从零开始教你写一个MLIR Pass
本博客原文地址:https://www.cnblogs.com/BobHuang/p/18249482
笔者在去年写了一篇LLVM Pass的教程,之后从事MLIR的开发近1年了,写点教程回馈下社区。
MLIR(Multi-Level Intermediate Representation,多层中间表示)是LLVM之父(博士期间开发的LLVM)的Chris Lattner带领团队开发的编译器基础设施,其增强了 LLVM IR表达能力。入门这个编译器工具最好还是看其官方文档和官方教程,我在此记录下我的理解。你懂MLIR的前世今生吗,Chris Lattner为你娓娓道来
本教程采用 LLVM 18.1.0版本,commit id是461274b
章节二单文件源码见Github文件。章节三项目源码见Github文件,单次加Pass见commit。
一、什么是MLIR
MLIR相对LLVM IR在单条语句上包含了更多的信息,抽象层级更高,而且也有不同的dialect(方言),代表不同的抽象层级,不断得lower也可以到LLVM IR,下图为MLIR的dialect概览,来源 [RFC] Updated MLIR Dialect Overview Diagram
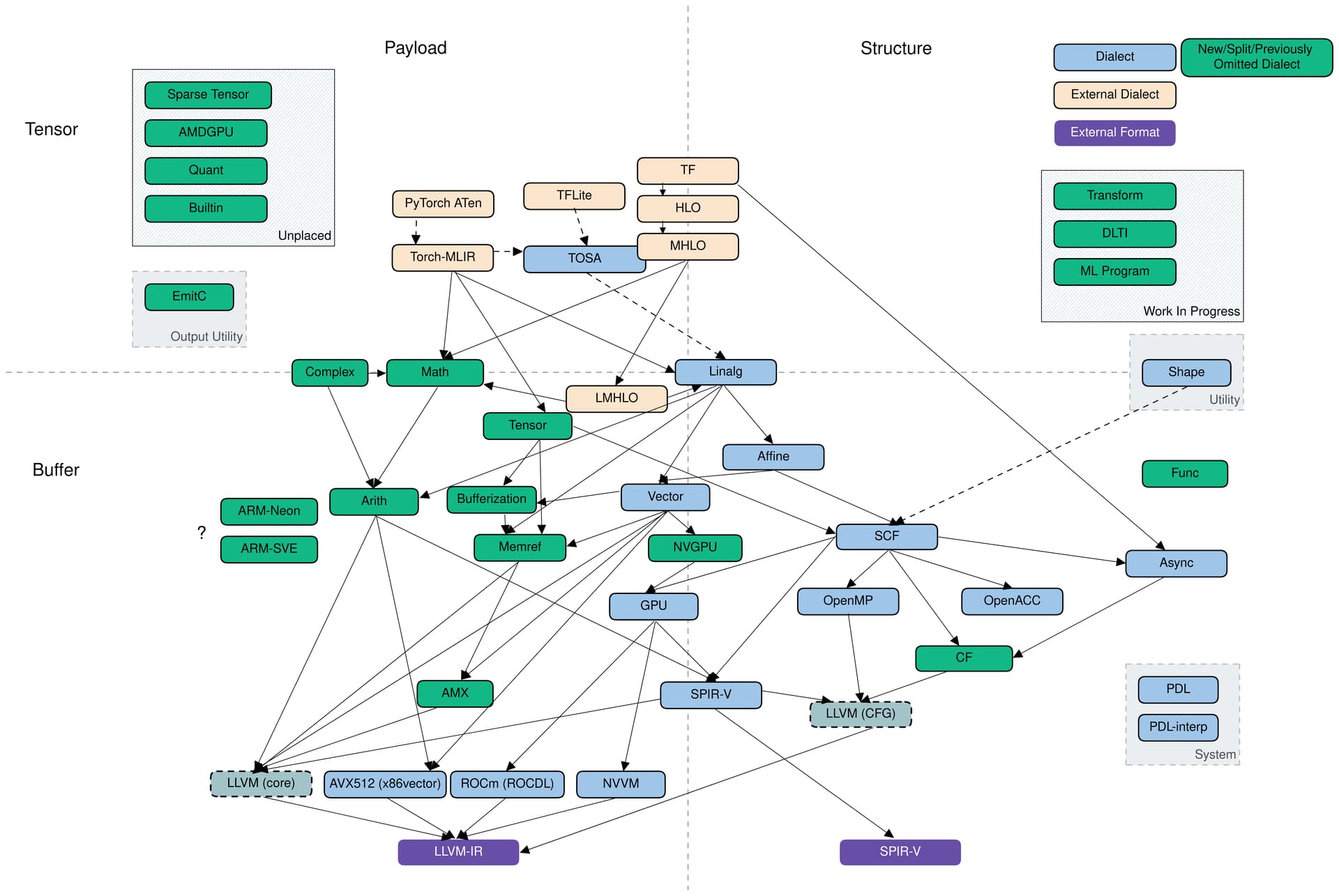
比如利用pytorch神经网络的MLIR可能包含以下dialect
Tensor 是一块带 shape 的指针:使用 tensor dialect
简单的 elementwise 加减乘除:使用 arith dialect
复杂的 log、exp 等运算:使用 math dialect
矩阵线性代数运算:使用 linalg dialect
可能有一些控制流:使用 scf dialect
整个网络是一个函数:使用 func dialect
处理循环嵌套,实现了循环展开、多面体变换等一些算法:使用 affine dialect(事实上Polyhedral多面体模型工业上并不用)
ftynse大佬写过Codegen Dialect Overview,其中也介绍了各种dialect,可以自行翻阅。
值得一提的是tosa dialect,它是 tosa spec 的实现,这是ARM公司牵头的标准,目标是硬件厂商按照规范实现算子,模型厂商按照规范使用算子,这样模型就容易部署在不同类型的设备上。
1、MLIR dialect 降级展示
使用torch-mlir我们可以对一个仅含liner算子的model进行处理,在torch dialect如下所示
module attributes {torch.debug_module_name = "TinyModel"} {
func.func @forward(%arg0: !torch.vtensor<[1,2,3],f32>) -> !torch.vtensor<[1,2,4],f32> {
%0 = torch.vtensor.literal(dense<[-0.200281888, -0.136583954, 0.572506905, 0.346645296]> : tensor<4xf32>) : !torch.vtensor<[4],f32>
%1 = torch.vtensor.literal(dense<[[-0.00492882729, 0.24626255, -0.361437857], [-0.314372569, -0.0777031779, -0.231338859], [-0.452323347, -0.235514581, 0.42364943], [0.191288948, -0.108519524, 0.219343841]]> : tensor<4x3xf32>) : !torch.vtensor<[4,3],f32>
%int0 = torch.constant.int 0
%int1 = torch.constant.int 1
%2 = torch.aten.transpose.int %1, %int0, %int1 : !torch.vtensor<[4,3],f32>, !torch.int, !torch.int -> !torch.vtensor<[3,4],f32>
%3 = torch.aten.matmul %arg0, %2 : !torch.vtensor<[1,2,3],f32>, !torch.vtensor<[3,4],f32> -> !torch.vtensor<[1,2,4],f32>
%4 = torch.aten.add.Tensor %3, %0, %int1 : !torch.vtensor<[1,2,4],f32>, !torch.vtensor<[4],f32>, !torch.int -> !torch.vtensor<[1,2,4],f32>
return %4 : !torch.vtensor<[1,2,4],f32>
}
}
liner没有了是因为接到了aten层面,Pytorch的底层C++ Tensor算子库。设置torchscript.compile的输出参数output_type="linalg-on-tensors"可以进一步转换为linalg dialect的表示
#map = affine_map<(d0, d1) -> (d0, d1)>
#map1 = affine_map<(d0, d1) -> (d1, d0)>
#map2 = affine_map<(d0, d1, d2) -> (0, d1, d2)>
#map3 = affine_map<(d0, d1, d2) -> (d0, d1, d2)>
#map4 = affine_map<(d0, d1, d2) -> (d1, d2)>
#map5 = affine_map<(d0, d1, d2) -> (d2)>
module attributes {torch.debug_module_name = "TinyModel"} {
ml_program.global private mutable @global_seed(dense<0> : tensor<i64>) : tensor<i64>
func.func @forward(%arg0: tensor<1x2x3xf32>) -> tensor<1x2x4xf32> {
%cst = arith.constant dense<[[-0.00492882729, 0.24626255, -0.361437857], [-0.314372569, -0.0777031779, -0.231338859], [-0.452323347, -0.235514581, 0.42364943], [0.191288948, -0.108519524, 0.219343841]]> : tensor<4x3xf32>
%cst_0 = arith.constant 0.000000e+00 : f32
%cst_1 = arith.constant dense<[-0.200281888, -0.136583954, 0.572506905, 0.346645296]> : tensor<4xf32>
%0 = tensor.empty() : tensor<3x4xf32>
%1 = linalg.generic {indexing_maps = [#map, #map1], iterator_types = ["parallel", "parallel"]} ins(%cst : tensor<4x3xf32>) outs(%0 : tensor<3x4xf32>) {
^bb0(%in: f32, %out: f32):
linalg.yield %in : f32
} -> tensor<3x4xf32>
%2 = tensor.empty() : tensor<1x2x3xf32>
%3 = linalg.generic {indexing_maps = [#map2, #map3], iterator_types = ["parallel", "parallel", "parallel"]} ins(%arg0 : tensor<1x2x3xf32>) outs(%2 : tensor<1x2x3xf32>) {
^bb0(%in: f32, %out: f32):
linalg.yield %in : f32
} -> tensor<1x2x3xf32>
%4 = tensor.empty() : tensor<1x3x4xf32>
%5 = linalg.generic {indexing_maps = [#map4, #map3], iterator_types = ["parallel", "parallel", "parallel"]} ins(%1 : tensor<3x4xf32>) outs(%4 : tensor<1x3x4xf32>) {
^bb0(%in: f32, %out: f32):
linalg.yield %in : f32
} -> tensor<1x3x4xf32>
%6 = tensor.empty() : tensor<1x2x4xf32>
%7 = linalg.fill ins(%cst_0 : f32) outs(%6 : tensor<1x2x4xf32>) -> tensor<1x2x4xf32>
%8 = linalg.batch_matmul ins(%3, %5 : tensor<1x2x3xf32>, tensor<1x3x4xf32>) outs(%7 : tensor<1x2x4xf32>) -> tensor<1x2x4xf32>
%9 = linalg.generic {indexing_maps = [#map2, #map5, #map3], iterator_types = ["parallel", "parallel", "parallel"]} ins(%8, %cst_1 : tensor<1x2x4xf32>, tensor<4xf32>) outs(%6 : tensor<1x2x4xf32>) {
^bb0(%in: f32, %in_2: f32, %out: f32):
%10 = arith.addf %in, %in_2 : f32
linalg.yield %10 : f32
} -> tensor<1x2x4xf32>
return %9 : tensor<1x2x4xf32>
}
}
以上我们可以看到通过 torch-mlir完成了Pytorch Aten dialect到Torch-MLIR dialect再到linalg dialect的转换,当然其内部是很多个Pass,最后我们比较关心的是linalg.batch_matmul,我们可以将其进一步降级到affine dialect。可以使用mlir-opt并使用--tensor-bufferize --linalg-bufferize --convert-linalg-to-affine-loops选项,得到如下代码,也就是\(C_{ij} = \sum_{k=1}^{n} A_{ik} \cdot B_{kj}\),并多了一重循环为batch。
