单的算法,KNN。
机器学习的 KNN 分类
假设已经有一些标记好的数据,例如,包含红酒特征的数据,预测参数:alcohol content, density, amount of citric acid, pH,目标结果:Quality(good,bad)。然后,使用特征的新数据,没有标记结果,分类任务就是去预测结果 Quality。如果所有的预测参数都是数值,我们就可以想象一个 n 为空间,每行/红酒作为空间中的一个点。KNN 是概念和计算都很简单的分类方法,我们计算这些没有标记的数据行,在 n 维空间中,最近的 K 个已经标记过的邻居。然后,根据这 K 个邻居的标签,good 或 bad,再将命中率最高(占比最高)的标签值给新的预测数据(例如,如果 K=10,其中 7 个 good,3 个 bad,结果就是 good)。注意,这里没有 fit 参数。
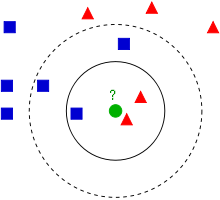
图说 K 邻近
下面是 KNN 的一个 2D 图。思考一下,中间绿色问好的点应该如何分类。如果 K = 5,分类就是蓝色,,如果 k = 10 ,结果又如何呢?

Scikit Learn KNN
我们接下来看一下 KNN 的例子。我们将红酒质量数据集加载到 pandas 的 DataFrame 中,然后通过直方图看下数据基本信息

我们看下这两个预测变量,free sulfur dioxide 的范围 1-72,volatile acidity 的范围是 0.12-1.58。简单的说就是,前一个的的范围和数量级都比后一个大很多。像 KNN 这样的算法,关心的是两个数据点之间的距离,因此,算法可能会将关注点直接放在范围更范围的变量上,这样就会对范围小的变量不公平,像 free sulfur dioxide 可能还会有噪点,这样的数据必然会导致结果准确度有所降低。这就是为什么要缩放我们即将使用的数据。
现在目标结果就是红酒的‘Quality’率,它的范围是 3 到 8。简单起见,将这个范围转换为二分类,大于 5 -> good,小于等于 5 -> bad。下面用直方图说明一下二分类前后目标结果的变化:

接下来我们就准备执行 KNN。我们本次的目的是比较我们的模型在有无缩放处理的情况下的结果优劣,既然要区分结果的优劣我们就需要一个评价标准。
如何评价 KNN 结果
有很多对分类的评价方式/指标,最终重要的是,要认识到方式/指标的选择是一个很有深度的领域,并且需要具体问题具体分析。对于平衡类(目标结果,要么是是,要么是否)数据集,通常将准确性作为评价标准。事实上,在 scikit learn 中 KNN 和逻辑回归默认评分方法就是精度。那么,什么是精度呢?它就是正确预测的数量除以预测的总数:
Accuracy = 正确预测数量/预测总数
KNN 的使用和训练测试的分割
我们就使用上面介绍的江都作为衡量的标准,如果我们把先有的数据都作为训练模型用,我们应该用什么数据集来作为计算精度的数据呢?我们需要一个能很好推广到新数据的模型。也就是说,如果我们在数据集 A 上训练模型,也使用数据集 A 计算精度,那么得出的结果远远好于实际结果。这就是我们常说的过拟合。为了解决这个问题,通常会选取数据集中的一部分作为训练集,然后,在训练集上训练模型,再使用剩下的数据集进行评估。我们也是要这么做的。一般的经验规则是使用大约 80% 的数据用于训练,剩下 20% 的数据用于测试。现在我们就可以分析红酒质量数据了:

现在我构建 KNN 模型,对测试集进行预测,为了评估模型,我们需要对比预测值和真实值:

在 scikit learn 中精度是 KNN 的默认评分方法,精度的结果是 61%,这个结果并不好,但对于没有任何预处理的结果来说,也并不是太坏。
预告 [数据预处理]-中心化 缩放 KNN(二)
使用其他的评估方法(reacll,f1)重新评估结果
使用预处理将精度结果再提高 10% 左右
完整的代码
最后谢谢 @K战神 反馈关于图裂的问题,现已经编辑好

 浙公网安备 33010602011771号
浙公网安备 33010602011771号