
docker集群——初识Swarm
为Docker构建原生的集群管理工具的计划早在2014年初就开始了,当时作为一个通信协议项目,称为Beam。之后,它被实现为一种后台程序,使用Docker API来控制异构化的分布式系统。项目重新命名为libswarm,Swarmd是其后台程序。项目保持了之前的理念,允许任何Docker客户端连接到Docker Engine池里。该项目的第三代被重新进行设计,使用相同的Docker Remote API集,并且在2014年11月份重命名为“Swarm”。基本上,Swarm最重要的部分就是其远程API;维护人员通过努力工作,让这些API和Docker Engine的所有版本100%兼容。我们称Swarm第一代为“Swarm v1”。
2016年2月份,核心团队发现中央服务的扩展被限制之后,Swarm在内部被再次重新设计为swarm.v2。这次,使用了去中心化的集群设计。2016年6月份,发布了SwarmKit,可以作为任意规模的分布式服务的编排工具包。在DockerCon 2016大会上,Docker宣布SwarmKit合并入Docker Engine。这一版本的Swarm称为“Swarm v2”或者“Swarm Mode”。
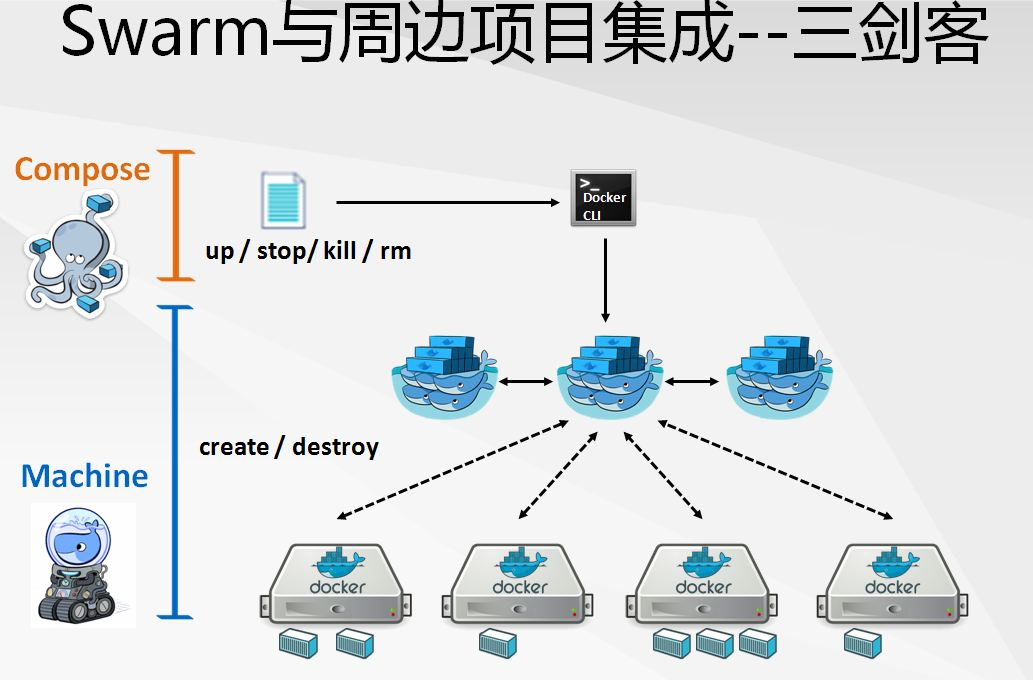
之后我们会一步步体会到,三剑客(Docker Swarm、Docker Machine和Docker Compose)一起使用时表现最佳,它们之间无缝集成在一起,几乎已经无法将某一个当成单独的部分。
- 使用Docker Machine,用户可以预配机器,可以是虚拟机器也可以是物理机器,并可以在若干云平台以及纯物理机器上运行docker容器。
- 使用Docker Compose,用户可以快速定义Dockerfile,通过简单但是强大的YAML语法描述行为,并且只需要将这些文件“组合”起来就可以启动应用程序。
集群工具和容器管理
集群工具是一种软件, 允许运维人员和单个终端沟通,其可以向一系列资源发送命令前编排这些资源。取代在集群上手动分发工作负载(容器)的方式,集群工具用来自动化这些任务以及其他很多任务。集群工具用来自动化这些任务以及其他很多任务。集群工具决定在哪里启动job(容器),如何存储job,什么时候最终重启job等。运维人员仅仅需要配置一些行为,据顶集群的拓扑和规模、调优设置,并且启用或者停用高级特性。Docker Swarm就是这样一种容器的集群工具。
除了集群工具,我们还可以选择容器管理器平台。它们不提供容器托管,但是它们和一个或者多个已有系统交互;这样类型的软件通常都是提供了很好的web接口、监控工具,以及其他可视化或者高层级功能。Rancher和Tutum就是这样的容器管理平台。
Docker Swarm的基础和架构
Docker自身对Swarm的描述如下:
Docker Swarm是Docker的原生集群。它将Docker宿主机池转变成单个虚拟的Docker宿主机。
