
编译器与解释器的区别和工作原理
首先,从Python这种编程语言说起。
它有以下几个特点:
- 面向对象:在本站的《Python3萌新入门笔记》中有专门的文章,简单来说是指在程序设计中能够采用封装、继承、多态的设计方法。
- 动态语言:是在运行时可以改变其结构的语言;例如,在程序运行过程中,给一个类的对象添加原本不存在的属性。
- 动态数据类型:变量不需要指定类型,但需要解释器执行代码时去辨别数据类型;这个特点让编程变得简单,但代码执行效率变低。
- 高级语言:是指高度封装了的编程语言,相对于机器语言,更加适合人类编写与阅读。
- 解释型语言:是指无需编译,直接能够将源代码解释为机器语言进行运行的语言。
从最后一个特点,我们能够看到Python是解释型语言,也就是说源代码需要通过解释器进行解释执行。
编程语言分为编译型语言和解释型语言,我们需要了解它们的区别,才能够更好的理解编译器和解释器的区别。
相信大家都知道C和C++。
这两种语言都是编译型语言。
编译型语言的特点是执行速度快,缺点是什么呢?
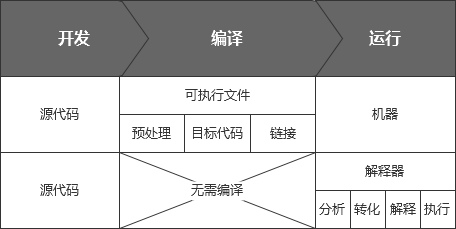
编译型语言需要编译器处理,主要工作流程如下:
源代码 (source code) → 预处理器 (preprocessor) → 编译器 (compiler) → 目标代码 (object code) → 链接器 (Linker) → 可执行程序 (executables)
在这个工作流程中,编译器调用预处理器进行相关处理,将源代码进行优化转换(包括清除注释、宏定义、包含文件和条件编译),然后,通过将经过预处理的源代码编译成目标代码(二进制机器语言),再通过调用链接器外加库文件(例如操作系统提供的API),从而形成可执行程序,让机器能够执行。
在这个工作流程中,目标代码要和机器的CPU架构相匹配,库文件要和操作系统相匹配。
如果想在不同CPU的机器或者系统上运行C语言的源代码,就需要针对不同的CPU架构和操作系统进行编译,这样才能够在机器上运行程序。
所以,编译型语言的缺点我们就看到了,它不适合跨平台。
而且,到这里大家应该能知道,为什么CPU一样,但是exe程序只能Windows中运行,而不能在Mac中运行了。
如果上面感觉不太好理解,我举一个贴近生活的例子:
一名会多国语言的老师教了很多外国学生,这些学生分别来自有英国、美国、法国、德国、韩国。
当这名老师给这些学生发放学习资料的时候,都需要把中文资料先进行翻译,变成英文版、德文版、法文版和韩文版的电子文档,再分别发给每个国家的学生去学习。
这个翻译的工作非常繁琐。
不仅,要翻译成每个国家的语言,而且,还要考虑英式英语和美式英语的区别分别翻译成不同的英文版。
再有,就是每次资料更新还都要重新翻译一遍。
在上面的例子中,中国老师就像是编译型语言的开发人员,中文资料就是编译型语言的源代码,翻译后的资料就是不同CPU架构的机器语言,不同语言的学生就是不同CPU架构的机器,美国和英国的学生,就是CPU架构相同但操作系统不同的机器。
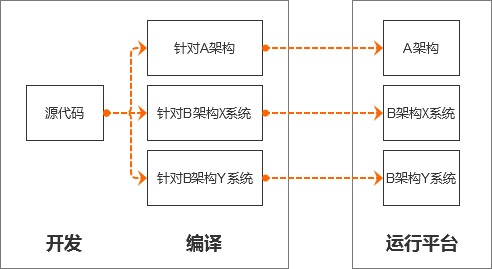
注意:这里涉及到跨平台的概念,平台可以理解为不同CPU架构(例如X86、ARM等)的机器和同种CPU但不同的操作系统(例如Unix、Windows等)的机器。
提示:建议大家阅读上述内容时,了解一下预处理器、链接器、库文件(静态链接库和动态链接库)的相关概念。
我们继续看刚才的例子。
这位累得要死的中国老师,开始想办法。
他想,我干嘛自己去翻译,给他们一人一个自动翻译软件不就好了?
