MLIR学习可以参考的项目
MLIR(Multi-Level Intermediate Representation)包含了更多的信息,抽象层级更高。笔者在2023.8开始从事MLIR编译器的开发,当时学习资料不多,自己搜集了些开源项目并在2023.11发表在我的博客里,现在整理下挪到知乎来。
对MLIR不了解可以看下我的这篇文章。从零开始教你写一个MLIR Pass
一、OpenAI
1、triton-lang/Triton 16k
Pytorch2.0巨大更新,OpenAI的Triton也随着其chatgpt的爆火而备受关注。带来了Triton和Triton GPU高层次抽象的dialect,能够很好的表示GPU的硬件细节,Pytorch2.0更新日志说Triton有95%的库水平。
我写了一篇 浅析 Triton 执行流程,有兴趣可以看。Triton是目前最成功的MLIR项目。
seed最近开源了分布式的Triton ByteDance-Seed/Triton-distributed,激动人心,大家速速来star
triton-cpu也值得看看,同系列还有到linalg dialect 的微软 triton-shared和寒武纪 triton-linalg
直接lower到Triton你又该如何应对,好好好,支持helion
除了nvidia、amd、intel、cpu、microsoft(部分)、meta tlx扩展(Low-level)这些后端外,我们还有昆仑芯、摩尔线程、沐曦、ARM china、华为昇腾、清微智能、天数智芯、寒武纪(部分)、Seed 分布式扩展Op 的后端实现可以参考。
二、LLVM
1、官方的torch前端torch-mlir 1.6k
可以将torch的model转换到MLIR中
2、官方在开发的新clang 0.51k
这个项目我觉得蛮有意思的,clang但是以MLIR作为IR。cgeist在翻译时用的还是clang,因为AST的信息和MLIR不对等所以有些东西不太好表示,期待早日做好将大大提高clang的表达能力。有可能实现大一统
3、官方的C/C++前端Polygeist 0.56k
可以将C/C++代码翻译到affine层级,不太会写输出结果,可以参考下。最新版的Polygeist增加了poly,你也可以学习下poly的接入方式。
4、LLVM中的toy 33.3k
适合上手学习调试,官方还有文档
5、LLVM中的Fortran前端Flang 33.k
LLVM中的Fortran前端,这个也做得蛮早了,但是还不够完善。最初是f18 project
三、Google
1、iree-org/iree 3.2k
MLIR大模型推理,很多参考了这个项目。做推理框架首先看这个,当然推理框架还有llama.cpp、ollama、TensorRT-LLM、vllm、sglang。
