
Kafka学习笔记(三):Producers, Message Keys and Consumers
Producers
- 生产者向主题分区写入数据
- 生产者事先知道写入到哪个分区,哪个kafka代理拥有它
send()异步发送
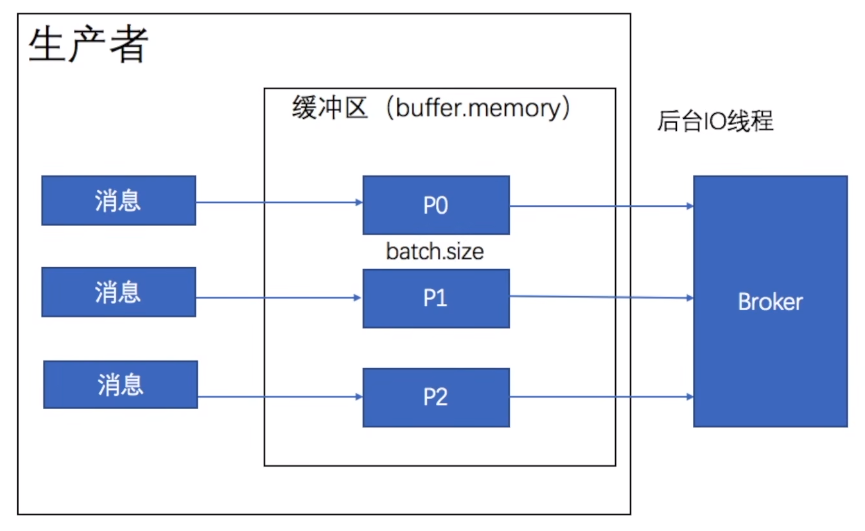
缓冲区会为主题的每个分区创建一个大小用来存放消息,生产者首先将消息放入到对应分区的缓冲区中,当他放入消息后立刻返回,不等消息是否发送给服务端,也不管它是否成功发送消息,后台IO线程负责将消息发送给broker。
同步发送
Future<RecordMetadata> result = producer.send(new ProducerRecord<String, String>("topic_name", "" + (i%5), Integer.toString(i)));
try{
RecordMetadata recordMetadata = result.get(); //阻塞
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
批量发送
linger.ms 每一批消息最大大小
batch.size 延迟时间
满足任意一项即可
acks
- acks=0 生产者不会等待服务器端的任何请求,当消息被放到缓冲区的时候,我们就认为他成功发送了,可能会造成数据丢失
- acks=1 消息已经被服务器端的leader存入到本地了,leader未同步到follower就宕机会导致数据丢失
- acks=all
至多一次 acks=0或1
至少一次 acks=-1或all, retries>0
Producers: Message keys
- 生产者可以发送带有key (string, number, binary, etc...) 的消息
- 如果key=null,数据将循环发送到各分区
- 如果key!=null,那么数据将一直发送到相同分区(哪个分区由生产者决定)
- 如果你需要根据指定字段对消息进行排序,那么就需要发送key
Kafka消息剖析
- key、value(可以为空)
- 压缩格式:none,gzip,snappy,lz4,zstd
- Headers:可选的键值对列表
- 消息要发送到的分区及其偏移量
- 时间戳(由系统或者用户设置)
Kafka 消息key哈希算法
targetPartition = Math.abs(Utils.murmur2(keyBytes))%(numPartitions-1)
Consumers
- 消费者根据 name 从某个 topic 读取数据,是 pull model,不是kafka server把数据推送给消费者
- 消费者自动知道从哪个broker读取数据
- 如果broker失效了,消费者知道如何恢复
- 在每个分区中,数据根据 offset 从低到高被读取
生产者:精确一次
enable.idempotence=true
##retries=Integer.MAX_VALUE
acts=all
消费者:精确一次
通过offset来防止重复消费不是一个好的办法
通常在消息中加入唯一ID (例如流水ID,订单D),在处理业务时,通过判断 ID来防止重复处理
事务
在kafka中,消息会尽可能地发送到服务端,如果提交成功了,消息后面会有成功提交的标志,如果未成功提交,那么它的状态是未提交的。
Isolation_level 隔离级别,默认为 read_uncommitted 脏读,如果只读取成功提交的数据,可以设置为 read_committed