%cst_0 = arith.constant 0.000000e+00 : f32
affine.for %arg1 = 0 to 1 {
affine.for %arg2 = 0 to 2 {
affine.for %arg3 = 0 to 4 {
affine.store %cst_0, %alloc_4[%arg1, %arg2, %arg3] : memref<1x2x4xf32>
}
}
}
%alloc_5 = memref.alloc() {alignment = 64 : i64} : memref<1x2x4xf32>
memref.copy %alloc_4, %alloc_5 : memref<1x2x4xf32> to memref<1x2x4xf32>
affine.for %arg1 = 0 to 1 {
affine.for %arg2 = 0 to 2 {
affine.for %arg3 = 0 to 4 {
affine.for %arg4 = 0 to 3 {
%4 = affine.load %alloc_2[%arg1, %arg2, %arg4] : memref<1x2x3xf32>
%5 = affine.load %alloc_3[%arg1, %arg4, %arg3] : memref<1x3x4xf32>
%6 = affine.load %alloc_5[%arg1, %arg2, %arg3] : memref<1x2x4xf32>
%7 = arith.mulf %4, %5 : f32
%8 = arith.addf %6, %7 : f32
affine.store %8, %alloc_5[%arg1, %arg2, %arg3] : memref<1x2x4xf32>
}
}
}
}
*2、MLIR vs LLVM IR
有一篇对比的文章非常出名 编译器与IR的思考: LLVM IR,SPIR-V到MLIR
之前LLVM Pass的大多数输入都是LLVM IR,其抽象结构如下图所示,其最小粒度为ISD,这个中间表示粒度为指令,各个后端针对特殊节点会有lower。

上文linalg.batch_matmul在affine dialect表示等价于以下C代码
#define BATCH 1
#define N 2
#define M 3
#define K 4
void matmul(float A[BATCH][N][M], float B[BATCH][M][K], float C[BATCH][N][K]) {
// Polygeist的pragma,会优先生成affine
#pragma scop
for (int b = 0; b < BATCH; b++) {
for (int i = 0; i < N; i++) {
for (int j = 0; j < K; j++) {
C[b][i][j] = 0.0;
}
}
}
for (int b = 0; b < BATCH; b++) {
for (int i = 0; i < N; i++) {
for (int j = 0; j < K; j++) {
for (int k = 0; k < M; k++) {
C[b][i][j] += A[b][i][k] * B[b][k][j];
}
}
}
}
// Polygeist的pragma,会优先生成affine
#pragma endscop
}
以上C代码我们可以通过Polygeist的cgeist工具获取相似的MLIR,我们对最外层循环次数为1的循环也很好优化
module attributes {} {
func.func @matmul(%arg0: memref<1x2x3xf32>, %arg1: memref<1x3x4xf32>, %arg2: memref<1x2x4xf32>) attributes {llvm.linkage = #llvm.linkage<external>} {
%cst = arith.constant 0.000000e+00 : f32
affine.for %arg3 = 0 to 1 {
affine.for %arg4 = 0 to 2 {
affine.for %arg5 = 0 to 4 {
affine.store %cst, %arg2[%arg3, %arg4, %arg5] : memref<1x2x4xf32>
}
}
}
affine.for %arg3 = 0 to 1 {
affine.for %arg4 = 0 to 2 {
affine.for %arg5 = 0 to 4 {
affine.for %arg6 = 0 to 3 {
%0 = affine.load %arg0[%arg3, %arg4, %arg6] : memref<1x2x3xf32>
%1 = affine.load %arg1[%arg3, %arg6, %arg5] : memref<1x3x4xf32>
%2 = arith.mulf %0, %1 : f32
%3 = affine.load %arg2[%arg3, %arg4, %arg5] : memref<1x2x4xf32>
%4 = arith.addf %3, %2 : f32
affine.store %4, %arg2[%arg3, %arg4, %arg5] : memref<1x2x4xf32>
}
}
}
}
return
}
}
affine dialect会比较接近我们的C代码,方便做一些优化,而下面通过clang得到的LLVM IR由于粒度过细而处理更麻烦
点击展开代码
; ModuleID = 'test/matmul.c'
source_filename = "test/matmul.c"
target datalayout = "e-m:o-p270:32:32-p271:32:32-p272:64:64-i64:64-i128:128-f80:128-n8:16:32:64-S128"
target triple = "x86_64-apple"
; Function Attrs: noinline nounwind optnone ssp uwtable
define void @matmul(ptr noundef %A, ptr noundef %B, ptr noundef %C) #0 {
entry:
%A.addr = alloca ptr, align 8
%B.addr = alloca ptr, align 8
%C.addr = alloca ptr, align 8
%b = alloca i32, align 4
%i = alloca i32, align 4
%j = alloca i32, align 4
%b17 = alloca i32, align 4
%i21 = alloca i32, align 4
%j25 = alloca i32, align 4
%k = alloca i32, align 4
store ptr %A, ptr %A.addr, align 8
store ptr %B, ptr %B.addr, align 8
store ptr %C, ptr %C.addr, align 8
store i32 0, ptr %b, align 4
br label %for.cond
for.cond: ; preds = %for.inc14, %entry
%0 = load i32, ptr %b, align 4
%cmp = icmp slt i32 %0, 1
br i1 %cmp, label %for.body, label %for.end16
for.body: ; preds = %for.cond
store i32 0, ptr %i, align 4
br label %for.cond1
for.cond1: ; preds = %for.inc11, %for.body
%1 = load i32, ptr %i, align 4
%cmp2 = icmp slt i32 %1, 2
br i1 %cmp2, label %for.body3, label %for.end13
for.body3: ; preds = %for.cond1
store i32 0, ptr %j, align 4
br label %for.cond4
for.cond4: ; preds = %for.inc, %for.body3
%2 = load i32, ptr %j, align 4
%cmp5 = icmp slt i32 %2, 4
br i1 %cmp5, label %for.body6, label %for.end
for.body6: ; preds = %for.cond4
%3 = load ptr, ptr %C.addr, align 8
%4 = load i32, ptr %b, align 4
%idxprom = sext i32 %4 to i64
%arrayidx = getelementptr inbounds [2 x [4 x float]], ptr %3, i64 %idxprom
%5 = load i32, ptr %i, align 4
%idxprom7 = sext i32 %5 to i64
%arrayidx8 = getelementptr inbounds [2 x [4 x float]], ptr %arrayidx, i64 0, i64 %idxprom7
%6 = load i32, ptr %j, align 4
%idxprom9 = sext i32 %6 to i64
%arrayidx10 = getelementptr inbounds [4 x float], ptr %arrayidx8, i64 0, i64 %idxprom9
store float 0.000000e+00, ptr %arrayidx10, align 4
br label %for.inc
for.inc: ; preds = %for.body6
%7 = load i32, ptr %j, align 4
%inc = add nsw i32 %7, 1
store i32 %inc, ptr %j, align 4
br label %for.cond4, !llvm.loop !5
for.end: ; preds = %for.cond4
br label %for.inc11