OpenXLA 是 Google 想将编译器相关技术从 TensorFlow 独立出来的项目组,里面有hlo dialect的定义,fusion pass的思路,这个貌似着工业界用的还不少,我以前一直以为处于Pytorch的大一统时代。
IREE里隐藏着对 StableHLO,这是定义的神经网络模型的高层级运算。
当然XLA也是可以接进Pytorch的,有Pytorch/XLA。
IREE和TVM的对比
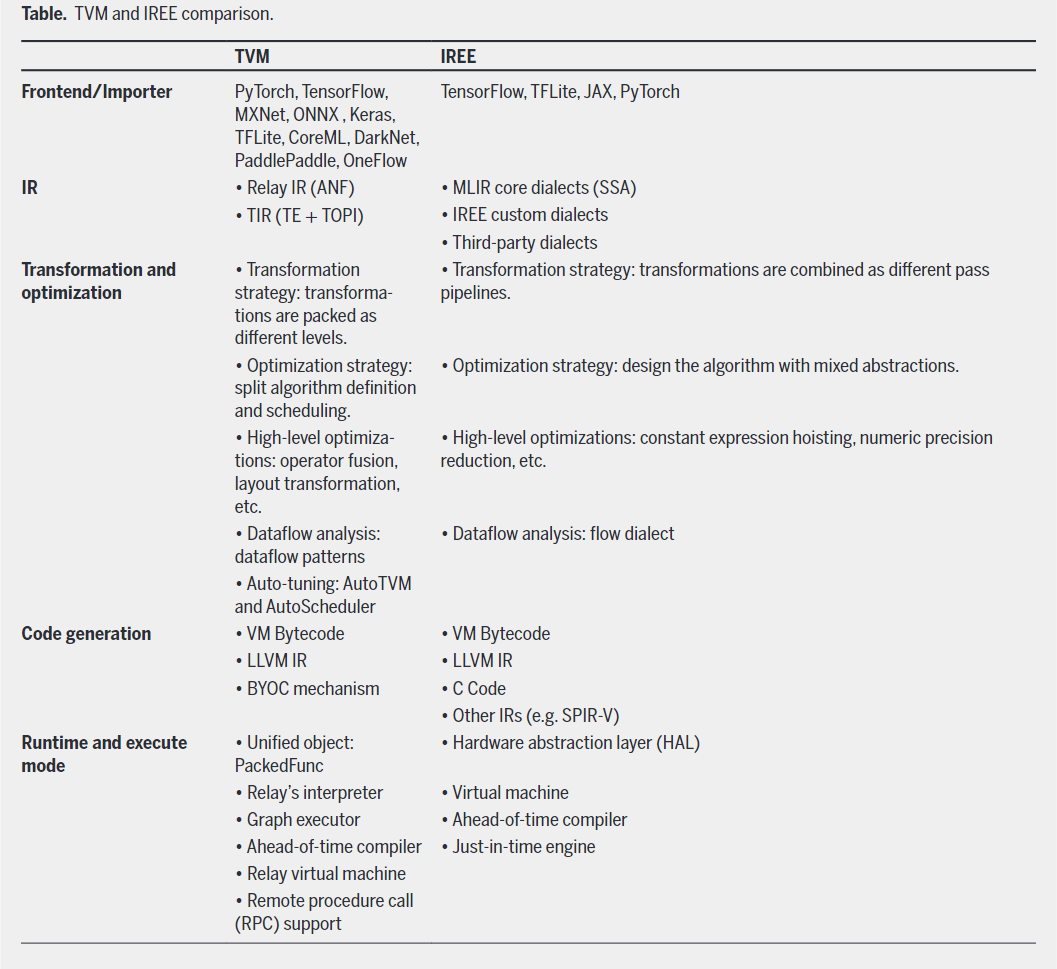 来自Compiler Technologies in Deep Learning Co-Design: A Survey
来自Compiler Technologies in Deep Learning Co-Design: A Survey
2、openxla/stablehlo 0.50k
3、LLVM中的mlir 33.3k
Chris Lattner2018年在Google Brain主导开发了MLIR,并在2019年4月正式开源出来。Chris Lattner在AI民主化系列文章对MLIR的中肯评价如下。
Triton also includes compiler-driven optimizations—like vectorization—and enables simplified double buffering and software pipelining, which overlap memory transfers with computation. In CUDA, these techniques require deep GPU expertise; in Triton, they’re exposed in a way that non-experts can actually use. For a deeper dive, OpenAI provides detailed tutorials.
四、AMD
1、AMD rocMLIR
可以针对AMD硬件做CONV和GEMM kernel生成,被MIGraphX使用。都说AMD在梭哈MLIR实现弯道超车,具体怎么样可以看代码。他们还实现了xmir-runner,如果有自制MLIR JIT runner可以参考下。
2、Xilinx AIR platforms
Xilinx是做FPGA的,被AMD收购了,FPGA中也有AI引擎,他们梭哈MLIR蛮久了,开源质量不错。
大多数都是转换类,Pass位置
这个还能看到有人在实际运用,比如mase,有100多个star,不过HLS基本都是国人在搞
Nod.ai的人还在搞新的dsl
五、NVIDIA
1、NVIDIA/cutlass
只开源了前端非常少的一部分,但是我们可以看到MLIR的生态大家都在做。很大的一块收益是编译速度的显著提升,你不用在编译CUTLASS时等待很久。提升>100x,在去掉C++模版类实例化使用MLIR后,8kx8kx8k GEMM从C++编译时间的27997ms来到了241ms,十分惊人。