Swarm是一种工具,让用户以为自己管理的是单个巨大的Docker宿主机,而这个宿主机是由很多Docker宿主机组成的。这些主机看上去是一体的,并且使用一个命令行入口点。Swarm让用户在这些主机上编排并且操作一定数量的容器,使用常规的Docker工具、Docker原生工具或者python-docker客户端,甚至可以选择直接curl到Docker Remote API上。
为什么使用Swarm
使用容器集群解决方案有很多原因。随着应用程序的壮大成熟,我们会遇到很多全新的需求,比如可扩展性、可管理性以及高可用性。市场上有很多可用的工具,使用Docker Swarm可以带来如下优势:
- 原生集群:Swarm是Docker原生的,由Docker团队和社区开发。不需要任何额外的需求,Swarm就可以和Machine、Compose以及生态系统里的其他工具集成。
- 生产环境可用:Swarm v1在2015年11月份成熟,并且可以在生产环境里使用。研发团队已经证明Swarm能够扩展到控制1000个节点的Engine。Swarm v2因为使用了去中心化的发现机制,允许构建数千个节点的集群。
- 开箱即用:Swarm不要求用户重新构建自己的应用程序来适配其他的编排工具。用户可以使用自己的Docker镜像和配置,不需要任何改动,就可以实现大规模部署。
- 易于搭建和使用:Swarm很容易操作。仅仅通过在Machine命令里添加一些参数,或者使用Docker1.12版本后的Docker命令,就可以实现高效部署。将发现服务集成到Swarm Mode里,使其可以快速安装——不需要搭建外部的Consul、Etcd或者Zookeeper集群。
- 活跃的社区:Swarm是一个有活力的项目,有非常积极的社区支撑,开发很快速。
- Hub上可用:用户不需要安装Swarm,它是一个Docker镜像(Swarm v1),因此用户仅仅需要从Hub里拉去这个镜像就可以运行,或者它已经集成进Docker Engine。Swarm Mode已经集成进Docker1.12+版本了。
宠物模型 VS 牛群模型
在创建并且利用基础架构时有两种对立的方案:宠物模型 VS 牛群模型
- 宠物模型:管理员部署服务器或者虚拟机,并且对其持续进行维护。登录机器或容器,安装软件,完成配置,并且确保一切运行正常。因此,这些机器或者容器是管理员的宠物。
- 牛群模型:管理员把基础架构当成牛群模型时,他们并不关心基础架构某个组件的命运。管理员不会登录到任何单元里,也不会做手动处理。相反,他们使用批量方案,借助自动化工具完成部署、配置以及管理。如果某个服务器或者容器死机了,它会被自动复活,或者生成另一个服务器或者容器来替代有问题的组件。因此,在这种场景下,运维人员管理的是牛群模型。
Swarm特性
Swarm核心特性如下:
- Swarm v1支持1.6.0版本或更新版本的Docker Engine。从1.12版本开始,Swarm v2内嵌到了Docker Engine里。
- Swarm每个版本的API都和同版本的Docker API兼容。API可以向后兼容一个版本。
- 在Swarm v1里,为多个Swarm主节点的实现,选主机制使用的是主库(仅仅在使用发现服务,如Etcd、Consul或者Zookeeper部署Swarm时才支持)。