for.inc11: ; preds = %for.end
%8 = load i32, ptr %i, align 4
%inc12 = add nsw i32 %8, 1
store i32 %inc12, ptr %i, align 4
br label %for.cond1, !llvm.loop !7
for.end13: ; preds = %for.cond1
br label %for.inc14
for.inc14: ; preds = %for.end13
%9 = load i32, ptr %b, align 4
%inc15 = add nsw i32 %9, 1
store i32 %inc15, ptr %b, align 4
br label %for.cond, !llvm.loop !8
for.end16: ; preds = %for.cond
store i32 0, ptr %b17, align 4
br label %for.cond18
for.cond18: ; preds = %for.inc59, %for.end16
%10 = load i32, ptr %b17, align 4
%cmp19 = icmp slt i32 %10, 1
br i1 %cmp19, label %for.body20, label %for.end61
for.body20: ; preds = %for.cond18
store i32 0, ptr %i21, align 4
br label %for.cond22
for.cond22: ; preds = %for.inc56, %for.body20
%11 = load i32, ptr %i21, align 4
%cmp23 = icmp slt i32 %11, 2
br i1 %cmp23, label %for.body24, label %for.end58
for.body24: ; preds = %for.cond22
store i32 0, ptr %j25, align 4
br label %for.cond26
for.cond26: ; preds = %for.inc53, %for.body24
%12 = load i32, ptr %j25, align 4
%cmp27 = icmp slt i32 %12, 4
br i1 %cmp27, label %for.body28, label %for.end55
for.body28: ; preds = %for.cond26
store i32 0, ptr %k, align 4
br label %for.cond29
for.cond29: ; preds = %for.inc50, %for.body28
%13 = load i32, ptr %k, align 4
%cmp30 = icmp slt i32 %13, 3
br i1 %cmp30, label %for.body31, label %for.end52
for.body31: ; preds = %for.cond29
%14 = load ptr, ptr %A.addr, align 8
%15 = load i32, ptr %b17, align 4
%idxprom32 = sext i32 %15 to i64
%arrayidx33 = getelementptr inbounds [2 x [3 x float]], ptr %14, i64 %idxprom32
%16 = load i32, ptr %i21, align 4
%idxprom34 = sext i32 %16 to i64
%arrayidx35 = getelementptr inbounds [2 x [3 x float]], ptr %arrayidx33, i64 0, i64 %idxprom34
%17 = load i32, ptr %k, align 4
%idxprom36 = sext i32 %17 to i64
%arrayidx37 = getelementptr inbounds [3 x float], ptr %arrayidx35, i64 0, i64 %idxprom36
%18 = load float, ptr %arrayidx37, align 4
%19 = load ptr, ptr %B.addr, align 8
%20 = load i32, ptr %b17, align 4
%idxprom38 = sext i32 %20 to i64
%arrayidx39 = getelementptr inbounds [3 x [4 x float]], ptr %19, i64 %idxprom38
%21 = load i32, ptr %k, align 4
%idxprom40 = sext i32 %21 to i64
%arrayidx41 = getelementptr inbounds [3 x [4 x float]], ptr %arrayidx39, i64 0, i64 %idxprom40
%22 = load i32, ptr %j25, align 4
%idxprom42 = sext i32 %22 to i64
%arrayidx43 = getelementptr inbounds [4 x float], ptr %arrayidx41, i64 0, i64 %idxprom42
%23 = load float, ptr %arrayidx43, align 4
%24 = load ptr, ptr %C.addr, align 8
%25 = load i32, ptr %b17, align 4
%idxprom44 = sext i32 %25 to i64
%arrayidx45 = getelementptr inbounds [2 x [4 x float]], ptr %24, i64 %idxprom44
%26 = load i32, ptr %i21, align 4
%idxprom46 = sext i32 %26 to i64
%arrayidx47 = getelementptr inbounds [2 x [4 x float]], ptr %arrayidx45, i64 0, i64 %idxprom46
%27 = load i32, ptr %j25, align 4
%idxprom48 = sext i32 %27 to i64
%arrayidx49 = getelementptr inbounds [4 x float], ptr %arrayidx47, i64 0, i64 %idxprom48
%28 = load float, ptr %arrayidx49, align 4
%29 = call float @llvm.fmuladd.f32(float %18, float %23, float %28)
store float %29, ptr %arrayidx49, align 4
br label %for.inc50
for.inc50: ; preds = %for.body31
%30 = load i32, ptr %k, align 4
%inc51 = add nsw i32 %30, 1
store i32 %inc51, ptr %k, align 4
br label %for.cond29, !llvm.loop !9
for.end52: ; preds = %for.cond29
br label %for.inc53
for.inc53: ; preds = %for.end52
%31 = load i32, ptr %j25, align 4
%inc54 = add nsw i32 %31, 1
store i32 %inc54, ptr %j25, align 4
br label %for.cond26, !llvm.loop !10
for.end55: ; preds = %for.cond26
br label %for.inc56
for.inc56: ; preds = %for.end55
%32 = load i32, ptr %i21, align 4
%inc57 = add nsw i32 %32, 1
store i32 %inc57, ptr %i21, align 4
br label %for.cond22, !llvm.loop !11
for.end58: ; preds = %for.cond22
br label %for.inc59
for.inc59: ; preds = %for.end58
%33 = load i32, ptr %b17, align 4
%inc60 = add nsw i32 %33, 1
store i32 %inc60, ptr %b17, align 4
br label %for.cond18, !llvm.loop !12
for.end61: ; preds = %for.cond18
ret void
}
; Function Attrs: nocallback nofree nosync nounwind speculatable willreturn memory(none)
declare float @llvm.fmuladd.f32(float, float, float) #1
attributes #0 = { noinline nounwind optnone ssp uwtable "frame-pointer"="all" "min-legal-vector-width"="0" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="penryn" "target-features"="+cmov,+cx16,+cx8,+fxsr,+mmx,+sahf,+sse,+sse2,+sse3,+sse4.1,+ssse3,+x87" "tune-cpu"="generic" }
attributes #1 = { nocallback nofree nosync nounwind speculatable willreturn memory(none) }
!llvm.module.flags = !{!0, !1, !2, !3}
!llvm.ident = !{!4}
!0 = !{i32 1, !"wchar_size", i32 4}
!1 = !{i32 8, !"PIC Level", i32 2}
!2 = !{i32 7, !"uwtable", i32 2}
!3 = !{i32 7, !"frame-pointer", i32 2}
