
JVM----Class类文件结构
JVM平台无关性
Java具有平台无关性,也就是任何操作系统都能运行Java代码。之所以能实现这一点,是因为Java运行在虚拟机之上,不同的操作系统都拥有各自的Java虚拟机,因此Java能实现“一次编写,处处运行”。而JVM不仅具有平台无关性,还具有语言无关性。 平台无关性是指不同操作系统都有各自的JVM,而语言无关性是指Java虚拟机能运行除Java以外的代码!这听起来非常惊人,但JVM对能运行的语言是有严格要求的。
首先来了解下Java代码的运行过程。Java源代码首先需要使用Javac编译器编译成class文件,然后启动JVM执行class文件,从而程序开始运行。 也就是JVM只认识class文件,它并不管何种语言生成了class文件,只要class文件符合JVM的规范就能运行。 因此目前已经有Scala、JRuby、Jython等语言能够在JVM上运行。它们有各自的语法规则,不过它们的编译器都能将各自的源码编译成符合JVM规范的class文件,从而能够借助JVM运行它们。
Class文件结构
1.魔数
Class文件是一组以8位字节为基础单位的二进制流,包含多个数据项目(数据项目的顺序,占用的字节数均由规范定义),各个数据项目严格按照顺序紧凑的排列在Class文件中,不包含任何分隔符,使得整个Class文件中存储的内容几乎全部都是程序运行的必要数据,没有空隙。当遇到需要占用超过8位字节以上空间的数据项目时,会按照高位在前的方式分割为多个8位字节进行存储
数据项目分为2种基本数据类型(以及由这两种基本数据类型组成的集合):
1,无符号数,以u1、u2、u4、u8分别代表1个字节、2个字节、4个字节、8个字节的无符号数
2,表,以“_info”结尾,由多个无符号数或其它表构成的复合数据类型
Class文件格式如下表所示:
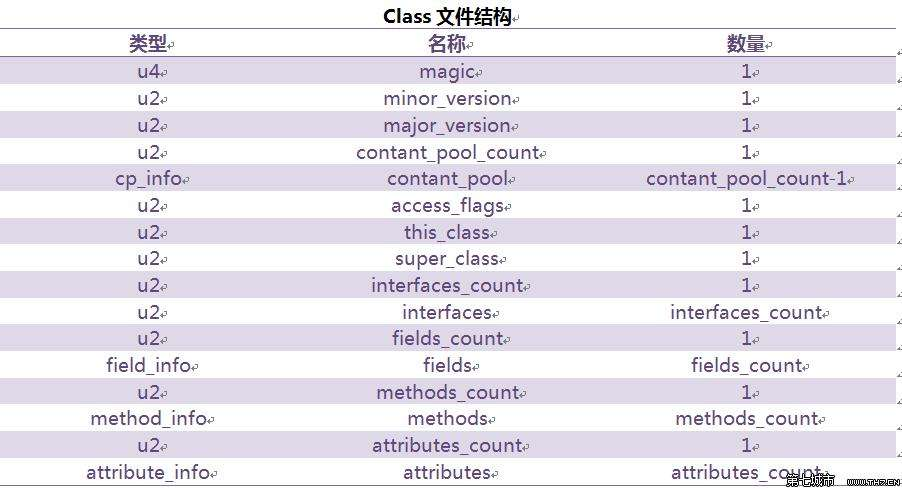
在上图中,在数量字段中,有些是1而有些则不是,不是1的代表的是相同类型的多个数据,将这一系列连续的数据成为称为某一个类型的集合。class文件的格式要求非常严格,这个字节代表什么,长度,先后顺序如何,都是死的,不能改变,比如如下代码:
public class TestClass {
private int m;
public int inc() {
return m + 1;
}
}
这个class文件的头四个字节为“CAFEBABE”,他的作用是确定该文件是否是一个能被jvm解析的class文件,被称为“魔数”。
![]()
紧接着魔数的四个字节存储的是Class文件的版本号,第五和第六是次版本号,第七和第八是主版本号,在上图中,该版本为50。
2.常量池
从class文件结构图中可以看到,紧接着魔数的是常量池入口,常量池可以被认为是Class文件中的资源仓库,它是class文件中与其他资源关联最多的数据类型,也是占用class空间最大的一个数据项,也是class文件中第一个出现的表类型的数据项。
由于常量的数目是不确定的,所以在常量池的入口放一个u2类型的数据“content_pool_count”,用来代表常量池容量计数器。注意:常量池的数目是从1开始的,不是从0。上面贴出的十六进制图中,偏移地址对应0x00000008,也就是0x0016,对应的十进制数是22,也就是说常量池为21个常量,1~21。为什么从1开始,而不是0,因为0代表的是该class文件的特殊情况:不引用任何一个常量。不过其他的类型集合,都是从0开始的!