- 在Swarm v2里,使用去中心化的机制来构建选主机制。Swarm v2不再需要特定的发现服务,因为他集成了Etcd,这是Raft公式算法的一种实现。
- 在Swarm v1的术语里,主Swarm master节点被称为primary(主节点),其他master节点被称为replica(副本)。在Swarm v2里,有Master和Worker节点的概念。集群使用Raft自动管理主节点。
- 基础和高级调度选项。schedule(调度器)是一种决定容器物理上放置于哪台主机的算法。Swarm使用一系列内置的调度器。
- Constraint(约束条件)和affinity(共同关系)辅助运维人员做出调度决策。比如,某个用户想要让数据库容器物理上接近,就可以通知调度器去这么做。约束条件和共同关系使用Docker Swarm label(标签)。
- 在Swarm v2里,使用内建DNS Round-Robin实现集群内的负载均衡,也支持外部负载均衡,通过路由网络机制,由IPVS实现。
- 高可用和故障恢复机制意味着用户可以创建超过一个master的Swarm。因此,如果某个master服务宕机了,还有其他master可以继续控制。当构建至少3个节点的集群时,默认可用Swarm v2。所有节点都可以作为master节点。另外,Swarm v2包括健康指标信息。
其他开源编排工具的不同之处:
可以参考:巅峰对决之Swarm、Kubernetes、Mesos
Swarm v1架构
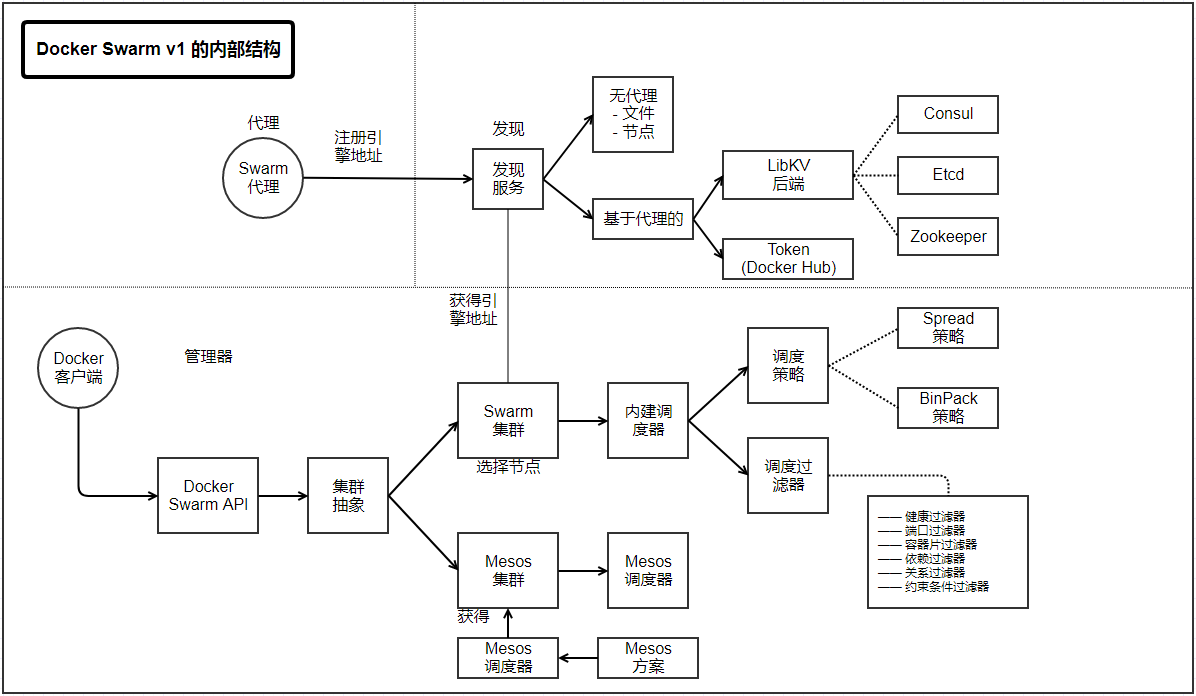
先从管理器部分开始介绍,图片的左侧有一个标为Docker Swarm API 的长方形。Swarm暴露出一系列和Docker类似的远程API,用户可以使用任意Docker客户端连接到Swarm上。但是,Swarm API和标准的Docker远程API略有不同,因为Swarm API还包含集群相关的信息。比如,在Docker Engine上运行docker info可以得到单个Engine的信息,但是如果在Swarm集群上调用docker info,则会得到集群里的节点数量以及每个节点的信息和健康状况。
Docker Swarm API 旁边的长方形是集群抽象。这是一个抽象层,允许不同类型的集群实现为Swarm的后端,并且共享同一组Docker远程API。目前有两种集群后端实现:内建Swarm集群实现和Mesos集群实现。Swarm集群和内建调度器的长方形表示内建的Swarm集群实现,而标识为Mesos集群的长方形则表示Mesos的集群实现。
Swarm后端的内建调度器包含一些调度策略。两种策略分别是Spread和BinPack,如果对Swarm策略比较熟悉,就会注意到这里缺失了Random策略。Random策略没有包含在这里是因为其仅作为测试用途。
和调度策略并排,Swarm还是用了一系列调度过滤器,过滤掉不满足条件的节点。这里有六种类型的过滤器:Health、Port、Container Slots、Dependency、Affinity和Constraint。当调度新建的容器时,它们就以这个顺序应用到过滤器上。
在代理部分,Swarm代理尝试将其Engine的地址注册到发现服务里。
