逻辑回归
\(\;\;\;\;\;\)逻辑回归(Logistics Regression)并非回归模型,之所以名字带有回归二字,是因为逻辑回归脱胎于线性回归。回归模型通常使用曲线来拟合数据点,目标是使曲线到数据点的距离差异最小。而线性回归是回归问题中的一种,线性回归假设目标值与特征之间线性相关,即满足一个多元一次方程。
线性回归
\(\;\;\;\;\;\)假设\(x_j^{(i)}\)表示数据集第\(i\)个数据的第\(j\)个属性取值,数据集一共有\(m\)个数据,\(n\)个属性(特征)。模型定义为:$ f(x) = {w_0} + {w_1}{x_1} + {w_2}{x_2} + \ldots + {w_n}{x_n}$ 。使用矩阵来表示就是\(f(x) = WX\) 。
其中: \(W = \left[ {\begin{array}{*{20}{c}} {{w_0}}&{{w_1}}& \ldots &{{w_n}} \end{array}} \right]\)是所要求得一系列参数,\(X = \left[ {\begin{array}{*{20}{c}} 1&1& \ldots &1\\ {x_1^{(1)}}&{x_1^{(2)}}& \ldots &{x_1^{(m)}}\\ \ldots & \ldots & \ldots & \ldots \\ {x_n^{(1)}}&{x_n^{(2)}}& \ldots &{x_n^{(m)}} \end{array}} \right]\)是输入的数据矩阵,因为考虑\({w_0}\)常数项,所以在\(X\)第一行加上了一行1。 \(X\)的一列可以看做一个完整的输入数据,\(n\)代表一个数据有\(n\)个属性(特征),\(m\)代表一共是\(m\)个数据。数据集标签为\(Y\)。线性回归模型的目标就是找到一系列参数\(w\)来使得\(f(x) = WX\)尽可能地贴近\(Y\)。
\(\;\;\;\;\;\)线性回归使用均方误差作为损失函数,使用均方误差最小化目标函数的方法称为最小二乘法。使用均方误差的原因:有十分好的几何意义,对应了常用的欧式距离。在线性回归中,就是找到一个直线,使得所有样本到直线的欧式距离最小。损失代价函数定义为:
\(\;\;\;\;\;\)逻辑回归的模型本质上是一个线性回归模型,逻辑回归都是以线性回归为理论支持的。而逻辑回归通过sigmoid非线性变换,将预测值限定在[0,1]之间,以概率的形式进行二分类预测。下面介绍逻辑回归中sigmoid函数对应的逻辑斯蒂分布。
逻辑斯蒂分布
\(\;\;\;\;\;\)设X是连续随机变量,X服从逻辑斯蒂分布是指X具有下列的分布函数和密度函数:
\(\;\;\;\;\;\)上式中,\(\mu\) 表示位置参数,\(\gamma>0\)为形状参数。
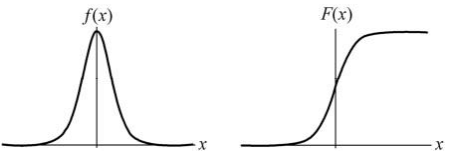
\(\;\;\;\;\;\)如图所示,逻辑斯谛分布函数是一条 S 形曲线。该曲线以点 \((\mu ,\frac{1}{2})\)为中心对称,而密度函数关于纵轴对称,最大值为\(\frac{{{e^{\mu /\gamma }}}}{{\gamma {{(1 + {e^{\mu /\gamma }})}^2}}}\),当\(\mu = 0,\gamma = 1\)时取\(\frac{1}{4}\)。
