高层级综合(high-level-synthesis,HLS)编译
高层次综合(High-level Synthesis)简称HLS,指的是将高层次语言描述的逻辑结构转换成低抽象级语言描述的电路模型的过程。也是当前ASIC或FPGA设计最为普遍使用的电路建模和描述方法。
更一些背景吧,两篇文章可以看看 HLS:硬件开发软件化 、 基于高层次综合(HLS)的快速生成数字电路设计
一、赛灵思 HLS
github地址 https://github.com/Xilinx/HLS,赛灵思被AMD收购了,这个 Organization 现在挂的是AMD logo
HLS开源实现 https://github.com/Xilinx/hls-llvm-project/tree/2022.2
直接运行 ./build-hls-llvm-project.sh 即可,如果你资源实在有限,可以修改下 line39 将 -DCMAKE_BUILD_TYPE 设置为 Release,也可以选择编译特定的Target 添加 -DLLVM_TARGETS_TO_BUILD="FPGA",默认是全部编译,这是我成功的结果
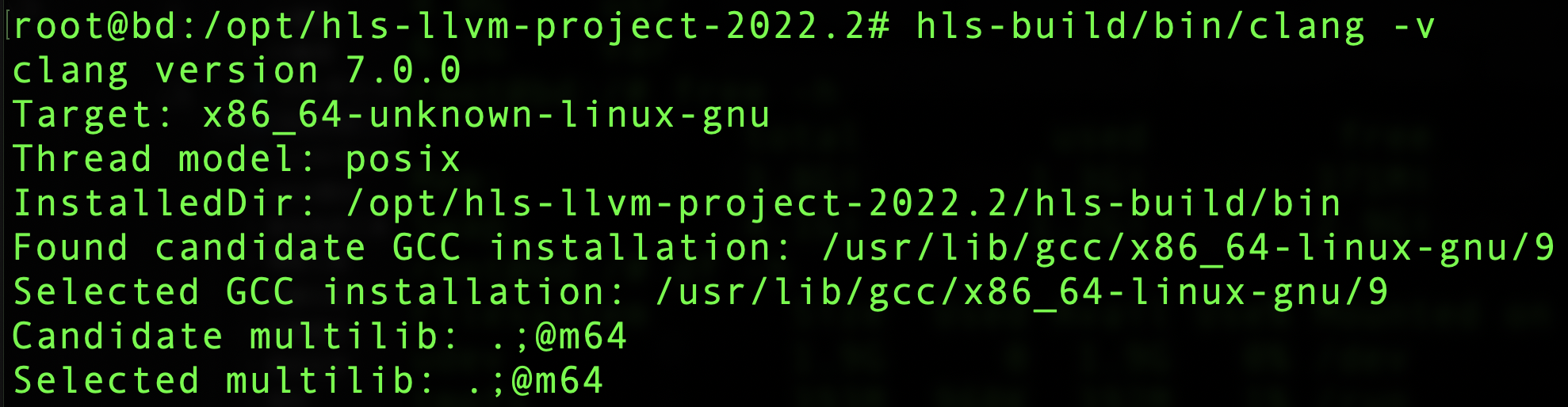
这个clang版本还是比较低的,才7.0.0,查询 LLVM Release 日志是19 Sep 2018 发布的,13 June 2023 已经更新到 16.0.6 了,原则上来说是看新不看旧,因为LLVM更新得还是很快的,版本差异也会比较大。
clang 是可以用的,但是它是怎么从 .cpp 到 fpga-hdl 还没搞清楚。clang前端有个编译选项是-fhls,编译出来的IR做了较多的特殊处理,比如打上 !dbg 标签,后面还有非常多的 元数据(Metadata),形如 !0、!1之类的。.cpp里会使用 #pragma HLS 预处理指令来标记。

其数据流如上图所示,所以生成IR之后应该用OPT工具走相应的PASS。clang-tools-extra 内还定义了两个工具 xilinx-legacy-rewriter 和 xilinx-dataflow-lawyer。
我跑了一下
/opt/hls-llvm-project-2022.2/hls-build/bin/xilinx-dataflow-lawyer /opt/hls-llvm-project-2022.2/clang-tools-extra/test/xilinx-dataflow-lawyer/xilinx-dataflow-lawyer-2.cpp -- -fhls -fstrict-dataflow
输出了以下结果
Since the loop counter is not declared in loop header and/or initialized to '0', the compiler may not successfully process the dataflow loop
Either use an argument of the function or declare the variable inside the dataflow loop body
Since the only kind of statements allowed in a canonical dataflow region are variable declarations and function calls, the compiler may not be able to correctly handle the region
Since the only kind of statements allowed in a canonical dataflow region are variable declarations and function calls, the compiler may not be able to correctly handle the region
Since the only kind of statements allowed in a canonical dataflow region are variable declarations and function calls, the compiler may not be able to correctly handle the region
There are a total of 4 such instances of non-canonical statements in the dataflow region
Static scalars and arrays declared inside a dataflow region will be treated like local variables
Either use an argument of the function or declare the variable inside the dataflow loop body
Either use an argument of the function or declare the variable inside the dataflow loop body
Since the only kind of statements allowed in a canonical dataflow region are variable declarations and function calls, the compiler may not be able to correctly handle the region
Since the only kind of statements allowed in a canonical dataflow region are variable declarations and function calls, the compiler may not be able to correctly handle the region
Since the only kind of statements allowed in a canonical dataflow region are variable declarations and function calls, the compiler may not be able to correctly handle the region
There are a total of 5 such instances of non-canonical statements in the dataflow region
13 warnings generated.
