字节序学习:大端与小端
中年男人的浪漫 软路由+NAS,充电头。在给软路由部署alist(一个支持多存储的文件列表程序)的时候发现mips 是大端,需要专门下载mipsel小端变体,之前也了解到RISCV里也存在大小端的问题,我查看ELF程序往往是little endian。今天面试正好被问到了,我就来探究下这个问题。
虽然有自己的服务器,但是限制于服务器带宽和存储有限,软路由是局域网内好手,舒服的一批,我的软路由100多天没重启过,非常舒服。
大小端是什么chatgpt的例子给得很清晰

一、使用Linux指令查看cpu的大小端
1、lscpu 命令
使用 lscpu 我们能看到本台机器CPU,Byte Order行会看到

我的路由器
2、错误的命令 cat /proc/cpuinfo
chatgpt告诉我可能fflags可能会看到这些信息
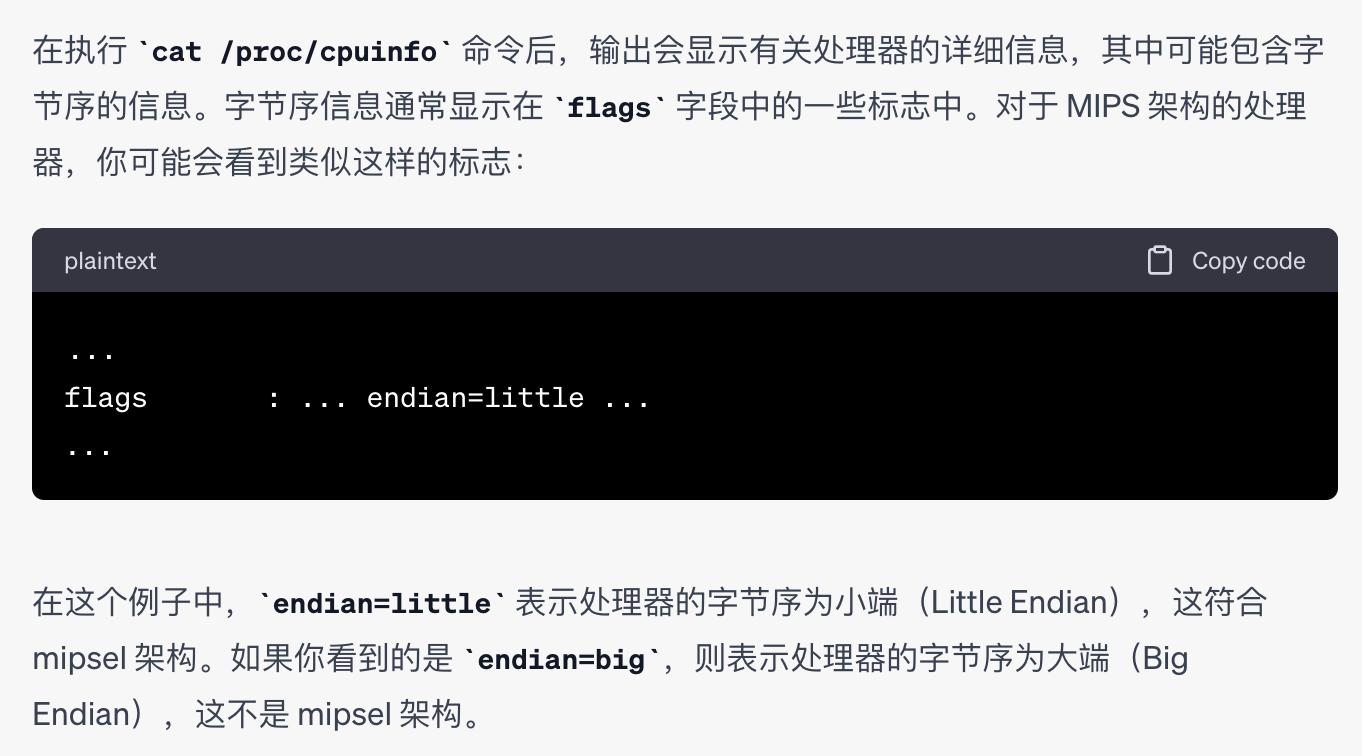
可是我的flags是如下这些,有些我是知道的,比如fpu就是浮点支持,pse就是页面大小扩,avx2就是向量指令集

其他的flags代码什么呢,有幸搜索到这样一篇文章,并给我提供了很好的思路,我们明明可以直接看linux kernel的代码的,比如 x86的 arch/x86/include/asm/cpufeatures.h ,mips arch/mips/include/asm/cpu-features.h 和x86都没有关于order的flags,翻阅了几个文件也没找到
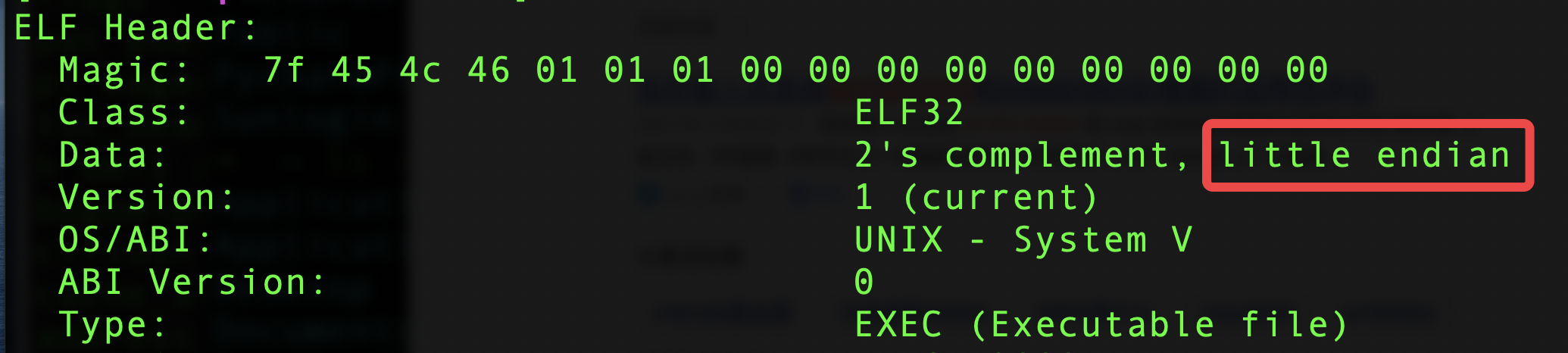
3、readelf 查看一个可执行文件
readelf 可以查看ELF文件,在header中的Data会有大端还是小端的标记,直接readelf 一定存在的ls看看
二、通过C程序查看
1、使用 stdlib.h 中 的 宏
#include <stdio.h>
#include <stdlib.h>
int main()
{
// 这两个宏是gcc或者clang支持的
if(__BYTE_ORDER__ == __ORDER_LITTLE_ENDIAN__)
puts("little endian");
else if(__BYTE_ORDER__== __ORDER_BIG_ENDIAN__)
puts("big endian\n");
else
puts("unknown");
return 0;
}
LLVM源码也用的这个
#if defined(BYTE_ORDER) && defined(BIG_ENDIAN) && BYTE_ORDER == BIG_ENDIAN
constexpr bool IsBigEndianHost = true;
#else
constexpr bool IsBigEndianHost = false;
#endif
2、使用 union 联合体
union 联合体内元素共用一块内存,我们可以设置一个char和int变量。大端和小端都指的是按字节的值,char 无论是大端和小端都一样,int的比如1一定不会相等
