[数据分析工具] Pandas 不可不知的功能(一)
- 如果你在使用 Pandas(Python Data Analysis Library) 的话,下面介绍的对你一定会有帮助的。
首先我们先介绍一些简单的概念
-
DataFrame:行列数据,类似 Excel 的 sheet,或关系型数据库的表
-
series:单列数据
-
axis:0:行,1:列
-
shape:DataFrame的行列数,(行数,列数)
1. 加载 CSV
Read_csv 方法有很多参数,有效的利用这些参数可以减轻数据预处理的工作。谁都不愿意做数据清洗,那么我们就在加载数据的时候做一些简单的数据处理
-
直接加载
-
- 无参数加载

-
-
选择特定列加载
-

-
-
时间转换加载
-

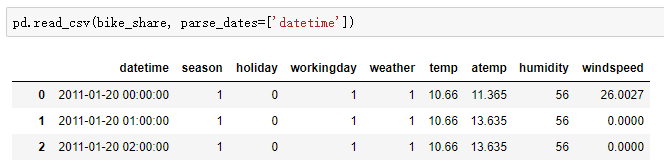
-
分批加载
有时我们可能需要加载的 csv 太大,可能会导致内存爆掉,这时候,我们就需要分批加载数据进行分析、处理

2. 浏览 DataFrame 数据
-
df.head(n):浏览数据的前 n 行,默认 5 行
-
df.tail(n):浏览数据的末尾 n 行,默认 5 行
-
df.sample(n):随机浏览 n 行数据,默认 5 行
-
df.shape:tuple 类型的数据行列数,(行数,列数)
-
df.describe():计算评估数据的趋势
-
df.info():内存和数据类型
3. 在 DataFrame 中增加列
在 DataFrame 中添加新列的操作很简单,下面介绍几种方式
-
简单方式
直接增加新列并赋值
df['new_column'] = 1
-
计算方式
df['temp_diff'] = df['atemp'] - df['temp']
-
条件方式
我们仅仅根据风速,简单判断一下人体舒适度,体感比较舒服的温度是 0.3 米/秒

-
循环方式
我们将 season 转换为具体季节的名称

4. 选择指定单元格
类似于 Excel 单元格的选择,Pandas 提供了这样的功能,操作很简单,但是我本人理解起来确实没有操作看上去那么简单。Pandas 提供了三个方法做类似的操作,loc,iloc,ix,ix 官方已经不建议使用,所以我们下面介绍 loc 和 iloc
-
loc 根据标签选取loc
df.loc[行索引开始位置:行索引结束位置,[列名数组]]
-
iloc 根据索引选取
df.iloc[行索引开始位置:行索引结束位置,列索开始位置:列索引结束位置]
-
选取行数据
-
df.loc[[行索引数组]],df.iloc[[行索引数组]]

注意:
-
索引开始位置:闭区间
-
索引结束位置:开区间
-
loc 和 iloc 选取整列数据的时候,看上去与 df[列名数组] 的方式一致,但是其实前者返回的仍然是 DataFrame,后者返回的是 Series

我的博客即将搬运同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan

 浙公网安备 33010602011771号
浙公网安备 33010602011771号