最后,中间的部分——发现服务,在代理和管理之间协调Engine的地址。目前使用的基于代理的发现服务是LibKV,它将发现功能委派给用户所选择的键值存储,Consul、Etcd或者Zookeeper。相对比而言,我们还可以不使用任何键值存储,仅仅使用Docker Swarm管理器。该模式称为无代理发现,包括File和Node(在命令行指定地址)。
术语
- Docker Engine是运行在宿主机上的Docker daemon。
- Docker Compose是一个工具,以YAML的格式描述多容器服务的架构方式。
- Docker stack是创建多容器的应用程序(由Compose描述),而不是单个容器的二进制结果。
- Docker daemon和 Docker Engine 这两个术语意思一样,可以互相替换。
- Docker客户端是打包在同一个docker可执行文件里的客户端程序。比如,当运行docker run时,使用的就是Docker客户端。
- Docker网络是软件定义的网络,将一系列容器链接到同一个网络里。默认使用Docker Engine自带的libnetwork(https://github.com/docker/libnetwork)实现。但是用户可以使用插件选择部署第三方的网络驱动。
- Docker Machine是一个工具,用来创建能够运行Docker Engine的称为机器的主机。
- Swarm v1里的Swarm节点是预先安装了Docker Engine的机器,并且同时运行着Swarm的代理程序。Swarm节点会将其自身注册到发现服务里。
- Swarm v1里的Swarm master是运行Swarm管理器程序的机器。Swarm master从其发现服务里读取Swarm节点的地址。
- 发现服务是Docker提供的基于令牌的服务或者自托管的服务。对于自托管的服务,用户可以运行HashiCorp Consul、CoreOS Etcd,或者Apache Zookeeper作为键值存储来提供发现服务。
- 选主是Swarm Master所实现的机制,用来确定主节点。在主节点下线之前,其他Master节点都作为副本角色存在,主节点下线后,就会再次启动选主程序。Swarm Master的数量一定是奇数。
- SwarmKit是由Docker发布的全新Kit,用来抽象编排。理论上,它应该能够运行任何类型的服务,但是实际目前它仅仅编排容器或者容器集。
- Swarm Mode是全新的Swarm,自Docker 1.12版本后可以用,它将SwarmKit集成到了Docker Engine里。
- Swarm Master(在Swarm Mode里)是一个管理集群的节点:它调度服务,维护集群的配置(节点、角色和标签),并且确保仅仅存在一个集群领导者。
- Swarm Worker(在Swarm Mode里)是一个运行任务的节点,运行如托管服务器任务。
- 服务是工作负载的抽象。比如,用户可以让服务“nginx”复制10次,意味着用户将有10个任务(10个nginx容器)分布在集群上,并且由Swarm自身做负载均衡。
- 任务是Swarm的工作单元。一个任务就是一个容器。