!4 = !{!"clang version 18.1.0rc"}
!5 = distinct !{!5, !6}
!6 = !{!"llvm.loop.mustprogress"}
!7 = distinct !{!7, !6}
!8 = distinct !{!8, !6}
!9 = distinct !{!9, !6}
!10 = distinct !{!10, !6}
!11 = distinct !{!11, !6}
!12 = distinct !{!12, !6}
LLVM IR抽象是简洁的,非常接近硬件,但是对编译器开发者来说上手很难。MLIR增加了各种各样的抽象,对编译器开发者非常友好,但是抽象是有代价的,靠人力去维护屎山,所幸现在软件人才都要溢出了,而且现在对AI大模型的优化投入很疯狂,AI编译器的需求是必然。甚至MLIR还在EDA有应用CIRCT,chisel代码到Verilog代码的转换,非常有意思。
3、编译MLIR
我们先编译MLIR,下载好源码可以使用如下命令编译,为了节省内存和编译时间编译了Release版,如需要调试请设置-DCMAKE_BUILD_TYPE=Debug
mkdir build; cd build
cmake -G Ninja ../llvm \
-DLLVM_ENABLE_PROJECTS=mlir \
-DLLVM_BUILD_EXAMPLES=ON \
-DLLVM_TARGETS_TO_BUILD="Native;NVPTX;AMDGPU" \
-DCMAKE_BUILD_TYPE=Release \
-DLLVM_ENABLE_ASSERTIONS=ON
ninja
build/bin下常用的工具有mlir-opt、mlir-cpu-runner和mlir-translate。
mlir-opt 包含了MLIR项目中各种优化和转换,通过不同Pass选项可以运行不同的Pass。
mlir-cpu-runner 是官方的JIT即时编译引擎,可以用来对优化和转换的测试,确保每个Pass都正确,写脚本也可以很方便找到那个错误的Pass,具体使用方式可以参考测试文件。
mlir-translate 用于在 MLIR 和其他表示之间进行转换。
4、MLIR 基本结构
这部分参考了官方教程,有能力直接看原文即可。
MLIR主要由模块 (Module)、区域 (Region)、基本块 (Block)、操作 (Operation)组成,其中关系为Operation可以包含Region,Region包含Block,Block包含Operation。IR结构为有向无环图(DAG),MLIR的Region嵌套为树形结构。
每个Operation都是由dialect.type构成,比如下面的MLIR示例,包含了2个dialect,分别是builtin和dialect。builtin下有类型为module的Operation,dialect下有op1, op2, innerop1, innerop2, innerop3, innerop4, innerop5, innerop6和innerop7的Operation。
"builtin.module"() ( {
%0:4 = "dialect.op1"() {"attribute name" = 42 : i32} : () -> (i1, i16, i32, i64)
"dialect.op2"() ( {
"dialect.innerop1"(%0#0, %0#1) : (i1, i16) -> ()
}, {
"dialect.innerop2"() : () -> ()
"dialect.innerop3"(%0#0, %0#2, %0#3)[^bb1, ^bb2] : (i1, i32, i64) -> ()
^bb1(%1: i32): // pred: ^bb0
"dialect.innerop4"() : () -> ()
"dialect.innerop5"() : () -> ()
^bb2(%2: i64): // pred: ^bb0
"dialect.innerop6"() : () -> ()
"dialect.innerop7"() : () -> ()
}) {"other attribute" = 42 : i64} : () -> ()
}) : () -> ()
首行"builtin.module"() ( { 中的()表示输入,( {表示Region。尾行}) : () -> ()中的})与首行( {对应,:后() -> ()描述的是从空到空,"builtin.module"没有参数也没有结果。另外最外层一般均是builtin.module,作为 IR的根。
第2行%0:4 = "dialect.op1"() {"attribute name" = 42 : i32} : () -> (i1, i16, i32, i64),= 左边的%0为"dialect.op1"的结果值标识符,:4表示有4个,分别是%0#0, %0#1, %0#2 和 %0#3。()表示输入为空,{"attribute name" = 42 : i32}表示存在一个属性,名字是"attribute name",值为i32类型的42,attribute可以理解为编译器常量,有的时候我们要塞一些信息补充下这个Operation,其是个键值对,甚至有些op的必要信息本质也是Attr,比如函数的sym_name(函数名)、function_type(参数类型)。:后描述的就是类型的描述了,从空输入到产生一个i1, i16, i32和i64类型的输出,分别对应%0#0,%0#1, %0#2 和 %0#3。
第3行"dialect.op2"() ( {还是空输入,且包含了2个Region,两个Region都用了一对{}标记,并使用了,隔开。
第1个Region的"dialect.innerop1"使用了%0#0, %0#1作为输入,其类型和第2行%0:4 = "dialect.op1"() {"attribute name" = 42 : i32} : () -> (i1, i16, i32, i64)对得上的。
第2个Region比较复杂,其包含了3个Block。第一个Block包含了dialect.innerop2和dialect.innerop3,"dialect.innerop3"有3个输入, [^bb1, ^bb2]代表着后继列表,所以dialect.innerop3描述的是后继Block的关系,这个是一个含控制流的Operation。第二个Block名字为^bb1且含1参数且参数类型为i32,第三个Block同理。
我们可以用上文编译的mlir-opt运行出上述MLIR的结构关系,命令为 build/bin/mlir-opt -test-print-nesting -allow-unregistered-dialect mlir/test/IR/print-ir-nesting.mlir -o test.mlir,结果如下所示
visiting op: 'builtin.module' with 0 operands and 0 results
1 nested regions:
Region with 1 blocks:
Block with 0 arguments, 0 successors, and 2 operations
visiting op: 'dialect.op1' with 0 operands and 4 results
1 attributes:
- 'attribute name' : '42 : i32'
0 nested regions:
visiting op: 'dialect.op2' with 0 operands and 0 results
2 nested regions:
Region with 1 blocks:
Block with 0 arguments, 0 successors, and 1 operations
visiting op: 'dialect.innerop1' with 2 operands and 0 results
0 nested regions:
Region with 3 blocks:
Block with 0 arguments, 2 successors, and 2 operations
visiting op: 'dialect.innerop2' with 0 operands and 0 results
0 nested regions:
visiting op: 'dialect.innerop3' with 3 operands and 0 results
0 nested regions:
Block with 1 arguments, 0 successors, and 2 operations
visiting op: 'dialect.innerop4' with 0 operands and 0 results
0 nested regions:
visiting op: 'dialect.innerop5' with 0 operands and 0 results
0 nested regions:
Block with 1 arguments, 0 successors, and 2 operations
visiting op: 'dialect.innerop6' with 0 operands and 0 results
0 nested regions:
visiting op: 'dialect.innerop7' with 0 operands and 0 results
0 nested regions:
你也可以尝试修改mlir/test/IR/print-ir-nesting.mlir让其产生不同的输出,另外我们调用的Pass文件在mlir/test/lib/IR/TestPrintNesting.cpp,有兴趣可以看下。
这个Pass遍历Operation用的是for (Region ®ion : op->getRegions()), for (Block &block : region.getBlocks())和for (Operation &op : block.getOperations()),也很清楚得描述了Region,Block和Operation的关系,另外MLIR还暴露了walk()帮助我们去遍历,比如下面的使用方法。
// 按照后序遍历顺序遍历所有Region,Block和Operation
getOperation().walk([&](mlir::Operation *op) {
// 可以对op进行处理
});
// 遍历所有的LinalgOp
getOperation().walk([](LinalgOp linalgOp) {
// 可以对linalgOp进行处理.