带来的收益还有Pytorch的集成,这点对不熟悉cutlass C++但是想来写算子的人是非常友好的。
六、intel
1、intel/graph-compiler
这个MLIR接的是oneDNN Graph API,也是最近刚开始做
2、intel/intel-xpu-backend-for-triton
intel的xpu后端,这里也有和微软triton-shared类似的部分。
七、微软
1、microsoft/triton-shared
微软最先在linalg上做了一些尝试,并把自己的一些优化share出来了。This talk at the 2023 Triton Developer Conferene
八、meta
META可以看到的是在折腾Triton,Meta 推荐芯片MTIAV2 也使用了Triton这套软件栈。
1、facebookexperimental/triton
meta在搞TLX (Triton Low-level Language Extensions),把 warp-aware, hardware-near 带回Triton,以求拿到性能。把 Low-level 带回Triton也是有收益的,能拿到性能。
2、pytorch-labs/triton-cpu
也折腾过Triton的cpu后端的。
九、ONNX
1、onnx/onnx-mlir
这个项目我还真用过,要把ONNX转换到MLIR dialect,不少krnl的需要自己实现。所以经常是一边看netron可视化工具,一边对语义,写实现。
九、Jim Keller的tenstorrent
1、tenstorrent tt-mlir
tenstorrent是Jim Keller(硅仙人)领导的AI芯片新创公司,目标也是他们的AI加速器。兆松(1nfinite)有一个中文文档
十、硅基流动
1、Oneflow-Inc/oneflow
一流科技较早将MLIR融入自己的深度学习框架,也对MLIR做了些支持。不过在深度学习中我觉得很多依旧是Transform类的,能lower正确就可以,很像一个工程问题。定义创建Pass的文件,甚至还有PDLL这类高级功能。一流科技也就是现在的硅基流动。
十一、算能
1、sophgo/tpu-mlir
TPU-MLIR是一个面向深度学习处理器的开源TPU编译器。该项目提供了完整的工具链,将各种框架下预训练的神经网络转换为可在TPU中高效运行的二进制文件bmodel,以实现更高效的推理。TPU-MLIR项目已应用于算能开发的最新一代深度学习处理器BM1684X。结合处理器本身的高性能ARM内核以及相应的SDK,可以实现深度学习算法的快速部署。甚至提供了相应课程,只需要填写相关信息就可以学习,B站不用注册,来白嫖B站这边。
十二、软件所iscas
1、buddy-mlir