后端还有个 -fpga-hdl-syntax={verilog|vhdl|systemc}选项,llc不认这个选项,也没在LLVM中看到这个选项的相关代码,我的理解是其部分实现在其 Xilinx Vitis HLS 中,跟其vivado也会深度绑定的。通过运行 vitis_hls run_hls.tcl 才可以看到其 LLVM 的调用流程,因为我也是看别人vivado 的 log 发现了-fhls选项,然后在clang源码中得到了确认。
所以内容都潜藏在Vitis中,100G左右,自己可以下载跑一下。
二、北大Hector
论文发表在ICCAD 2022 HECTOR: A Multi-Level Intermediate Representation for Hardware Synthesis Methodologies,Github开源地址 https://github.com/pku-liang/Hector
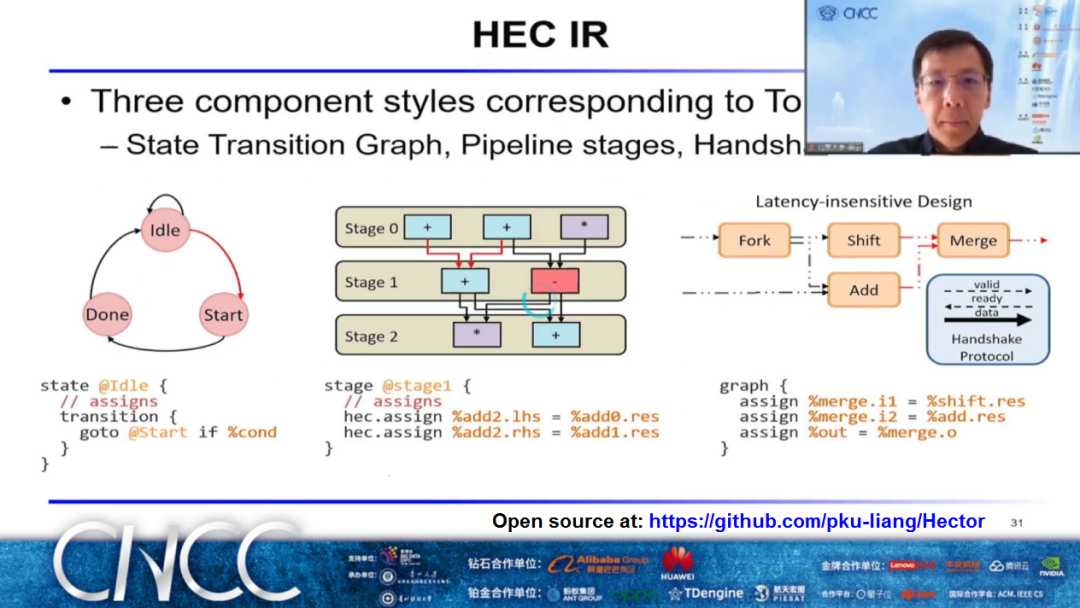
北京大学长聘副教授/研究员、北大-商汤智能计算联合实验室梁云主任做了基于多层中间表示的敏捷硬件综合的报告。梁云主任在报告中提出了通用的基于多层中间表示的敏捷硬件综合框架Hector,采用该框架可以显著降低硬件开发成本,缩短设计周期。基于多级的中间表示(Multi-Level Intermediate Representation,MLIR)的Hector框架实现,灵活,易于扩展,可复用,并支持不同的硬件综合技术。在报告最后,梁云主任强调Hector的代码已经开源。
来源:https://www.ccf.org.cn/Media_list/cncc/2022-12-28/783068.shtml
硬件综合需要一个复杂的过程来生成可综合的寄存器传输级设计代码。梁云课题组提出Hector,一种为硬件综合方法提供统一抽象的两层级硬件中间表示。高层语言将计算与带有时序信息的控制图结合起来,而低层语言提供了一种简洁的方式来描述硬件模块和互连。Hector实现在多层中间表示框架(MLIR)上,最终可以被转换为可综合的硬件设计。为了证明其表达能力和通用性,在Hector的基础上实现了三种硬件综合方法:高层次综合工具、脉冲阵列生成器和硬件加速器模块。基于Hector的高层次综合方法可以得到与最先进的工具生成的硬件性能相当,其他两种方法在性能和生产效率方面均超过了高层次综合方法。该工作以《HECTOR: A Multi-level Intermediate Representation for Hardware Synthesis Methodologies》为题发表(博士生徐瑞帆为第一作者)。
来源:https://ic.pku.edu.cn/xwdt/c0df7a2bb65e463eb3178d5bc5398b72.htm
作者自己的presentation
本项目涉及的paper HECTOR: A Multi-Level Intermediate Representation for Hardware Synthesis Methodologies 我还没下载到,之后有机会拜读一下。(更:已经读到,并且已跟随上大佬的脚步)
其依赖于 llvm-project 1c10201d9660c1d6f43a7226ca7381bfa255105d
进入到llvm-project/build后安装MLIR
cmake -G Ninja ../llvm \
-DLLVM_ENABLE_PROJECTS=mlir \
-DLLVM_BUILD_EXAMPLES=ON \
-DLLVM_TARGETS_TO_BUILD="Native;NVPTX;AMDGPU" \