});
5、MLIR 数据流图
MLIR还暴露了数据流图的def-use chains。每个Value只会是BlockArgument或Operation的结果,Value会被Operation集合使用,每个Operation的输入都是唯一确定的Value。可以用如下2张图表示


我们可以使用 build/bin/mlir-opt -test-print-defuse -allow-unregistered-dialect mlir/test/IR/print-ir-nesting.mlir -o test.mlir 打印下刚才那份MLIR的def-use chains,这个Pass文件在mlir/test/lib/IR/TestPrintDefUse.cpp,结果如下
Visiting op 'dialect.op1' with 0 operands:
Has 4 results:
- Result 0 has 2 uses:
- dialect.innerop3
- dialect.innerop1
- Result 1 has a single use: - dialect.innerop1
- Result 2 has a single use: - dialect.innerop3
- Result 3 has a single use: - dialect.innerop3
Visiting op 'dialect.innerop1' with 2 operands:
- Operand produced by operation 'dialect.op1'
- Operand produced by operation 'dialect.op1'
Has 0 results:
Visiting op 'dialect.innerop2' with 0 operands:
Has 0 results:
Visiting op 'dialect.innerop3' with 3 operands:
- Operand produced by operation 'dialect.op1'
- Operand produced by operation 'dialect.op1'
- Operand produced by operation 'dialect.op1'
Has 0 results:
Visiting op 'dialect.innerop4' with 0 operands:
Has 0 results:
Visiting op 'dialect.innerop5' with 0 operands:
Has 0 results:
Visiting op 'dialect.innerop6' with 0 operands:
Has 0 results:
Visiting op 'dialect.innerop7' with 0 operands:
Has 0 results:
Visiting op 'dialect.op2' with 0 operands:
Has 0 results:
Visiting op 'builtin.module' with 0 operands:
Has 0 results:
二、生成MLIR(MLIR结构实践)
除了文本输入外,我们还可以通过build创建我们的Operation。本章是一个单文件的例子,本实验完整代码在Github
1、Polygeist生成示例
这里以affine层级为例,为了降低难度我们可以先写出C代码,然后使用Polygeist的输出。C代码如下所示
#define N 10
float ArraySum(float a[N]) {
// Polygeist的pragma,会优先生成affine
#pragma scop
float sum = 0;
for (int i = 0; i < N; i++) {
sum += a[i];
}
return sum;
// Polygeist的pragma,会优先生成affine
#pragma endscop
}
通过cgeist ArraySum.c --function=* -S --memref-fullrank -o test.mlir可以获取到如下MLIR
module attributes {} {
func.func @ArraySum(%arg0: memref<10xf32>) -> f32 attributes {llvm.linkage = #llvm.linkage<external>} {
%cst = arith.constant 0.000000e+00 : f32
%alloca = memref.alloca() : memref<f32>
affine.store %cst, %alloca[] : memref<f32>
affine.for %arg1 = 0 to 10 {
%1 = affine.load %arg0[%arg1] : memref<10xf32>
%2 = affine.load %alloca[] : memref<f32>
%3 = arith.addf %2, %1 : f32
affine.store %3, %alloca[] : memref<f32>
}
%0 = affine.load %alloca[] : memref<f32>
return %0 : f32
}
}
2、OpBuilder创建简单函数
创建MLIR需要使用OpBuilder去create,我们还需要setInsertionPointToEnd去控制插入代码的位置,先创建一个函数并返回memref的第一个值的代码如下所示。
#include "mlir/IR/AsmState.h"
#include "mlir/IR/Builders.h"
#include "mlir/IR/BuiltinAttributes.h"
#include "mlir/IR/BuiltinOps.h"
#include "mlir/IR/BuiltinTypes.h"
#include "mlir/IR/MLIRContext.h"
#include "mlir/Support/FileUtilities.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
#include "mlir/Dialect/Affine/IR/AffineValueMap.h"
#include "mlir/Dialect/Arith/IR/Arith.h"
#include "mlir/Dialect/Func/IR/FuncOps.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
int main(int argc, char **argv) {
mlir::MLIRContext ctx;
// Context 加载FuncDialect,MemRefDialect 和 AffineDialect
ctx.loadDialect<mlir::func::FuncDialect, mlir::memref::MemRefDialect,
mlir::affine::AffineDialect>();
// 创建 OpBuilder
mlir::OpBuilder builder(&ctx);
// 创建IR的根,ModuleOp
auto module = builder.create<mlir::ModuleOp>(builder.getUnknownLoc());
// 设置插入点
builder.setInsertionPointToEnd(module.getBody());
// 创建 函数
auto f32 = builder.getF32Type();
// 创建 长度为 10 的数组
auto memref = mlir::MemRefType::get({10}, f32);
// 创建 func,函数名为ArraySum,输入是刚创建的数组,输出是f32
auto func = builder.create<mlir::func::FuncOp>(
builder.getUnknownLoc(), "ArraySum",
builder.getFunctionType({memref}, {f32}));
// 设置插入点,插入到func所建的block后面
builder.setInsertionPointToEnd(func.addEntryBlock());
// 创建 AffineMap,表达式为 () -> (1)。即无输入,结果为1
auto map = mlir::AffineMap::get(/*dimCount=*/0, /*symbolCount=*/0,
builder.getAffineConstantExpr(1),
builder.getContext());
// 创建AffineLoadOp
auto affineLoadOp = builder.create<mlir::affine::AffineLoadOp>(
builder.getUnknownLoc(), func.getArgument(0), map, mlir::ValueRange());
// 创建以AffineLoadOp的结果的返回Op
builder.create<mlir::func::ReturnOp>(builder.getUnknownLoc(),
affineLoadOp->getResult(0));
module->print(llvm::outs());
return 0;
}
3、CMake构建工具相关
CMakeLists.txt 文件内容
cmake_minimum_required(VERSION 3.13.4)
project(toy-build LANGUAGES CXX C)
set(CMAKE_CXX_STANDARD 17 CACHE STRING "C++ standard to conform to")
message(STATUS "Using MLIRConfig.cmake in: ${MLIR_DIR}")
find_package(MLIR REQUIRED CONFIG)
list(APPEND CMAKE_MODULE_PATH "${MLIR_CMAKE_DIR}")
list(APPEND CMAKE_MODULE_PATH "${LLVM_CMAKE_DIR}")
include(TableGen)
include(AddLLVM)
include(AddMLIR)
include(HandleLLVMOptions)
include_directories(${MLIR_INCLUDE_DIRS} ${LLVM_INCLUDE_DIRS})
add_executable(toy-build toy-build.cpp)
target_link_libraries(
toy-build
MLIRIR
MLIRMemRefDialect
MLIRFuncDialect
MLIRAffineDialect
MLIRArithDialect
MLIRAffineUtils
)
CMake 命令
mkdir build; cd build
# 请根据实际情况修改
export LLVM_BUILD_DIR=~/llvm-project/build
mkdir build; cd build
cmake -G Ninja .. \
-DMLIR_DIR=$LLVM_BUILD_DIR/lib/cmake/mlir \
-DLLVM_ENABLE_ASSERTIONS=ON \
-DCMAKE_BUILD_TYPE=Debug
ninja
可以得到 toy-build的可执行文件,运行可以得到以下输出
module {
func.func @ArraySum(%arg0: memref<10xf32>) -> f32 {
%0 = affine.load %arg0[1] : memref<10xf32>
return %0 : f32
}
}
4、完整代码
相较目标输出,我还需要累加求和等方法,累加求和需要一个memref去存储,我们还需要构建一个for循环,具体代码如下所示。
点击展开代码
#include "mlir/IR/AsmState.h"
#include "mlir/IR/Builders.h"
#include "mlir/IR/BuiltinAttributes.h"
#include "mlir/IR/BuiltinOps.h"
#include "mlir/IR/BuiltinTypes.h"
#include "mlir/IR/MLIRContext.h"
#include "mlir/Support/FileUtilities.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
#include "mlir/Dialect/Affine/IR/AffineValueMap.h"
#include "mlir/Dialect/Arith/IR/Arith.h"
#include "mlir/Dialect/Func/IR/FuncOps.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