常量池主要存放两大类常量:
(1)字面量:如文本字符串、final变量。
(2)符号引用:符号引用又分为三种
* 类和接口的全限定名
* 字段的名称及描述
* 方法名称及描述
Java代码编译完之后,class文件不会保存各个方法字段的最终内存信息,而是在运行期间,从常量池中获得对应的符号引用,在类创建时或者运行时解析,再翻译到具体的内存地址。
常量池中每一个常量都是一个表,这些常量都有一个特点,就是表的开始的第一位是u1类型的数据,它是一个标志位(tag),代表这个常量是哪种类型如图:
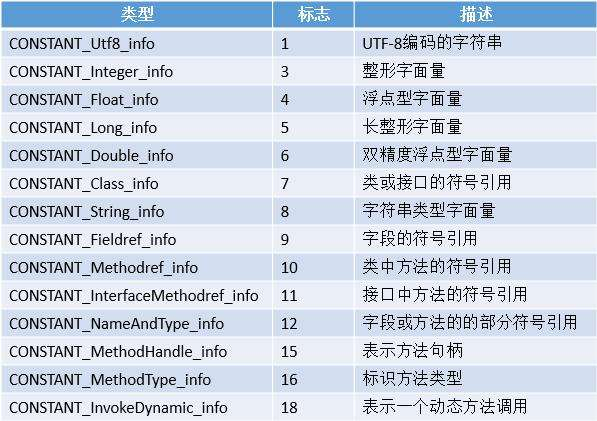
每种常量他们都是一张表,而这些表,他们每个结构都是不一样的。常量池入口后面的0x07就是一个标志位,代表的是CONSTANT_Class_info常量,之后的0x01代表的是CONSTANT_Utf-8_info,也就是该常量池的第二项常量。并且方法、字段等都需要引用CONSTANT_Utf-8_info来描述,所以CONSTANT_Utf-8_info的最大长度就是Java方法和字段的最大长度,因为u2类型的数据最大值为65535,所以方法和字段最大就是64KB,否则无法编译。
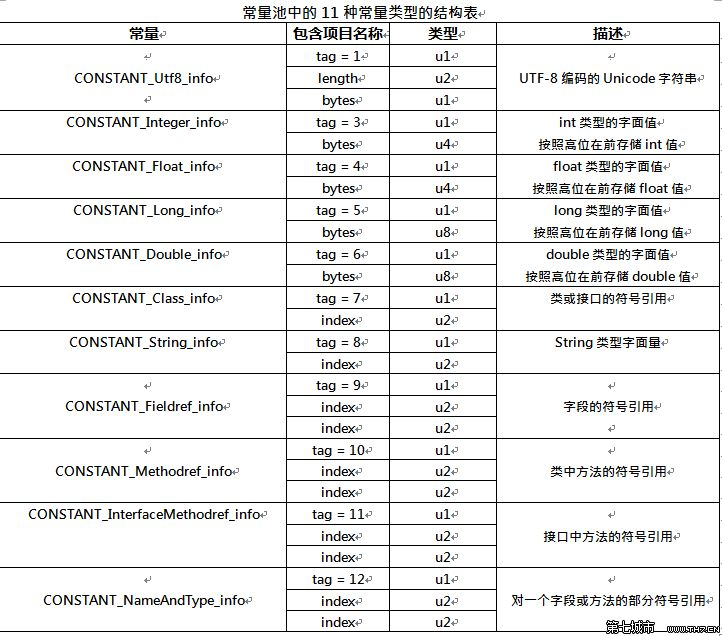
14种常量池的各自结构如下:
3.访问标志
常量池结束之后,紧着有俩字节代表的是访问标志,用于识别一些类或者接口层次的访问信息。包括,该class是类还是接口,是否为public,是否定义了abstract,如果是类的话,是否有final属性。

根据上面的表格,测试类的访问标志为ACC_PUBLIC | ACC_SUPER = 0x0001 | 0x0020 =1 | 32 = [00000000][00000001] | [00000000][00010000] = [00000000][00010001] = 33 = 0x0021
4.类索引、父类索引与接口索引集合
类索引、父类索引都是一个u2类型的数据,接口索引集合也是一个u2类型的数据,class文件通过这三个数据项来确定这个类的继承关系。类索引用于确定这个类的全限定名,父类索引用于确定父类的全限定名。父类索引最多有两个(其中有一个是Object)。