我本机的现象,Endian.half 的地址为 0x7fff5c09dbc4,half对应的是[0x7fff5c09dbc4, 0x7fff5c09dbc5) 这段内存,word 使用的是 [0x7fff5c09dbc4, 0x7fff5c09dbc8) 这段内存,我们修改 word 为1,如果是小端,也就是修改的小地址 [0x7fff5c09dbc4, 0x7fff5c09dbc5),所以相等就是小端。
#include <stdio.h>
void CheckEndian()
{
union check
{
int word;
char half;
} Endian;
Endian.word=1;
printf("%p\n", &Endian.half);
printf("%p\n", &Endian.half+1);
printf("%p\n", &Endian.word);
printf("%p\n", &Endian.word+1);
if(Endian.half == 1)
puts("little endian");
else
puts("big endian\n");
}
int main()
{
CheckEndian();
return 0;
}
3、 在编译时检查字节序 错误
使用 constexpr 关键字特性, 这个编译后就知道结果了。代码来源,这个是错误的,不借助宏or运行不可能完成
#include <stdio.h>
#include <stdint.h>
/**
* hl_endianness
*
* This enumeration can be placed into templated objects in order to generate
* compile-time code based on a program's target endianness.
*
* The values placed in this enum are used just in case the need arises in
* order to manually compare them against the number order in the
* endianValues[] array.
*/
enum hl_endianness : uint32_t {
HL_LITTLE_ENDIAN = 0x03020100,
HL_BIG_ENDIAN = 0x00010203,
HL_PDP_ENDIAN = 0x01000302,
HL_UNKNOWN_ENDIAN = 0xFFFFFFFF
};
/**
* A constant array used to determine a program's target endianness. The
* values
* in this array can be compared against the values placed in the
* hl_endianness enumeration.