int main(int argc, char **argv) {
mlir::MLIRContext ctx;
// Context 加载FuncDialect,MemRefDialect, AffineDialect 和 ArithDialect
ctx.loadDialect<mlir::func::FuncDialect, mlir::memref::MemRefDialect,
mlir::affine::AffineDialect, mlir::arith::ArithDialect>();
// 创建 OpBuilder
mlir::OpBuilder builder(&ctx);
// 创建IR的根,ModuleOp
auto module = builder.create<mlir::ModuleOp>(builder.getUnknownLoc());
// 设置插入点
builder.setInsertionPointToEnd(module.getBody());
// 创建 函数
auto f32 = builder.getF32Type();
// 创建 长度为 10 的数组
auto memref = mlir::MemRefType::get({10}, f32);
// 创建 func,函数名为ArraySum,输入是刚创建的数组,输出是f32
auto func = builder.create<mlir::func::FuncOp>(
builder.getUnknownLoc(), "ArraySum",
builder.getFunctionType({memref}, {f32}));
// 设置插入点,插入到func所建的block后面
builder.setInsertionPointToEnd(func.addEntryBlock());
// 创建浮点类型的1.0
mlir::Value constantFloatZeroVal = builder.create<mlir::arith::ConstantOp>(
builder.getUnknownLoc(), builder.getF32FloatAttr(0.0));
// 存储sum的memref
auto sumMemref = mlir::MemRefType::get({}, f32);
// 创建sum的AllocaOp
mlir::Value sumMemrefVal = builder.create<mlir::memref::AllocaOp>(
builder.getUnknownLoc(), sumMemref);
// 创建访问sum的空AffineMap
auto sumMap = builder.getEmptyAffineMap();
// 使用 store 初始化为0
builder.create<mlir::affine::AffineStoreOp>(
builder.getUnknownLoc(), constantFloatZeroVal, sumMemrefVal, sumMap,
mlir::ValueRange());
// 创建 lower bound AffineMap
auto lbMap = mlir::AffineMap::get(/*dimCount=*/0, /*symbolCount=*/0,
builder.getAffineConstantExpr(0),
builder.getContext());
// 创建 upper bound AffineMap
auto ubMap = mlir::AffineMap::get(/*dimCount=*/0, /*symbolCount=*/0,
builder.getAffineConstantExpr(10),
builder.getContext());
// 创建循环
auto affineForOp = builder.create<mlir::affine::AffineForOp>(
builder.getUnknownLoc(), mlir::ValueRange(), lbMap, mlir::ValueRange(),
ubMap, 1);
auto savedIP = builder.saveInsertionPoint();
builder.setInsertionPointToStart(affineForOp.getBody());
// 为 %arg0[%arg1] 创建 AffineMap,表达式为 (d0) -> (d0)。即输入d0,结果为d0
auto forLoadMap = mlir::AffineMap::get(
/*dimCount=*/1, /*symbolCount=*/0, builder.getAffineDimExpr(0),
builder.getContext());
// Load %arg0[%arg1]
mlir::Value affineLoad = builder.create<mlir::affine::AffineLoadOp>(
builder.getUnknownLoc(), func.getArgument(0), forLoadMap,
mlir::ValueRange(affineForOp.getBody()->getArgument(0)));
// Load %alloca[]
mlir::Value sumInforLoad = builder.create<mlir::affine::AffineLoadOp>(
builder.getUnknownLoc(), sumMemrefVal, sumMap, mlir::ValueRange());
// %alloca[] + %arg0[%arg1]
mlir::Value add = builder.create<mlir::arith::AddFOp>(
builder.getUnknownLoc(), sumInforLoad, affineLoad);
// 保存到 %alloca[]
builder.create<mlir::affine::AffineStoreOp>(
builder.getUnknownLoc(), add, sumMemrefVal, sumMap, mlir::ValueRange());
// 恢复InsertionPoint
builder.restoreInsertionPoint(savedIP);
// Load %alloca[]
mlir::Value sumLoadVal = builder.create<mlir::affine::AffineLoadOp>(
builder.getUnknownLoc(), sumMemrefVal, sumMap, mlir::ValueRange());
// 创建以%alloca[]的结果的返回Op
builder.create<mlir::func::ReturnOp>(builder.getUnknownLoc(), sumLoadVal);
module->print(llvm::outs());
return 0;
}
以上代码重新编译运行就可以得到和前文Polygeist的工具输出的代码,当然以上代码你可以任意修改让其输出不同的代码。如果你在affine或scf层级前期使用Polygeist作为参照会有很大帮助,熟悉了写起来和编程语言差不多。以上代码还有优化空间,我们将在下一章节写Pass进行优化。
三、书写MLIR Pass(项目文件组织实践)
MLIR Pass的入口均是runOnOperation函数,而且相较LLVM Pass简洁得多。本章是一个工程的例子,本实验完整代码在Github
1、项目文件组织
Pass的全局注册会在一个tablegen(.td)文件中。这里参考了Polygeist中polygeist-opt的构建。
上文代码明显是可以进行循环展开的,其重复读取%alloca[]变量,关于循环展开的作用可以参考以下引用。
循环展开(Loop Unrolling)是一种编译优化技术,通过减少循环控制开销和增加指令级并行性来提高程序的执行效率。其基本思想是将循环体的多次迭代合并到一个迭代中,从而减少循环控制的开销。
其中Pass.td 如下所示
#ifndef TOY_PASSES
#define TOY_PASSES
include "mlir/Pass/PassBase.td"
def ToyLoopUnroll : Pass<"toy-loop-unroll", "mlir::ModuleOp"> {
let summary = "Loop unroll";
let constructor = "toy::createToyLoopUnrollPass()";
}
#endif // TOY_PASSES
还需要在Pass.h 中声明这个constructor, Pass.h 代码如下所示
#ifndef TOY_PASSES_H
#define TOY_PASSES_H
#include "mlir/Pass/Pass.h"
#include "mlir/IR/BuiltinOps.h"
#include <memory>
namespace mlir {
namespace toy {
std::unique_ptr<Pass> createToyLoopUnrollPass();
} // namespace toy
} // namespace mlir
namespace mlir {
#define GEN_PASS_REGISTRATION
#include "toy/Passes/Passes.h.inc"
} // end namespace mlir
#endif // TOY_PASSES_H
之前的Pass.td在编译时会生成.inc文件,有内容如下
template <typename DerivedT>
class ToyLoopUnrollBase : public ::mlir::OperationPass<mlir::ModuleOp> {
public:
using Base = ToyLoopUnrollBase;
ToyLoopUnrollBase() : ::mlir::OperationPass<mlir::ModuleOp>(::mlir::TypeID::get<DerivedT>()) {}
ToyLoopUnrollBase(const ToyLoopUnrollBase &other) : ::mlir::OperationPass<mlir::ModuleOp>(other) {}
/// Returns the command-line argument attached to this pass.
static constexpr ::llvm::StringLiteral getArgumentName() {
return ::llvm::StringLiteral("toy-loop-unroll");
}
::llvm::StringRef getArgument() const override { return "toy-loop-unroll"; }
::llvm::StringRef getDescription() const override { return "Loop unroll"; }
/// Returns the derived pass name.
static constexpr ::llvm::StringLiteral getPassName() {
return ::llvm::StringLiteral("ToyLoopUnroll");
}
::llvm::StringRef getName() const override { return "ToyLoopUnroll"; }
/// Support isa/dyn_cast functionality for the derived pass class.
static bool classof(const ::mlir::Pass *pass) {
return pass->getTypeID() == ::mlir::TypeID::get<DerivedT>();
}
/// A clone method to create a copy of this pass.
std::unique_ptr<::mlir::Pass> clonePass() const override {
return std::make_unique<DerivedT>(*static_cast<const DerivedT *>(this));
}
/// Return the dialect that must be loaded in the context before this pass.
void getDependentDialects(::mlir::DialectRegistry ®istry) const override {
}
/// Explicitly declare the TypeID for this class. We declare an explicit private
/// instantiation because Pass classes should only be visible by the current
/// library.