类索引、父类索引、接口索引都在访问标志之后,引用CONSTANT_Class_info,再通过引用到CONSTANT_Utf-8_info,代表的是该类的全限定名的字符串。对于接口索引集合,入口的第一项就是u2类型的计数器,表示的是索引的接口的数目,如果没有实现接口,就是0。
5.字段表集合
字段表负责描述接口或类中的声明的变量,该字段包括了类变量和实例变量,但是不包括局部变量。一个字段可以包含的信息:字段的访问权限,字段的修饰符,字段的名称,字段所属的类型。字段的类型、字段名字,这些都是无法固定的,所以通过符号引用来标识。
如下图所示的是字段表,第一个是access_flags,这个和类索引里的是一样的,name_index和descriptor_index,name_index代表的是一个字段的简单名称,例如上面代码里的m,简单名称就是m。
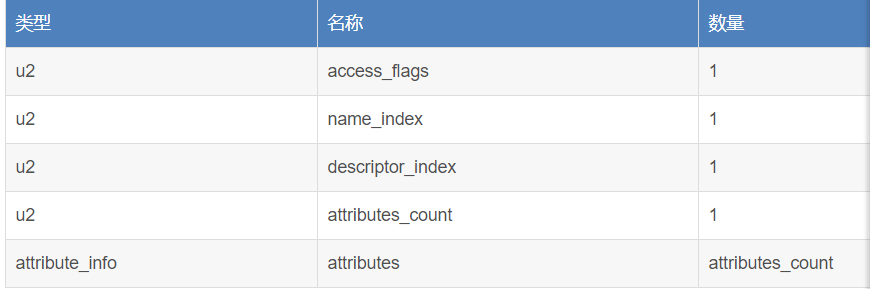
descriptor_index代表的是描述符,字段和方法的描述符就是指字段的数据类型、方法参数列表、返回值。描述符标识符含义如图所示:
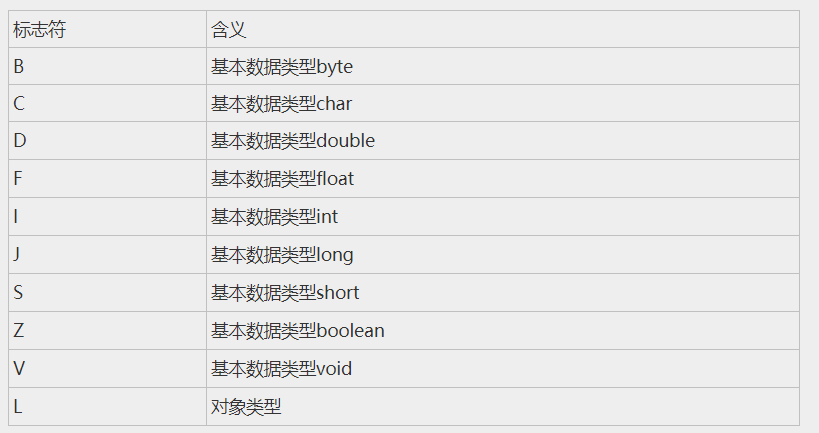
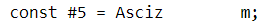 这个是name_index对应的是字段的简单名称
这个是name_index对应的是字段的简单名称
 这个是descriptor_index对应的是字段的描述符
这个是descriptor_index对应的是字段的描述符
通过上面的分析,我们可以得出该字段的是:int m。
字段表的固定数据(访问标志、简单名称、类型)到这里就结束了,descriptor_index后面还存储着一些其他的信息,这些属于描述字段的额外信息,如果是
static final int m=1;那么就还存在一个ConstantValue的属性,指向常量1。
6.方法表集合
方法表集合和之前的字段表集合有很多相似之处,方法表结构和字段表集合一样,也是开头就是access_flags(描述该方法的一些访问标识),之后就是name_index(方法的简单名称),descriptor_index(方法的描述符:方法参数列表、返回值),属性表集合。
第一个方法(由编译器自动添加的默认构造方法):

access_flags为0x0001,即public;name_index为0x0007,即常量池中第7个常量;descriptor_index为0x0008,即常量池中第8个常量