-DCMAKE_BUILD_TYPE=Release \
-DLLVM_ENABLE_ASSERTIONS=ON \
# -CMAKE_C_COMPILER_LAUNCHER=ccache -DCMAKE_CXX_COMPILER_LAUNCHER=ccache \
# -DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++ -DLLVM_ENABLE_LLD=ON
# Using ccache, clang and lld speeds up the build, if you don't need please remove
cmake --build . --target check-mlir
然后克隆本项目,再编译,呜呜呜,竟然完美跑起来了。以下是编译命令
export LLVM_DIR="/opt/llvm-project/"
cmake -G Ninja .. -DMLIR_DIR=$LLVM_DIR/build/lib/cmake/mlir -DLLVM_EXTERNAL_LIT=$LLVM_DIR/build/bin/llvm-lit
ninja
这个项目竟然被我轻松跑起来了,Hector nb, xuruifan nb。
Xilinx/HLS 使用的是 LLVM IR,Hector 使用的是 MLIR,其中ML指 Multi-Level。(OpenCL 走的是SPIR-V,它其实和 LLVM IR 类似,同样是由控制流、基本块、以及静态单赋值来表示程序,还加入了对很多 GPU 概念的原生支持,比如 address space、builtins 以及特殊的指令,我们此时的粒度还是指令。)MLIR 提供基础设施来帮助定义 operation 以及将逻辑相关的 operation 组合成 dialect,更抽象,如果在此层就通过PASS对MLIR进行优化,他也能很方便的转换为LLVM IR。经过后端再走一遍就行了,所以OpenAI抛弃了CUDA C后triton也到达了一个比较好的水平,而且开发算子也简单了许多,Pytorch 2.0这次更新确实有点东西。
Hector的理念其实就是各种各样的 Pass 去解决 HLS 产生的调度以及资源约束问题,力求通过循环展开、循环流水化、内存划分等手段去媲美手动设计的RTL代码。调度时还有lp_solve(开源线性规划求解器)的lprec
在 Hector 的代码中我们可以看到 hector-opt/hector-opt.cpp:34 插入了两种方言,并将Pass注入了进去
registry.insert<mlir::tor::TORDialect>();
registry.insert<mlir::hec::HECDialect>();
mlir::registerTORPasses();
mlir::registerHECPasses();
include/HEC/HECDialect.h 是依赖于其.td文件(TableGen)自动生成的信息的,这是LLVM中非常好的设计,记录的就是一些描述信息。
#ifndef HEC_DIALECT_H
#define HEC_DIALECT_H
#include "HEC/LLVM.h"
#include "mlir/IR/Dialect.h"
#include "mlir/IR/BuiltinAttributes.h"
namespace mlir
{
namespace hec
{
} // namespace hec
} // namespace mlir
// Pull in the dialect definition.
