MySql-索引
一、索引的本质
本质:索引是帮助MySql快速获取数据的排好序的数据结构。
二、 索引数据结构:
二叉树(不使用) :层级太高,自增主键索引甚至退化成了链表
红黑树(不使用) :红黑树是平衡二叉树的一种,相对于二叉树好点,但是当数据大时,层级还是很高,查询速度慢。
Hash表(不使用):读取单条数据速度比B+树快,但是对范围条件获取数据集合很慢,因为要逐一对比。
B-Tree(不使用):
1.叶节点具有相同的 深度,叶节点的指针为空
2.所有索引元素不重复
3.节点中的数据索引从左到右递增排序
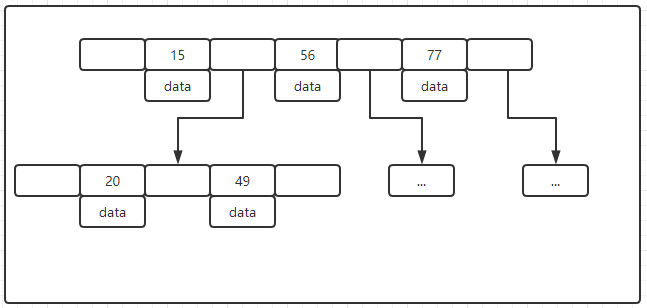
B+-Tree(使用) :B-Tree变种
1.非叶子节点不存储data,只储存索引(冗余),可以放更多的索引
2.叶子节点包含所有索引字段
3.叶子节点用双向指针连接,提高区间访问的性能(画图有点错误)
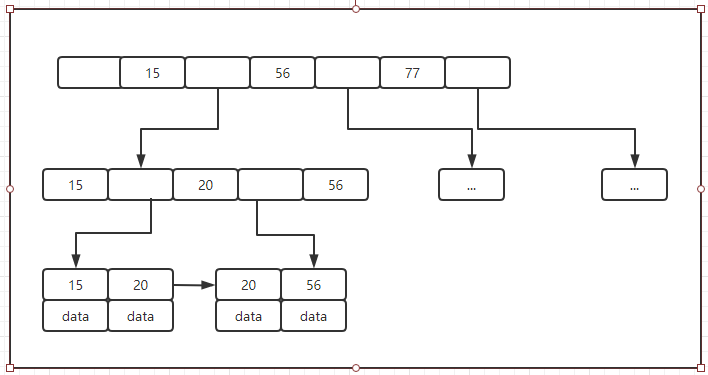
三、存储引擎索引
下面根据两个存储引擎所有进行下分析:MyISAM存储引擎索引、InnoDB存储引擎索引
MyISAM存储引擎索引:
MyISAM索引文件和数据文件是分离的(非聚集)
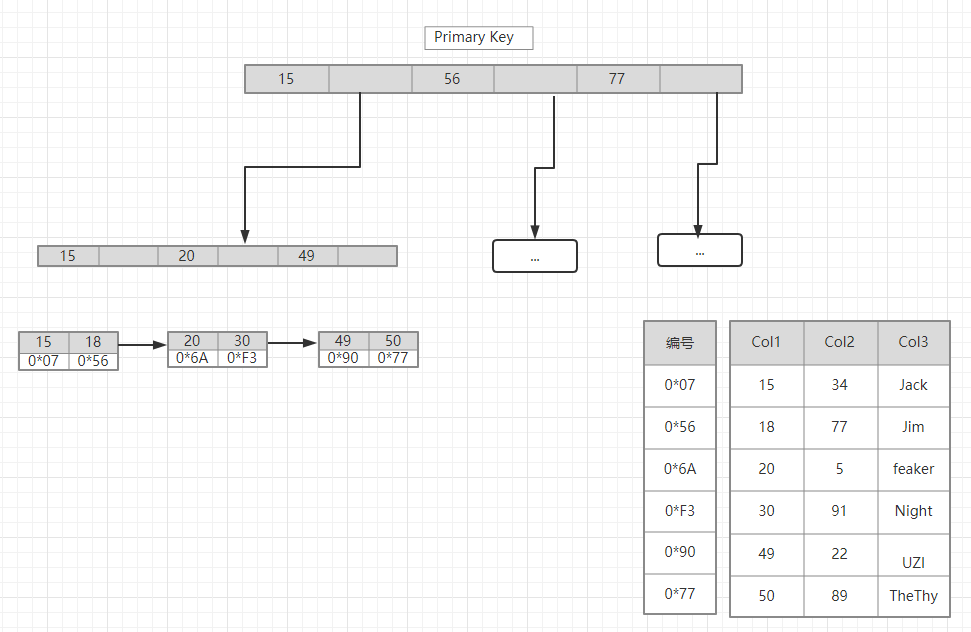
InnoDB索引实现(聚集)
1.表数据文件本身就是按B+Tree组织的一个索引结构文件
2.聚集索引-叶节点包含了完整的数据记录

问题1:为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键?
