三:JVM(重点)
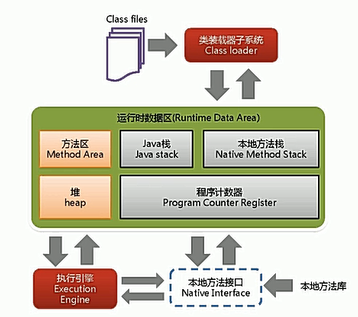
1.类加载器(将字节码文加加载到方法区 这里有一个验证的过程,错误的class将会被jvm吐出)重点
1.1 虚拟机加载器
启动类加载器:Bootstrap 通过getClassLoder获得的是Null。例如object类和String类的类加载器就是null因为权限不够
扩展类加载器:extension javax开头的包就是扩展的加载器的包
应用程序类加载器:Appclassloder 自己写的类的加载器。java也叫系统类加载器,加载当前应用的classpath的所有类
1.2 用户自定义加载器
Java.lang.classloader的子类用户可以定制类的加载方式。
1.3 沙箱安全机制:
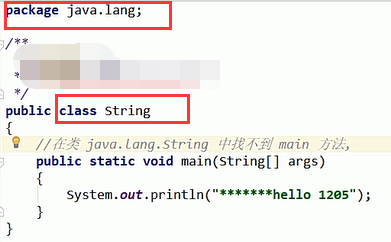
1.先去启动类里面找,找的到就用,找不到就去扩展类加载器中去用,如果还是找不到就去应用程序类加载器中去用:例如下面会包错找不到main方法
1.4双亲委派机制:
当一个类收到了类加载请求,他首先不会尝试自己去加载这个类,而是把这个请求委派给父类去完成,每一一个层次类加载器都是如此,因此所有的加载请求都应该传送到启动类加载其中,只有当父类加载器反馈自己无法完成这个请求的时候(在它的加载路径下没有找到所需加载的Class),子类加载器才会尝试自己去加载。
采用双亲委派的一一个好处是比如加载位于rt,jar包中的类java.lang.Object, 不管是哪个加载器加载这个类,最终都是委托给顶层的启动类加载器进行加载,这 样就保证了使用不同的类加载器最终得到的都是同样一个 Object对象。
2.执行引擎执行
3.本地接口(重点)native只有声明没有实现 因为实现不在JAVA中而在第三方(底层)
本地方法接口native interface:用native标注的方法就已经超出了JAVA的管辖范围就要等待C或者底层第三方函数库去实现
本地方法加载到本地方法栈中
4.PC寄存器:程序计数器(就相当于程序运行顺序表每个各自存着下一条代码的内存地址。)
记录了方法之间的调用和执行情况,类似排班值日表,用来存储指向下一条指令的地址,也即将要执行的指令代码,他是当前线程所执行的字节码的行号指示器
5.方法区:
5.1 他存储了每一个类的结构信息(模板)
5.2 方法区是规范,在不同的虚拟机里头实现是不一样的。最典型的就是永久代(PermGen Space)和元空间(Metaspace)Static就应该是在方法区中的吧 方法区中的数据在JVM关闭后才会清除
6.栈管运行,堆管存储
程序=算法+数据结构
工作上:程序=框架+业务逻辑
7.栈是线程创建时创建,线程结束内存就会释放,对于栈来说,不存在垃圾回收的问题,只要线程一结束栈内的内存就over,生命周期和线程一致,是线程私有的。8种基本类型的变量+对象引用的变量+实例方法都是在函数的栈内存中分配。
栈存储3类数据:
本地变量:输入参数和输出参数以及方法内的变量
栈操作:记录出栈,入栈的操作
栈帧数据:包括类文件,方法等
8.JAVA方法在JVM栈空间中叫做“栈帧”
9.exception是错误,不是异常
10.Hotspot是使用指针的方式来访问对象;Java堆中会存放访问类元数据的地址,reference储存的就直接是对象的地址
11.堆(heap)内存(逻辑上分为三个部分:新生,养老,永久代默认新生代内存8:1:1;物理上:新生+养老):
1. new 新生区 1/3的堆空间
1.1.伊甸园(Eden Space) 又称 young区
1.2.幸存者0区 (Survivor 0 Space) 又称 from区
1.3.幸存者1区 (Survivor 1 Space) 又称 to区
2. old 老年代:15次的后才会到老年区可以自己修改,但是最大不能超过15 2/3的堆空间
3. 元空间 (方法区是个规范:元空间实现 永久储存空间有的人也成永久带)
12.minorGC机制(GC之后有交换,谁空谁是to) 新生区的GC
复制->清空- >交换
13 majorGC机制 养老区的GC
14 JAVA8以后的元空间并不在虚拟机中而是在使用本机物理内存
15 堆内存调优(重点)
-Xms 设置JVM堆内存的初始分配大小,默认为物理内存的1/64
-Xmx JVM堆内存最大分配内存,默认为物理内存的1/4
-XX:+PrintGCDetails 输出详细的GC处理日志
重点:必须把Xms调到-Xmx一样大,避免GC和应用程序争抢内存,内存忽高忽低
eclipse在run config里面调VM参数就可以了
代码查看:


package testMain; public class JVMRun { public static void main(String[] args) { System.out.println(Runtime.getRuntime().availableProcessors()); long maxMemory = Runtime.getRuntime().maxMemory(); // 返回JAVA虚拟机试图使用的最大内存量 long totalMemory = Runtime.getRuntime().totalMemory(); //返回JAVA虚拟机中的内存总量 System.out.println("MAX memory = "+maxMemory+"(字节), "+maxMemory/1024/1024+"MB"); System.out.println("total memory = "+totalMemory+"(字节), "+totalMemory/1024/1024+"MB"); byte[] bytes = new byte[40*1024*1024]; } }
16:可能有人有疑问:为什么调内存只调堆,不调栈呢?