于是,老师就给每个学生定制了一个自动翻译软件,这个软件能够一页一页的原始中文资料翻译成不同的语言资料给学生看。
现在的情况,这名老师工作会轻松很多,不需要再考虑制作各种语言版本的资料,只需要把精力放在制作中文资料就好了。
早期的解释器就是这样的工作流程:源代码 (source code) → 解释器 (interpreter) 。
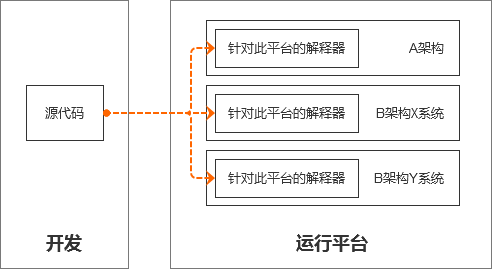
源代码无需预先编译成可执行程序。
在程序执行时,解释器读取一句源代码之后,先进行词法分析和语法分析,再将源代码转换为解释器能够执行的中间代码(字节码),最后,由解释器将中间代码解释为可执行的机器指令。
所以,编译型语言的可执行程序产生的是直接执行机器指令,而解释型语言的每一句源代码都要经过解释器解释为可以执行的机器指令,相比之下解释型语言的执行效率会低一些。
但是,解释型语言在不同的平台有不同的解释器,源代码跨平台的目的实现了,开发人员不用再考虑每个平台如何去编译,只需要关注代码的编写,编写完的代码在任何平台都能无需修改(或少量修改)就能正确执行。
例如,Linux系统中执行Python源代码时支持 fork()函数,而window系统中不支持这个函数,如果将运行在Linux系统中的源代码移植到Windows系统,这时就需要进行修改。
理解了编译型语言和解释型语言的区别,我们继续看例子。
老师虽然给学生定制了翻译软件,但是发现这个软件翻译每页内容都很慢,究其原因,这个软件需要先把每页内容分析一遍,将内涵复杂的中文(例如成语)转换成简单直接能够直接进行翻译的中文,再进行向其它国家语言的翻译。
看到这个问题之后,软件的提供商想出了一个解决方案。
这个方案就是:第一次打开资料时,让翻译软件把原始资料完整的进行分析转换,保存成一个能够直接翻译的中间文件;然后,翻译程序再一页一页的读取转换后的中间文件去翻译;这样的话,虽然第一次打开时慢了些,但是,当学生再次打开资料时,只要原始资料没有更新,就直接通过保存的中间文件进行翻译,速度会有很大提升。当然,程序打开时,需要对比一下原始资料是否和中间文件一致,如果有修改,则再次编译出新的中间文件,覆盖旧的中间文件。
Python程序运行时,就像上面的例子一样,先将源代码完整的进行转换,编译成更有效率的字节码,保存成后缀为“.pyc”的字节码文件,然后,翻译器再通过这个文件一句一句的翻译为机器语言去执行。
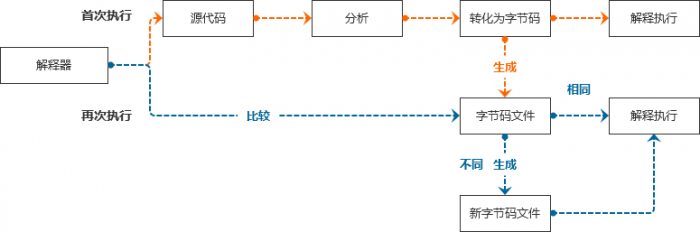
注意:Shell中执行源代码时不会生成中间文件,每次都是读取源代码,转化为字节码后,解释执行。
上面的例子还没结束。
软件供应商提出的方案虽然解决了一些效率问题,但是还无法完全让人满意。
经过苦思冥想,软件供应商又想出了一个新的方案。
在原始资料中有很多重复的内容;
这些重复的内容如果翻译一次之后,就把它保存,再碰到相同的内容就直接使用保存的翻译结果。
而没有必要每次都再翻译。
长时间运行程序时,速度就会快上很多。
这个例子实际上就是JIT即时编译器(Just-In-Time Compiler)的比喻。
无论是使用解释器进行解释执行,还是使用编译器进行编译后执行,最终源代码都需要被转换为对应平台的本地机器指令。
那么,一些重复出现的代码,就可以将其编译为本地机器指令,重复使用,从而提高效率。
这些重复出现的代码包括多次调用的方法和多次执行的循环体。
JIT即时编译器比较典型的例子是在JVM(Java虚拟机)中。
Java程序最初是通过解释器进行解释执行的,当Java虚拟机发现某个方法或代码块运行特别频繁的时候,就会认为这是“热点代码”(Hot Spot Code)。JIT即时编译器会将这些“热点代码”编译成与本地机器相关的机器指令,进行各个层次的优化。
当程序需要迅速启动和执行的时候,解释器可以首先发挥作用,省去编译的时间,立即执行。在程序运行后,随着时间的推移,编译器逐渐发挥作用,把越来越多的代码编译成本地机器指令之后,可以获取更高的执行效率。当程序运行环境中内存资源限制较大,可以使用解释器执行节约内存,反之可以使用编译执行来提升效率。
大家都知道,Java程序的运行性能很高,基本上可以和C/C++的程序相媲美。这主要是因为JIT即时编译器可以针对那些频繁被调用的“热点代码”做出深度优化,而静态编译器无法完全推断出哪些是运行时的热点代码,而不能做出针对性的优化。因此,通过JIT即时编译器编译的本地机器指令才会比直接生成的本地机器指令拥有更高的执行效率。
Python有多种解释器,比较著名的有CPython、IPython、PyPy、Jython和IronPython等。
其中CPython是Python官方默认的解释器,它是用C语言实现Pyhon解释器。
CPython是单纯的解释器,将源代码转化为字节码之后解释执行。
而另外一款使用Python实现的Python解释器PyPy,比CPython解释器更加灵活。因为PyPy采用了JIT技术,在程序的运行性能上PyPy将近是CPython解释器执行效率的1至5倍。
而其它的解释器都各有特点。
IPython是基于CPython增强了交互。
Jython是运行在Java平台上的Python解释器。
IronPython是运行在.Net平台上的Python解释器。
以上就是对编译器和解释器区别和工作原理的讲述,因为没有找到现成的资料,所以,其中内容参考了很多网上的资料,多番查证后,进行了融合。如果有解释错误,或者讲解不透彻的地方,欢迎大家指正并提出建议。
转载来自:魔力Python » 编译器与解释器的区别和工作原理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号