如果不主动为InnoDB表建立主键,sql会去找该表中不具有重复数据的列作为唯一导航,如找不到不重复的列,sql则会自动创建一个隐士的列作为唯一导航。性能会降低。
整形比对大小速度快,如果用字符串比较大小可能会从头部比较到尾部,占空间和性能也会很大
因为索引是排好序的数据结构,使用非自增的主键会导致树分裂(新增数据时),降低了性能。
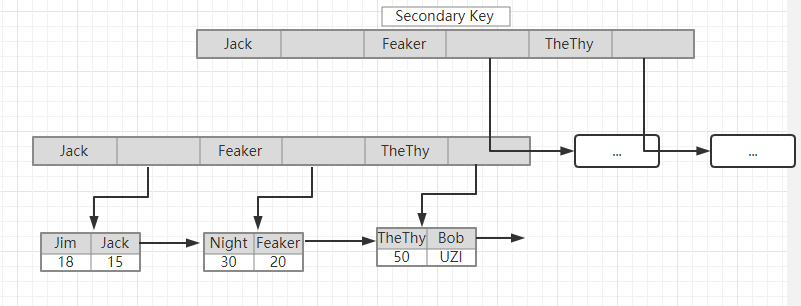
问题2:为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)
InnoDB索引的工作原理是:根据非主键索引查询时,先根据非主键索引查询到子节点获取到该主键索引,再根据主键索引查询到目标数据。保证了索引的一致性、节省了存储空间。
问题3:InnerDB和MyIsam的区别?
1.InnerDB聚集索引,索引文件和数据文件存放一起。MyIsam非聚集索引,索引文件和数据文件分开存放(MYD、MYI)。
2.InnerDB有事务,MyIsam没有事务
3.锁的力度控制,InnerDB默认支持行锁,锁的是索引,如果表里没有索引将转换成表级锁。MyIsam默认支持表锁
4.外键,InnerDB支持外键,MyIsam不支持外键
问题4:MySql的原子性和持久性怎么保证?
A 原子性 C 一致性 I 隔离性 D 持久性
原子性:利用undoLog又名回滚日志,记录上一个原子的状态
持久性:利用redoLog又名前滚日志,记录新数据的状态
mysql节点大小:
通过:show global status like 'innodb_page_size';返回值为:16384,即16k=2^16
每个索引元素大小:8Byte(索引)+6Byte(指针)
所以每个节点可存储的数据量为:16k/14=1170
数据不存储在非叶子节点(可存储更多索引)
四、MySql优化
索引最左前缀原理:
当我们建立聚合索引时,要遵循最左前缀原理。聚合索引存储的是聚合索引的所有字段,且是排好序的。如跨过最左前缀直接利用条件筛选后面的数据,会造成全局搜索。
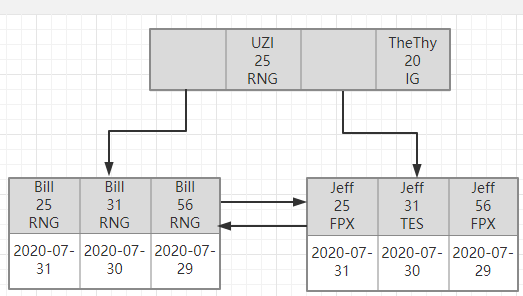
1.全值匹配
2.最左前缀法则
3.不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描
4.存储引擎不能使用索引中范围条件右边的列
5.尽量使用覆盖索引(只访问索引的查询(索引列包含查询列)),减少select*语句
6.mysql在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描
7.is null,is not null一般情况下也无法使用索引
8.like以通配符开通(‘$abc)mysql索引失效会变成全表扫描操作
如何使用全文索引
用MATHCH()...AGANIST方式来进行搜索
match()表示搜索的是那个列,against表示要搜索的是那个字符串
三种类型的全文搜索方式
1.natural language search(自然语言搜索):通过MATCH AGAINST 传递某个特定的字符串来进行检,默认方式
2.boolen search(布尔搜索):为检索的字符串增加操作符,如“+”表示必须包含,"-"不包含,"*" 表示通配符,即使传递的字符串较小或出现在停词中,也不会被过滤
3.query expansion search(查询扩展搜索):搜索字符串用于执行自然语言搜索,然后,搜索返回的最相关行的单词被添加到搜索字符串,并且再次进行搜索,查询将返回来自第二个搜索的行
Hash索引
MySql中只有memory存储引擎显示支持哈希索引。
hash索引就是存储了索引字段得hash值和数据所在磁盘文件指针。
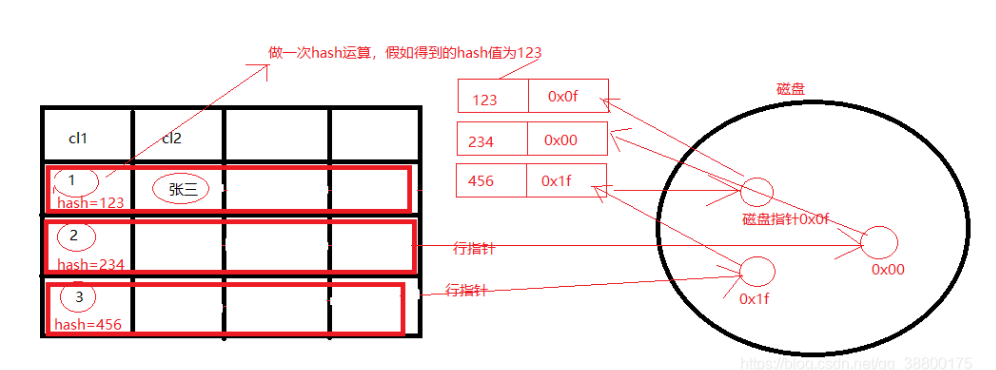
select * from tab where cl1 = 1 得执行顺序:
1.将cl1做一次hash运算得到hash为123
2.拿到hash为123在索引中去找123的节点
3.节点所对应的数据就是数据内容所在磁盘文件的指针
4.通过一次磁盘I/O得到所有的内容,即cl1=1,cl2=张三

 浙公网安备 33010602011771号
浙公网安备 33010602011771号