MLIR_DEFINE_EXPLICIT_INTERNAL_INLINE_TYPE_ID(ToyLoopUnrollBase<DerivedT>)
protected:
private:
};
所以我们需要继承的类为toy::ToyLoopUnrollBase,空实现代码如下所示
#include "PassDetails.h"
#include "toy/Passes/Passes.h"
#include "llvm/Support/Debug.h"
#define DEBUG_TYPE "toy-loop-unroll"
using namespace mlir;
namespace {
struct ToyLoopUnroll : public toy::ToyLoopUnrollBase<ToyLoopUnroll> {
void runOnOperation() override {
// getOperation()->dump();
}
};
} // end anonymous namespace
namespace mlir {
namespace toy {
std::unique_ptr<Pass> createToyLoopUnrollPass() {
return std::make_unique<ToyLoopUnroll>();
}
} // namespace toy
} // namespace mlir
toy-opt.cpp 注册了mlir的所有Pass,并调用MlirOptMain 方法
#include "mlir/Conversion/Passes.h"
#include "mlir/Dialect/Affine/IR/AffineOps.h"
#include "mlir/Dialect/Arith/IR/Arith.h"
#include "mlir/Dialect/Func/IR/FuncOps.h"
#include "mlir/Dialect/LLVMIR/LLVMDialect.h"
#include "mlir/Dialect/LLVMIR/NVVMDialect.h"
#include "mlir/Dialect/Math/IR/Math.h"
#include "mlir/Dialect/MemRef/IR/MemRef.h"
#include "mlir/Dialect/SCF/IR/SCF.h"
#include "mlir/InitAllPasses.h"
#include "mlir/Pass/PassRegistry.h"
#include "mlir/Tools/mlir-opt/MlirOptMain.h"
#include "mlir/Transforms/Passes.h"
#include "toy/Passes/Passes.h"
using namespace mlir;
int main(int argc, char **argv) {
// 注册 mlir 所有Pass
mlir::registerAllPasses();
mlir::DialectRegistry registry;
// 插入所需dialect
registry.insert<mlir::affine::AffineDialect>();
registry.insert<mlir::LLVM::LLVMDialect>();
registry.insert<mlir::memref::MemRefDialect>();
registry.insert<mlir::func::FuncDialect>();
registry.insert<mlir::arith::ArithDialect>();
registry.insert<mlir::scf::SCFDialect>();
// 导入Toy的所有Pass
mlir::registerToyPasses();
return mlir::failed(mlir::MlirOptMain(argc, argv, "toy-opt", registry));
}
编译运行toy-opt即可成功运行,项目代码请参考github
2、Pass执行流程
我们可以用gdb打印出其函数调用栈,其大致调用过程为MlirOptMain->PassManager::run->runOnOperation
#0 (anonymous namespace)::ToyLoopUnroll::runOnOperation (this=0x55555ba636b0)
at /opt/mlir-tutorial/ex5-pass-new/lib/toy/Passes/ToyLoopUnroll.cpp:13
#1 0x0000555559b2b769 in mlir::detail::OpToOpPassAdaptor::run(mlir::Pass*, mlir::Operation*, mlir::AnalysisManager, bool, unsigned int) ()
#2 0x0000555559b2bc31 in mlir::detail::OpToOpPassAdaptor::runPipeline(mlir::OpPassManager&, mlir::Operation*, mlir::AnalysisManager, bool, unsigned int, mlir::PassInstrumentor*, mlir::PassInstrumentation::PipelineParentInfo const*) ()
#3 0x0000555559b2c495 in mlir::PassManager::run(mlir::Operation*) ()
#4 0x0000555556ee3bba in performActions(llvm::raw_ostream&, std::shared_ptr<llvm::SourceMgr> const&, mlir::MLIRContext*, mlir::MlirOptMainConfig const&) ()
#5 0x0000555556ee4e0c in processBuffer(llvm::raw_ostream&, std::unique_ptr<llvm::MemoryBuffer, std::default_delete<llvm::MemoryBuffer> >, mlir::MlirOptMainConfig const&, mlir::DialectRegistry&, llvm::ThreadPool*) ()
#6 0x0000555556ee4f6d in mlir::LogicalResult llvm::function_ref<mlir::LogicalResult (std::unique_ptr<llvm::MemoryBuffer, std::default_delete<llvm::MemoryBuffer> >, llvm::raw_ostream&)>::callback_fn<mlir::MlirOptMain(llvm::raw_ostream&, std::unique_ptr<llvm::MemoryBuffer, std::default_delete<llvm::MemoryBuffer> >, mlir::DialectRegistry&, mlir::MlirOptMainConfig const&)::{lambda(std::unique_ptr<llvm::MemoryBuffer, std::default_delete<llvm::MemoryBuffer> >, llvm::raw_ostream&)#1}>(long, std::unique_ptr<llvm::MemoryBuffer, std::default_delete<llvm::Memory-Buffer> >, llvm::raw_ostream&) ()
#7 0x0000555559db5c74 in mlir::splitAndProcessBuffer(std::unique_ptr<llvm::MemoryBuffer, std::default_delete<llvm::MemoryBuffer> >, llvm::function_ref<mlir::LogicalResult (std::unique_ptr<llvm::MemoryBuffer, std::default_delete<llvm::MemoryBuffer> >, llvm::raw_ostream&)>, llvm::raw_ostream&, bool, bool) ()
#8 0x0000555556edd5b4 in mlir::MlirOptMain(llvm::raw_ostream&, std::unique_ptr<llvm::MemoryBuffer, std::default_delete<llvm::MemoryBuffer> >, mlir::DialectRegistry&, mlir::MlirOptMainConfig const&) ()
#9 0x0000555556ee50b1 in mlir::MlirOptMain(int, char**, llvm::StringRef, llvm::StringRef, mlir::DialectRegistry&) ()
#10 0x0000555556ee5577 in mlir::MlirOptMain(int, char**, llvm::StringRef, mlir::DialectRegistry&) ()
#11 0x00005555558aab01 in main (argc=5, argv=0x7fffffffe178)
at /opt/mlir-tutorial/ex5-pass-new/tools/toy-opt/toy-opt.cpp:33
3、Pass编写
通过 bin/toy-opt --help | grep unroll我们还可以查看mlir-opt下的unroll Pass, 运行结果如下所示
-affine-loop-unroll - Unroll affine loops
--cleanup-unroll - Fully unroll the cleanup loop when possible.
--unroll-factor=<uint> - Use this unroll factor for all loops being unrolled
--unroll-full - Fully unroll loops
--unroll-full-threshold=<uint> - Unroll all loops with trip count less than or equal to this
--unroll-num-reps=<uint> - Unroll innermost loops repeatedly this many times
--unroll-up-to-factor - Allow unrolling up to the factor specified
--affine-loop-unroll-jam - Unroll and jam affine loops
--unroll-jam-factor=<uint> - Use this unroll jam factor for all loops (default 4)
--full-unroll - Perform full unrolling when converting vector transfers to SCF
--toy-loop-unroll - Loop unroll
这个affine-loop-unroll看起来就能解决我们的问题,通过build/bin/toy-opt sumArray.mlir --affine-loop-unroll -o test.mlir的到了以下结果
#map = affine_map<(d0) -> (d0 + 1)>
#map1 = affine_map<(d0) -> (d0 + 2)>
#map2 = affine_map<(d0) -> (d0 + 3)>
module {
func.func @ArraySum(%arg0: memref<10xf32>) -> f32 attributes {llvm.linkage = #llvm.linkage<external>} {
%cst = arith.constant 0.000000e+00 : f32
%alloca = memref.alloca() : memref<f32>
affine.store %cst, %alloca[] : memref<f32>
affine.for %arg1 = 0 to 8 step 4 {
%1 = affine.load %arg0[%arg1] : memref<10xf32>
%2 = affine.load %alloca[] : memref<f32>
%3 = arith.addf %2, %1 : f32
affine.store %3, %alloca[] : memref<f32>
%4 = affine.apply #map(%arg1)
%5 = affine.load %arg0[%4] : memref<10xf32>
%6 = affine.load %alloca[] : memref<f32>
%7 = arith.addf %6, %5 : f32
affine.store %7, %alloca[] : memref<f32>
%8 = affine.apply #map1(%arg1)
%9 = affine.load %arg0[%8] : memref<10xf32>
%10 = affine.load %alloca[] : memref<f32>
%11 = arith.addf %10, %9 : f32
affine.store %11, %alloca[] : memref<f32>
%12 = affine.apply #map2(%arg1)
%13 = affine.load %arg0[%12] : memref<10xf32>
%14 = affine.load %alloca[] : memref<f32>
%15 = arith.addf %14, %13 : f32
affine.store %15, %alloca[] : memref<f32>
}
affine.for %arg1 = 8 to 10 {
%1 = affine.load %arg0[%arg1] : memref<10xf32>
%2 = affine.load %alloca[] : memref<f32>
%3 = arith.addf %2, %1 : f32
affine.store %3, %alloca[] : memref<f32>
}
%0 = affine.load %alloca[] : memref<f32>
return %0 : f32
}
}
以factor=4也就是循环因子为4展开了,而且产生了新的affine_map,如下所示。分别对应 %arg1+1, %arg1+1, %arg1+1
#map = affine_map<(d0) -> (d0 + 1)>
#map1 = affine_map<(d0) -> (d0 + 2)>
#map2 = affine_map<(d0) -> (d0 + 3)>
我们可以将其部分实现copy过来,就是我们自己的loop-unroll了,而且方便后期修改,代码修改片段如下所示。
void runOnOperation() override {
auto moduleOp = getOperation();
moduleOp.walk([&](affine::AffineForOp op) {
(void)loopUnrollJamByFactor(op, 4);
});
}
当然这份代码还有别的优化空间,我可以在把sum丢进AffineForOp的IterArgs,另外循环展开后关于sum的大部分访存都是多余的,需要去除。
4、单独Pass添加(7.24更)
我们可以将sum放进IterArgs作为寄存器使用,本节具体加Pass见commit。
我们将上述case简化如下所示,也就是在循环里会load一个单个元素的memref,然后去做运算,最后将其运算的结果存储到memref中。
affine.for %arg1 = 0 to 10 {
...