还是那句话,堆管存储,栈管运行(栈需要的内存很小因为,每一条指令的操作都是pc寄存器在引导,出栈入栈也是)
虚拟机栈有一帧帧的 栈帧组成,而栈帧包含局部变量表,操作栈等子项,那么线程在运行的时候,代码在运行时,是通过程序计数器不断执行下一条指令。真正指令运算等操作时通过控制操作栈的操作数入栈和出栈,将操作数在局部变量表和操作栈之间转移。
17.GC日志信息
GC一般发生在young区,产生GC是因为new失败了,内存不够用了,所以才发生垃圾回收机制
发生OOM一般是full GC失败,fullGC在老年区
18 GC
GC是什么(分代收集算法)
1.次数上频繁收集young区
2.次数上较少收集old区
3.基本不动元空间
Minor GC(普通GC) 和Full GC(全局GC)的区别: full GC要比 MinorGC慢10倍以上,原因是,Full GC要扫描Old区,Old区空间大,要扫描的东西多,所以才慢
4算法:
1.引用计数法 (后台有一个大型的计数器在计算每一个对象的引用次数)
缺点:每次对对象赋值时均要维护应用计数器,且计数器本身也有一定的消耗
较难处理循环引用
2.复制算法 copying
用在:年轻代中使用的是minor GC,这种GC算法采用的是复制算法,复制算法的基本思想就是将内存分为两块,每次只用其中一块,当这一块内存用完,就将还活着的对象复制到另外一块上面。
优点:复制算法不会产生内存碎片(也就是Form 和to的交换过程)
缺点:浪费太多的内存,如果对象存活率高的话,就很麻烦,因为要把所有都复制一遍
3.标记清除 Mark - Sweep
用在:老年代 一般是由标记清除或者是标记清除与标记整理的混合实现
原理:算法分成标记和清除两个阶段,先标记出要回收的对象,然后统一回收这些对象(解决浪费空间的问题)用通俗的话解释一下标记清除算法,就是当程序运行期间,若可以使用的内存被耗尽的时候,GC线程就会被触发并将程序暂停,随后将 要回收的对象标记- -遍,最终统一回收这些对象,完成标记清理工作接下来便让应用程序恢复运行
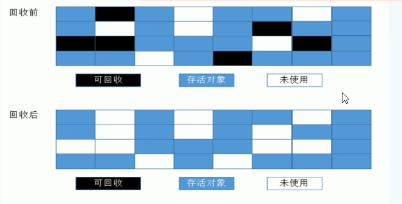
优点: 不需要额外的空间
缺点: 两次扫描(标记一次清除一次),耗时严重
会产生内存碎片(内存不连续)
4.标记压缩 Mark - Compact (慢工出细活,理论上最好的算法,但是耗时)
原理 : 1.标记 (与标记清除一样会先标记在清除) 2.压缩:再次扫描,并在一端滑动存活对象(优点没有内存碎片,可以利用dump 缺点:需要移动对象的成本)
用处:老年代一般是由标记清除或者是标记清除与标记整理的混合实现
小总结:
内存效率:复制算法>标记清除算法>标记整理算法(此处的效率只是简单的对比时间复杂度,实际情况不一定)
内存整齐度:复制算法=标记整理算法>标记清除算法
内存利用率:标记整理算法=标记清除算法>复制算法
没有最好的算法,只有合适的算法-----》分代收集算法
年轻代:存货率低,所以使用复制算法
老年代:区域大对象存活率高GC的次数比较少,一般由标记清除和标记整理混合实现
面试题:
1:JVM内存模型以及分区,需要详细到每个区放什么
2.:堆里面的分区 :Eden,survival from to,老年代,各自的特点
3.GC的三种收集方法:标记清除,标记整理,复制算法的原理与特点,分别用在什么地方
4.Minor GC与full GC分别在什么时候发生
19.JMM
先看这两篇:
https://www.jianshu.com/p/8a58d8335270
https://zhuanlan.zhihu.com/p/29881777
20:加载顺序
父类的静态字段——>父类静态代码块——>子类静态字段——>子类静态代码块——>父类成员变量(非静态字段)——>父类非静态代码块——>父类构造器——>子类成员变量——>子类非静态代码块——>子类构造器

 浙公网安备 33010602011771号
浙公网安备 33010602011771号