土地利用变化的桑吉图
 python 土地利用桑吉图绘制(炒冷饭bushi)
python 土地利用桑吉图绘制(炒冷饭bushi)
土地利用转移矩阵与桑吉图制作教程
💡首先,你需要有多年土地利用图、ArcGIS、python环境(装有gdal、pandas、pyecharts)
1 ArcGIS波段合成
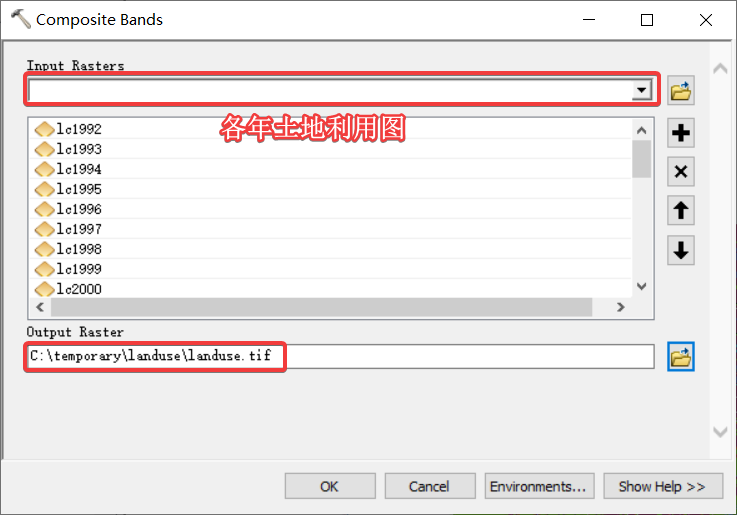
2 python读取并制作土地利用转移矩阵
需要的包主要是gdal【读取tif图像并转成array】、pandas【将array转成dataframe进行进一步的处理】
from osgeo import gdal
import pandas as pd
import os
os.chdir(r'H:\landuse')
# 读取多波段合成后的栅格数据
dataset = gdal.Open(r'landuse.tif')
# 判断是否读取到数据
if dataset is None:
print('Unable to open *.tif')
sys.exit(1) # 退出
projection = dataset.GetProjection() # 投影
geotrans = dataset.GetGeoTransform() # 几何信息
im_width = dataset.RasterXSize #栅格矩阵的列数
im_height = dataset.RasterYSize #栅格矩阵的行数
im_bands = dataset.RasterCount #波段数
# readasarray直接读取dataset
img_array = dataset.ReadAsArray()
print('处理图像波段数:{0} 行数有:{1} 列数:{2}'.format(im_bands,im_height,im_width))
将图像转成年份为列的dataframe,并去除空值。
img = img_array.reshape(im_bands, im_height*im_width).T
df = pd.DataFrame(img)
# 创建年份列表
year_list = []
for i in range(1992,2021):
year_list.append(str(i))
# 删除含有0(空值)的列
df.columns = year_list
for i in year_list:
df = df.drop(index = df[(df[i] == 0)].index.tolist())
建立土地利用属性值与名称的查找表,并读取。将dataframe中的属性值转为土地利用类型名称。
df_lookup = pd.read_excel('landuse_lookup table.xlsx', sheet_name = 'lookup table')
vlist = list(df_lookup['value'])
lclist = list(df_lookup['class'])
for i in range(0, len(vlist)):
df[df == vlist[i]] = lclist[i]
# 导出关键图表,以便下次分析
df.to_csv('raw.csv', index = False)
# 按需创建并导出全转移矩阵表
# df1 = df.groupby(year_list).size().reset_index(name='Size')
# df1.to_csv(r'landuse.csv', index=False)
3 python桑基图的数据准备与制作
选取需要做桑吉图的年份,并对dataframe做预处理。
df = pd.read_csv('raw.csv')
selected_year=['1992','2000','2010','2020']
df_sankey = df.groupby(selected_year).size().reset_index(name="Size")
#df_sankey.to_csv('sankey.csv', index=False)
# 为每一列添加年份
for i in range(0,len(df_sankey.columns)-1):
df_sankey[df_sankey.columns[i]] = df_sankey[df_sankey.columns[i]] + df_sankey.columns[i]
nodes=[]
for i in range(len(selected_year)):
values=df_sankey.iloc[:,i].unique()
for value in values:
dic={}
dic['name']=value
nodes.append(dic)
# print(nodes)
re = pd.DataFrame()
for i in range(len(selected_year)-1):
f = df_sankey.groupby([selected_year[i],selected_year[i+1]])['Size'].sum().reset_index()
f.columns = ['source','target','value']
re = pd.concat([re, f], axis=0)
linkes=[]
for i in re.values:
dic={}
dic['source']=i[0]
dic['target']=i[1]
dic['value']=i[2]
linkes.append(dic)
# print(linkes)
上面的nodes和links就已经准备好输入桑吉图出图了,其中#为每一列添加年份挺重要的❗至于为啥重要,我也不知道😂后面就是采用pyechart中的桑吉图制作方法制作啦。
from pyecharts.charts import Sankey
from pyecharts import options as opts
pic = (
Sankey(init_opts = opts.InitOpts(width='2300px', height='1100px'))
# .set_colors(colors)
.add('',
nodes,
linkes,
pos_top="10%",
focus_node_adjacency=True,
node_align = 'justify',
node_gap = 25,
orient = 'horizontal', #vertical
linestyle_opt=opts.LineStyleOpts(width = 1.5, opacity = 0.3, curve = 0.5, color = 'source'),
label_opts=opts.LabelOpts(font_size = 18, font_family = 'Times New Roman', position = 'right'))
.set_global_opts(
tooltip_opts=opts.TooltipOpts(trigger="item", trigger_on="mousemove"),
toolbox_opts=opts.ToolboxOpts(feature = opts.ToolBoxFeatureOpts(save_as_image = opts.ToolBoxFeatureSaveAsImageOpts(background_color = "white", pixel_ratio = 2)))
# title_opts=opts.TitleOpts(title = '昭通市土地利用变化'),
))
#Jupyter Notebook中可以添加这一行以预览
pic.render_notebook()
pic.render('sankey.html')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号