%2 = affine.load %alloca[] : memref<type>
%3 = arith.? %2, ?
affine.store %3, %alloca[] : memref<type>
}
我们可以先对单元素memref判断,如下所示
auto mt = memref.getType().cast<MemRefType>();
// 只针对memref为1个元素
if (mt.getShape().size()) {
return false;
}
其次我们需要考虑其中load和store的def-use chains,我们可以从循环中的load开始分析。关于所有load,我们可以要求循环中只有这一次load,因为如果没有store后load经过--csePass(公共子表达式消除)就会直接用上次load的值,所以具体代码如下所示
for (auto *user : memref.getUsers()) {
if (auto otherLoad = dyn_cast<affine::AffineLoadOp>(user)) {
if (load != otherLoad && IsParentOp(otherLoad, forOp)) {
// for region 内有其他 load,不优化
return false;
}
}
}
关于store我们需要考虑的有些多,我们首先需要保证循环里只有这一次store,我们可以用个Flag去标记。另外如果循环中有if呢,那么会产生新的region,但是其依旧可以优化,所以我们还需要判断store和load是都在for这个region内,且没有嵌套的store,具体代表如下所示
bool storeInforFlag = false;
// 获取 def-use chains
for (auto *user : memref.getUsers()) {
if (auto store = dyn_cast<affine::AffineStoreOp>(user)) {
// for循环内的同级store
if (areInSameAffineFor(load, store, forOp)) {
if (storeInforFlag) {
// 仅允许出现一次store
return false;
}
storeInforFlag = true;
// 检查到达 store 都必须经过 这次load,且不在一个block
if (!isDominance(load, store)) {
return false;
}
storeInfor = store;
} else if (IsParentOp(store, forOp)) {
// for region 内还有其他store,不优化
return false;
}
}
}
以上代码经过拼凑我们就可以得到一个判断是否可以进行优化的函数
bool isDominance(Operation *maybeDominateOp, Operation *op) {
DominanceInfo dom(maybeDominateOp);
// 利用 支配关系判断,执行op前maybeDominateOp一定被执行过,
// properly会判断不在同一个块
return dom.properlyDominates(maybeDominateOp, op);
}
bool checkloadCanPromote(affine::AffineForOp forOp, affine::AffineLoadOp load,
Operation *&storeInfor) {
Value memref = load.getMemRef();
auto mt = memref.getType().cast<MemRefType>();
// 只针对memref为1个元素
if (mt.getShape().size()) {
return false;
}
bool storeInforFlag = false;
// 获取 def-use chains
for (auto *user : memref.getUsers()) {
if (auto store = dyn_cast<affine::AffineStoreOp>(user)) {
// for循环内的同级store
if (areInSameAffineFor(load, store, forOp)) {
if (storeInforFlag) {
// 仅允许出现一次store
return false;
}
storeInforFlag = true;
// 检查到达 store 都必须经过 这次load,且不在一个block
if (!isDominance(load, store)) {
return false;
}
storeInfor = store;
} else if (IsParentOp(store, forOp)) {
// for region 内还有其他store,不优化
return false;
}
} else if (auto otherLoad = dyn_cast<affine::AffineLoadOp>(user)) {
if (load != otherLoad && IsParentOp(otherLoad, forOp)) {
// for region 内有其他 load,不优化
return false;
}
}
}
// debug 时打印优化的memref
LLVM_DEBUG(llvm::dbgs() << " Can promte to iter_args: " << memref << "\n");
return true;
}
那我们的目标是什么呢,就是将这次load提前到for之前,store放到for之后,而且load的值作为iterArgs传递进去计算并yield返回结果。如下所示
%0 = affine.load %alloca[] : memref<type>
%1 = affine.for %arg1 = 0 to 10 iter_args(%arg2 = %0) -> (type) {
%3 = ...
%4 = arith.? %arg2, %3
affine.yield %4
}
affine.store %1, %alloca[] : memref<type>
所以需要我们新建一个for Op,加上iter_args,并将原来load的值的使用全部替换为%arg2 这个block argument,循环内不需要store了,挪到外面将循环的返回值store起来。具体代码如下所示
void replaceWithNewFor(affine::AffineForOp forOp, Operation *load,
Operation *store) {
OpBuilder builder(forOp);
builder.setInsertionPoint(forOp);
auto movedLoad = builder.clone(*load);
auto newLoop =
replaceForOpWithNewSignature(builder, forOp, movedLoad->getResult(0));
// update yieldOp
auto forYieldOp =
cast<affine::AffineYieldOp>(newLoop.getBody()->getTerminator());
forYieldOp->insertOperands(forYieldOp.getNumOperands(), store->getOperand(0));
// 重写AffineStoreOp
builder.setInsertionPointAfter(newLoop);
auto affineStore = cast<affine::AffineStoreOp>(store);
// store 循环的返回值
builder.create<affine::AffineStoreOp>(
newLoop.getLoc(), newLoop.getResults()[newLoop.getNumResults() - 1],
affineStore.getMemRef(), affineStore.getAffineMap(),
affineStore.getMapOperands());
// 修改load的值为for的最后一个iter_args
load->getResult(0).replaceAllUsesWith(
newLoop.getBody()->getArgument(newLoop.getBody()->getNumArguments() - 1));
// 删除多余的op
load->erase();
store->erase();
}
其中replaceForOpWithNewSignature也是蛮复杂的,但是你可以从别的地方抄,我这里用的是mlir/lib/Conversion/VectorToGPU/VectorToGPU.cpp:1104。将其组装起来,就可以得到ToyIterArgs 文件。
我们还需要在Pass.td中注册Pass,Pass.h 声明创建Pass的方法,并修改mlir-tutorial/ex5-pass-new/lib/toy/Passes/CMakeLists.txt添加需要的文件即可,本次完整代码修改我们还需要在Pass.td中注册Pass,Pass.h 声明创建Pass的方法,并修改mlir-tutorial/ex5-pass-new/lib/toy/Passes/CMakeLists.txt,全部修改见commit。
编译后使用build/bin/toy-opt sumArray.mlir --toy-mem-to-iter-args -o test.mlir即可得到我们想要的结果。我们其实不仅可以针对单个元素的memref,如果affineMap全是常数也是非常容易比较的,我们也可以把这个Pass迭代多次,也就是PatternRewrite。这些问题均可以参考Polygeist AffineReduction,笔者本Pass参考了其部分代码,我在工作中写了一个意外和其撞车,不过我写的实现更冗杂,这个Pass在对比affineMap时有bug,你有兴趣可以帮他修一下。
结语
通过以上的学习,您对MLIR表示的丰富及优化可能有了更深刻的理解,一起来玩编译器优化吧。
我近期应该还会更新下AffineMap、PatternRewrite、自定义dialect 以及包含但不限于triton在内我觉得有意思的Pass赏析。作者彻底鸽了!
附、参考
1.周可行的中文教程
2.官方文档
本文来自博客园,作者:暴力都不会的蒟蒻,转载请注明原文链接:https://www.cnblogs.com/BobHuang/p/18249482

 浙公网安备 33010602011771号
浙公网安备 33010602011771号