const #7 = Asciz <init>;
const #8 = Asciz ()V;第一个方法是init(name_index对应的是7),而描述符就是()V(descriptor_index对应的是8)
7.属性表集合
属性表在前面已经出现了多次,包括字段表集合、方法表集合,属性表可以用来描述某些特殊场合下的专有信息。与Class文件中其它数据项对长度、顺序、格式的严格要求不同,属性表集合不要求其中包含的属性表具有严格的顺序,并且只要属性的名称不与已有的属性名称重复,任何人实现的编译器可以向属性表中写入自己定义的属性信息。虚拟机在运行时会忽略不能识别的属性,为了能正确解析Class文件,虚拟机规范中预定义了虚拟机实现必须能够识别的9项属性:
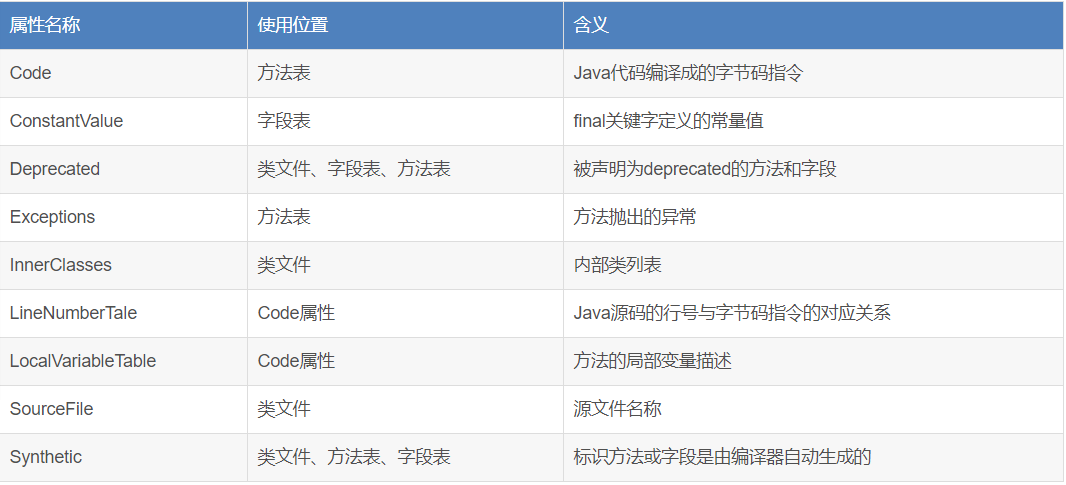
Code属性:Java程序方法体中的代码经过Javac编译器处理后,最终变为字节码指令存储在Code属性中。当然不是所有的方法都必须有这个属性(接口中的方法或抽象方法就不存在Code属性),Code属性表结构如下:
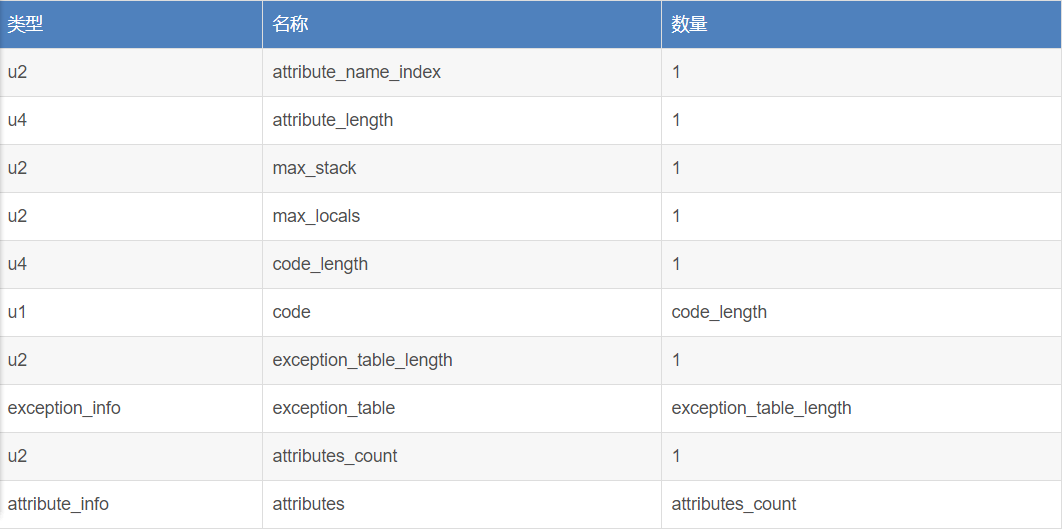
max_stack:操作数栈深度最大值,在方法执行的任何时刻,操作数栈深度都不会超过这个值。虚拟机运行时根据这个值来分配栈帧的操作数栈深度。
max_locals:局部变量表所需存储空间,单位为Slot(参见备注四)。并不是所有局部变量占用的Slot之和,当一个局部变量的生命周期结束后,其所占用的Slot将分配给其它依然存活的局部变量使用,按此方式计算出方法运行时局部变量表所需的存储空间。
code_length和code:用来存放Java源程序编译后生成的字节码指令。code_length代表字节码长度,code是用于存储字节码指令的一系列字节流。
每一个指令是一个u1类型的单字节,当虚拟机读到code中的一个字节码(一个字节能表示256种指令,Java虚拟机规范定义了其中约200个编码对应的指令),就可以判断出该字节码代表的指令,指令后面是否带有参数,参数该如何解释,虽然code_length占4个字节,但是Java虚拟机规范中限制一个方法不能超过65535条字节码指令,如果超过,Javac将拒绝编译。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号