二项逻辑回归模型
\(\;\;\;\;\;\)之前说到,逻辑回归是一种二分类模型,由条件概率分布\(P(Y|X)\)表示,形式就是参数化的逻辑斯蒂分布。这里的自变量\(X\)取值为实数,而因变量\(Y\)为0或者1。二项LR的条件概率如下:
\(\;\;\;\;\;\)一个事件的几率(odds):指该事件发生与不发生的概率比值,若事件发生概率为\(p\),那么事件发生的几率就是
\(\;\;\;\;\;\)那么该事件的对数几率(log odds或者logit)就是:
\(\;\;\;\;\;\)那么,对逻辑回归而言,\(Y=1\)的对数几率就是:
\(\;\;\;\;\;\)也就是说,输出\(Y=1\)的对数几率是由输入\(x\)的线性函数表示的模型,所以逻辑回归同样被认为是线性模型(广义线性模型)。一般在逻辑回归类别判决中选择0.5作为阈值,实际应用时特定的情况可以选择不同阈值,如果对正例的判别准确性要求高,可以选择阈值大一些,对正例的召回要求高,则可以选择阈值小一些。
模型参数优化
\(\;\;\;\;\;\)模型的数学形式确定后,剩下就是如何去求解模型中的参数。统计学中常用的一种方法是最大似然估计,即找到一组参数,使得在这组参数下,数据的似然度(概率)越大。
\(\;\;\;\;\;\)设\(P(Y = 1|x) = \pi (x)\),则\(P(Y = 0|x) = 1 - \pi (x)\),在逻辑回归模型中,似然度可表示为:
取对数可以得到对数似然度:
\(\;\;\;\;\;\)参数优化则变为求一组\(w\)使得对数似然度最大。另一方面,在机器学习领域,我们更经常遇到的是损失函数的概念,其衡量的是模型预测错误的程度。常用的损失函数有0-1损失,log损失,hinge损失等。其中log损失在单个数据点上的定义为$ - y\log p(y|x) - (1 - y)\log (1 - p(y|x))$。
\(\;\;\;\;\;\)如果取整个数据集上的平均log损失,我们可以得到
\(\;\;\;\;\;\)即在逻辑回归模型中,我们最大化似然函数和最小化log损失函数实际上是等价的。对于该优化问题,存在多种求解方法,这里以梯度下降的为例说明。梯度下降(Gradient Descent)又叫作最速梯度下降,是一种迭代求解的方法,通过在每一步选取使目标函数变化最快的一个方向调整参数的值来逼近最优值。基本步骤如下:
- 选择下降方向(梯度方向,\(\nabla J(w)\))
- 选择步长,更新参数\({w^i} = {w^{i - 1}} - {\alpha ^i}\nabla J({w^{i - 1}})\)
- 重复以上两步直到满足终止条件
其中损失函数的梯度计算方法为:
\(\;\;\;\;\;\)沿梯度负方向选择一个较小的步长可以保证损失函数是减小的,另一方面,逻辑回归的损失函数是凸函数(加入正则项后是严格凸函数),可以保证我们找到的局部最优值同时是全局最优。此外,常用的凸优化的方法都可以用于求解该问题。例如共轭梯度下降,牛顿法等。
为什么损失函数不用最小二乘