适合上手学习调试,不过已经越来越强大了。其在最近(2023年11月)完成了端到端 LLaMA2-7B 推理示例
十三、华为
1、mindspore-ai/akg
AKG是Auto Kernel Generator的简称,在昇思MindSpore框架中担任图算融合编译加速的任务。AKG基于polyhedral多面体编译技术,可自动生成满足并行性与数据局部性的调度,目前能够支持NPU/GPU/CPU等硬件。
MindSpore AKG MLIR已经支持主流模型中所有重要算子,但是随着网络的迭代和算法的改进,依然不断有新的算子出现。由于MindSpore AKG支持包括NPU、GPU、CPU在内的多硬件后端,我们规划了基于后端代码生成能力完成相关算子支持,包括:1.对于新算子提供基于循环和数学表达式的表达。2.对于融合算子提供以已有算子拼接的展开表达。
B站有对应的技术分享会录播
源码大概看了下,为了解决动态shape弄了个symbolicStrExprMap,要SameSymbolicShape。用的是symengine,而不是MLIR的affine dialect
GPU Lower流程如下所示
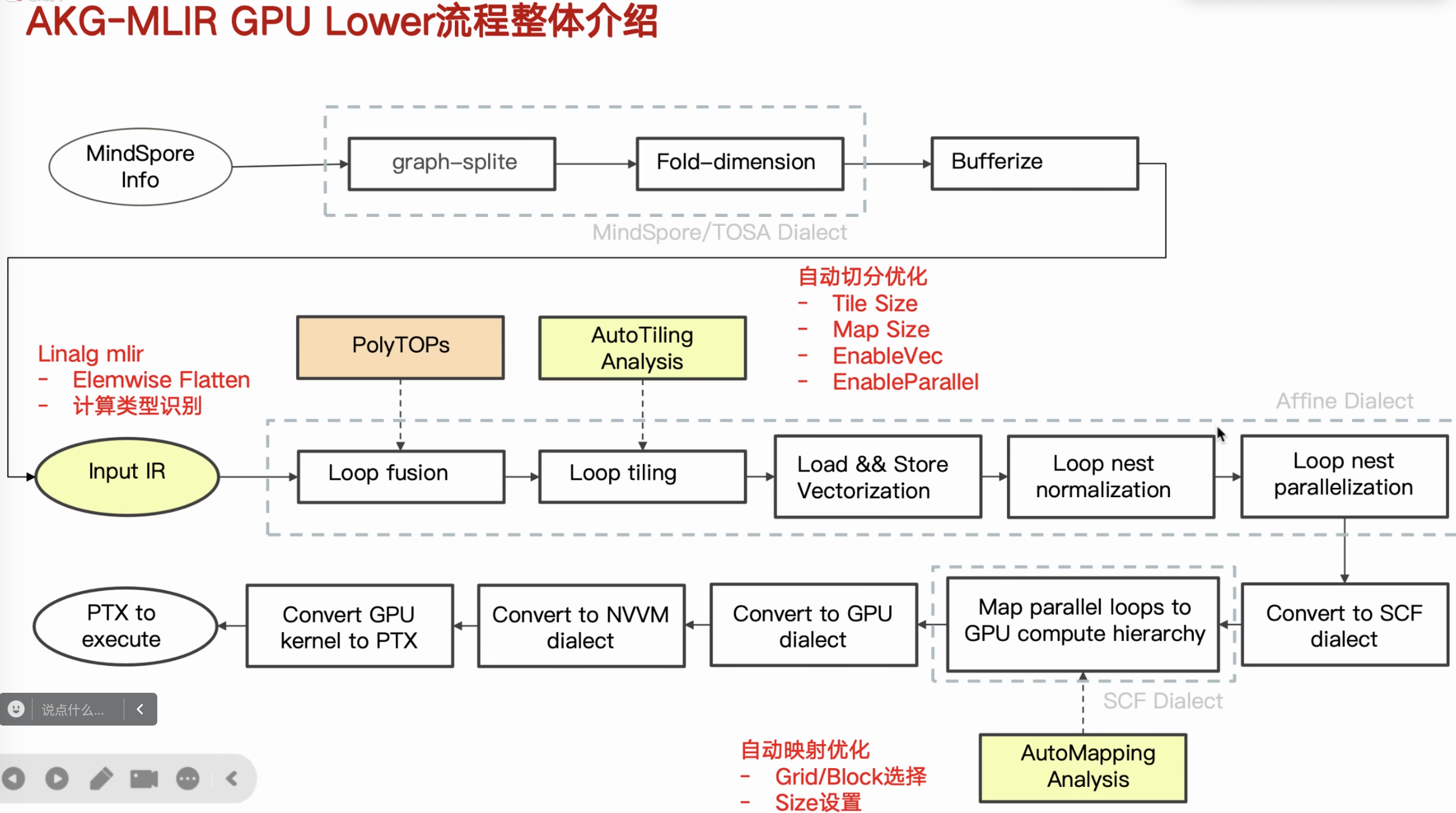
发布后就没怎么更新了,心痛,想学。
十四、字节跳动
1、bytedance/byteir
ByteIR项目是字节跳动的模型编译解决方案。ByteIR包括编译器、运行时和前端,并提供端到端的模型编译解决方案。 尽管所有的ByteIR组件(编译器/运行时/前端)一起提供端到端的解决方案,并且都在同一个代码库下,但每个组件在技术上都可以独立运行。
十五、阿里
1、alibaba/BladeDISC
阿里云PAI团队的BladeDISC目的是解决AI编译器的Dynamic Shape问题,主要做了显存优化、计算优化、通信优化,2024年底发现其推文多了起来,这个工作的论文被 NeurIPS Workshop 2024收录了。
十六、寒武纪
1、Cambricon/triton-linalg
寒武纪针对mlu的到linalg的实现,linalg之后和硬件实现有关。这是发布时的Slides,72页开始

十七、一些教程
1、OpenMLIR/mlir-tutorial
北大周可行的中文教程,更适合中国宝宝使用。我完善了两章,之后还想加点新东西。
2、KEKE046/mlir-tutorial
北大周可行的中文教程原地址
3、j2kun/mlir-tutorial
Jeremy Kun的英文教程
4、BBuf/tvm_mlir_learn
BBuf的学习笔记
本文来自博客园,作者:暴力都不会的蒟蒻,转载请注明原文链接:https://www.cnblogs.com/BobHuang/p/17804600.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号