#include "HEC/HECDialect.h.inc"
// Pull in all enum type definitions and utility function declarations.
#include "HEC/HECEnums.h.inc"
#endif // HEC_DIALECT_H
include/HEC/HECDialect.td 中定义了要真正使用的 HECDialect
#ifndef HEC_DIALECT_TD
#define HEC_DIALECT_TD
include "mlir/IR/OpBase.td"
def HECDialect : Dialect {
let name = "hec";
let summary = "Types and operations for hec dialect";
let description = [{
This dialect defines the 'hec' dialect, which ...
}];
let cppNamespace = "::mlir::hec";
let extraClassDeclaration = [{
/// Register all hec types.
void registerTypes();
}];
}
class HECOp<string mnemonic, list<OpTrait> traits = []> :
Op<HECDialect, mnemonic, traits>;
#endif // HEC_DIALECT_TD
HEC中Pass定义了三个,分别是GenPass、DumpChiselPass、DynamicSchedulePass,我猜测他们的行为是
- 分别为生成HEC相关的信息,比如时间、寄存器、memory信息
- 转换为Chisel时序电路
- 根据生命周期以及latency延迟等相关信息的调度
#ifndef HEC_PASSES_H
#define HEC_PASSES_H
#include "mlir/Pass/Pass.h"
#include <limits>
namespace mlir
{
std::unique_ptr<OperationPass<mlir::ModuleOp>> createHECGenPass();
std::unique_ptr<OperationPass<mlir::ModuleOp>> createDumpChiselPass();
std::unique_ptr<OperationPass<mlir::ModuleOp>> createDynamicSchedulePass();
#define GEN_PASS_REGISTRATION
#include "HEC/Passes.h.inc"
}
#endif // HEC_PASSES_H
Tor里面Pass有点多,有6个Pass,SCF我猜一手 sequential control flow(更:其实是Structured control flow结构化控制流,了解下MLIR就知道了),PipelinePartitionPass 很可能是做流水线切分的,这在GPGPU中也挺难的
#ifndef TOR_PASSES_H
#define TOR_PASSES_H
#include "mlir/Pass/Pass.h"
#include "TOR/TOR.h"
#include <limits>
namespace mlir
{
std::unique_ptr<OperationPass<mlir::tor::DesignOp>> createTORSchedulePass();
std::unique_ptr<OperationPass<mlir::ModuleOp>> createTORPipelinePartitionPass();
std::unique_ptr<OperationPass<mlir::ModuleOp>> createTORSplitPass();
std::unique_ptr<OperationPass<mlir::ModuleOp>> createTORCheckPass();
std::unique_ptr<OperationPass<mlir::tor::DesignOp>> createSCFToTORPass();
std::unique_ptr<OperationPass<mlir::tor::DesignOp>> createWidthAnalysisPass();
#define GEN_PASS_REGISTRATION
#include "TOR/Passes.h.inc"
}
#endif // TOR_PASSES_H
实际上这个项目是不是应该叫TorHec?先跑Tor生成与硬件无关的控制流,然后再跑Hec和硬件关联然后输出Chisel。
三、LLVM的circt
项目地址,CIRCT前端可以对接chisel,接口为firrtl格式
兆松(1nfinite)对这个东西还挺感兴趣的,有一些文章,社区有讨论。hongbin哥以前也来接触过,CIRCT llhd-sim工具分析。
参考
高层次综合:解锁FPGA广阔应用的最后一块拼图
ece6775-Level Digital Design Automation
编译器与中间表示: LLVM IR, SPIR-V, 以及 MLIR
paper
高层次综合综述
LLHD: A Multi-level Intermediate Representation for Hardware Description Languages
HECTOR: A Multi-Level Intermediate Representation for Hardware Synthesis Methodologies
parker liu bluespec和verilog相比有什么区别?
本文来自博客园,作者:暴力都不会的蒟蒻,转载请注明原文链接:https://www.cnblogs.com/BobHuang/p/17641737.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号