\(\;\;\;\;\;\)在逻辑回归中平方损失在训练的时候会出现一定的问题,当预测值与真实值之间的差距过大时,这时候参数的调整就需要变大,但是如果使用平方损失,训练的时候可能看到的情况是预测值和真实值之间的差距越大,参数调整的越小,训练的越慢。如果使用平方损失作为损失函数,损失函数如下:
\(\;\;\;\;\;\)其中\(y\)表示真实值,\(f(x)\) 表示预测值。对参数求梯度:
\(\;\;\;\;\;\)由此可以看出,参数\(w\)对应梯度除了跟真实值与预测值之间的差距有关,还和sigmoid函数梯度相关,当结果落在sigmoid函数两端时,即使真实值和预测值差距很大,梯度接近于0,参数调整速度缓慢,与我们的期望不符合。而使用交叉熵损失在更新参数的时候,当误差越大时,梯度也就越大,参数调整也能更大更快。
非线性分类
\(\;\;\;\;\;\)逻辑回归本质上是一个线性模型,但是,这不意味着只有线性可分的数据能通过LR求解,实际上,我们可以通过特征变换的方式把低维空间转换到高维空间,而在低维空间不可分的数据,到高维空间中线性可分的几率会高一些。下面两个图的对比说明了线性分类曲线和非线性分类曲线(通过特征映射)。
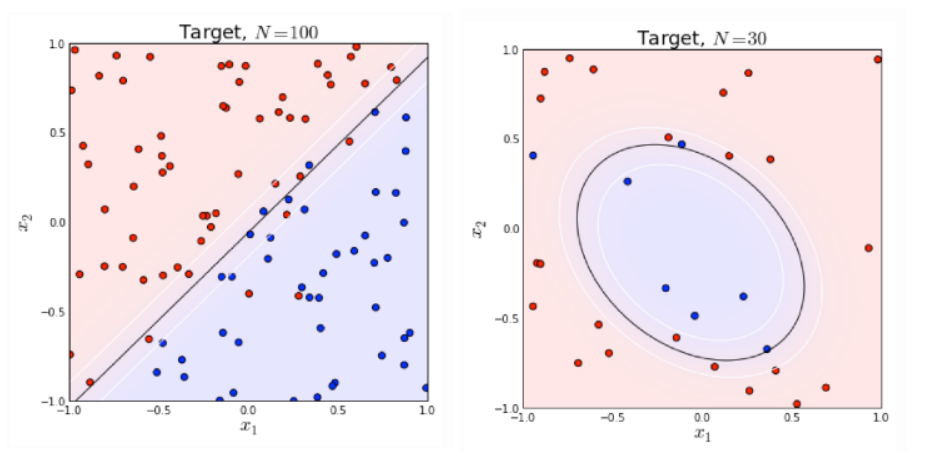
\(\;\;\;\;\;\)左图是一个线性可分的数据集,右图在原始空间中线性不可分,但是在特征转换 \([x_1,x_2]=>[x_1,x_2,x_1^2,\)\(x_2^2,x_1x_2]\)后的空间是线性可分的,对应的原始空间中分类边界为一条类椭圆曲线。
正则化
\(\;\;\;\;\;\)当模型的参数过多时,很容易遇到过拟合的问题。这时就需要有一种方法来控制模型的复杂度,典型的做法在优化目标中加入正则项,通过惩罚过大的参数来防止过拟合:
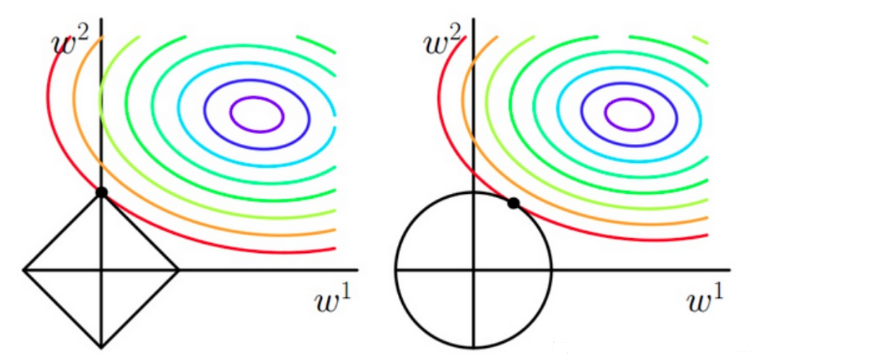
\(\;\;\;\;\;\)一般情况下,取\(p=1\)或\(p=2\),分别对应L1,L2正则化,两者的区别可以从下图中看出来,L1正则化(左图)倾向于使参数变为0,因此能产生稀疏解。实际应用时,由于我们数据的维度可能非常高,L1正则化因为能产生稀疏解,使用的更为广泛一些。
多分类(softmax)
\(\;\;\;\;\;\)如果\(y\)不是在[0,1]中取值,而是在\(K\)个类别中取值,这时问题就变为一个多分类问题。有两种方式可以出处理该类问题:一种是我们对每个类别训练一个二元分类器(One-vs-all),当\(K\)个类别不是互斥的时候,比如用户会购买哪种品类,这种方法是合适的。如果\(K\)个类别是互斥的,即$ y=i$ 的时候意味着 \(y\)不能取其他的值,比如用户的年龄段,这种情况下 Softmax 回归更合适一些。Softmax 回归是直接对逻辑回归在多分类的推广,相应的模型也可以叫做多元逻辑回归(Multinomial Logistic Regression)。模型通过 softmax 函数来对概率建模,具体形式如下:
\(\;\;\;\;\;\)而决策函数为:\({y^ * } = {\rm{argma}}{{\rm{x}}_i}P(y = i|x,w )\)
\(\;\;\;\;\;\)对应的损失函数为:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号