*/
static constexpr uint8_t endianValues[4] = {0, 1, 2, 3};
/**
* A simple function that can be used to help determine a program's endianness
* at compile-time.
*/
constexpr hl_endianness getEndianOrder() {
return
(0x00 == endianValues[0]) // If Little Endian Byte Order,
? HL_LITTLE_ENDIAN // return 0 for little endian.
: (0x03 == endianValues[0]) // Else if Big Endian Byte Order,
? HL_BIG_ENDIAN // return 1 for big endian.
: (0x02 == endianValues[0]) // Else if PDP Endian Byte Order,
? HL_PDP_ENDIAN // return 2 for pdp endian.
: HL_UNKNOWN_ENDIAN; // Else return -1 for wtf endian.
}
constexpr hl_endianness endianness = getEndianOrder();
/*
* Test program
*/
int main() {
switch (endianness) {
case HL_LITTLE_ENDIAN: {
puts("little endian");
break;
}
case HL_BIG_ENDIAN: {
puts("big endian");
break;
}
case HL_PDP_ENDIAN: {
puts("pdp endian");
break;
}
case HL_UNKNOWN_ENDIAN:
default: {
puts("unknown");
break;
}
}
}
我们可以使用-S 选项查看编译后的结果

只剩 little endian 的字符串了,编译器帮我们处理了这些东西
三、为什么要设计大端字节序
当然我们看到的大多数设备都是小端,他的操作更高效,比如计算、比较、向量化操作。
1、历史原因
大端字节序在早期计算机系统中较为常见,例如 Motorola 68000 系列处理器就使用了大端字节序。一些系统仍然沿用这种传统,以保持与过去的兼容性。
2、对人类友好
大端字节序将最高有效字节放在最前面,与我们书写习惯一致。如果是大端就可以看到00010203,小端看到的是03020100,还需要倒置
#include <stdio.h>
union str2int
{
int word;
char half[4];
} Endian;
int main()
{
Endian.half[0] = '\0';
Endian.half[1] = '\1';
Endian.half[2] = '\2';
Endian.half[3] = '\3';
printf("%08x\n", Endian.word);
return 0;
}
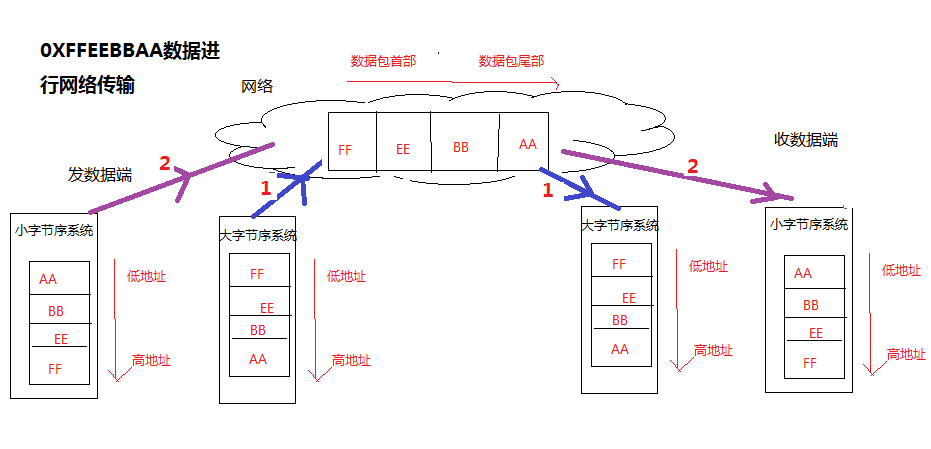
3、网络协议
大多数网络协议都采用大端字节序,这主要是因为大端字节序可以避免字节序转换带来的性能损失。如果在传输过程中需要进行字节序转换,会增加CPU的工作负荷,降低系统性能。此外,像TCP/IP协议,网络数据包都是先传输头部信息,然后再传输数据。采用大端字节序可以使头部信息的数据大小和起始位置固定,方便处理。
4、硬件架构
某些硬件架构使用大端字节序,如果在这些架构上进行开发,使用大端字节序可以更好地匹配硬件的存储方式,提高效率。
5、数据校验
chatgpt如是说,在某些情况下,使用大端字节序可以使数据校验更加简单,因为校验和的计算可能依赖于数据的排列顺序。我认为就是3网络协议带来的
本文来自博客园,作者:暴力都不会的蒟蒻,转载请注明原文链接:https://www.cnblogs.com/BobHuang/p/17636463.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号