第一次个人编程作业
https://github.com/B1usher/SensitiveWordFilter
一、PSP表格
- 在开始实现程序之前,在附录提供PSP表格记录下你估计将在程序的各个模块的开发上耗费的时间。
- 在你实现完程序之后,在附录提供的PSP表格记录下你在程序的各个模块的开发上实际花费的时间。
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 15 | 15 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 240 | 300 |
| · Design Spec | · 生成设计文档 | 30 | 40 |
| · Design Review | · 设计复审 | 20 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 120 | 240 |
| · Coding | · 具体编码 | 1200 | 1500 |
| · Code Review | · 代码复审 | 60 | 100 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 180 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 60 | 90 |
| · Size Measurement | · 计算工作量 | 20 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 100 | 180 |
| · 合计 | 1995 | 2685 |
二、计算模块接口
- 1、计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。
包含的类
1.答案类Answer:用于存储最终输出的内容
2.前缀树节点类TreeNode包含的函数
1.读入汉字对应偏旁部首词库的函数readDictionary():读入字典文件,并将汉字和它的拆分用map关联起来
2.读入敏感词的函数readMgc():读入敏感词文件,并调用构造前缀树的函数createTree()
3.构造前缀树的函数createTree():关键函数
4.读入待检测文本的函数readFile():读入待检测文本,并调用搜索敏感词的函数searchMgc()
5.搜索敏感词的函数searchMgc():关键函数,并保存已检测到的答案
6.输出答案的函数writeFile():输出答案文件心路历程
一开始看到题目,自然是去网上搜索方法,找到了像是前缀树算法、AC自动机、DFA算法等方法,可是都看不懂。GitHub上的项目基本都是用Python和Java写的,可是不会呀(
在学了在学了),一行行代码看的头痛。也不是没想过用遍历暴力搜索,但是总感觉遍历会超时。最终找了一个带图的前缀树?算法教程(链接),好歹是能理解一点了,就用自己的想法实现了下(大框架是用他的,但具体写的时候大多都是自己写的函数所以看起来有点low)。具体实现
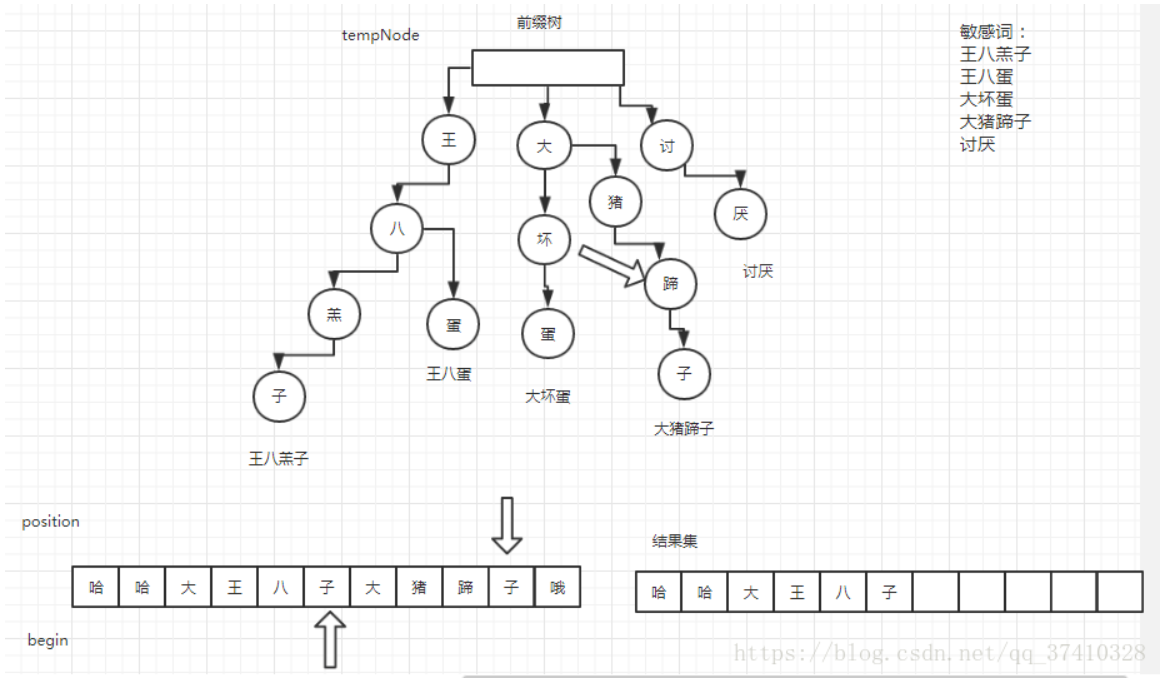
贴一张教程中的图
大致思路就是将读入的敏感词构造成一棵前缀树,再读入待检测文本从树根处开始检测。就是说我只要能构造出一棵包含所有情况的前缀树,再写一个按一定顺序和规则搜索的检测函数,就能实现所有类型的敏感词检测!!但对于我这样的菜鸟来说实现起来真的不容易,很多东西都要先查先学,光文件读入、输出就调了好久。
第一个关键点如何是创建前缀树
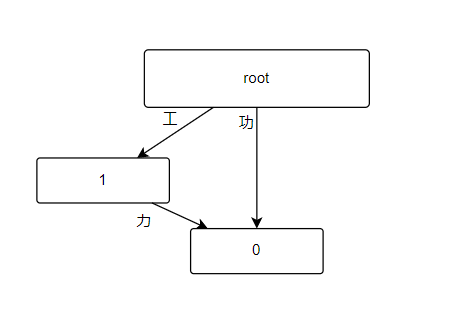
我的想法是用map将敏感词和树节点关联起来。若敏感词是中文(写代码过程中发现他们每一位都是小于0的),就将输入字符串s的3位合并起来(Utf-8编码)一开始是分为3份,后来改了下;若是英文就是正常一位。然后用一个tempNode指针指向每一步的父节点,一步步用map关联起来。后来添加了偏旁部首变形的功能,就是在创建前缀树时,若是中文就寻找一下偏旁部首的词库,另加一条相同起点、终点的路径,如下图。
虽然我没能实现有关拼音的变形,但我认为如果我能将汉字和拼音关联起来(这里就卡住了),像汉字和偏旁部首一样,用一定规则构造前缀树(为了后续检测方便和不出现重复检测等错误),那样就OK了。
第二个关键点是搜索函数的编写
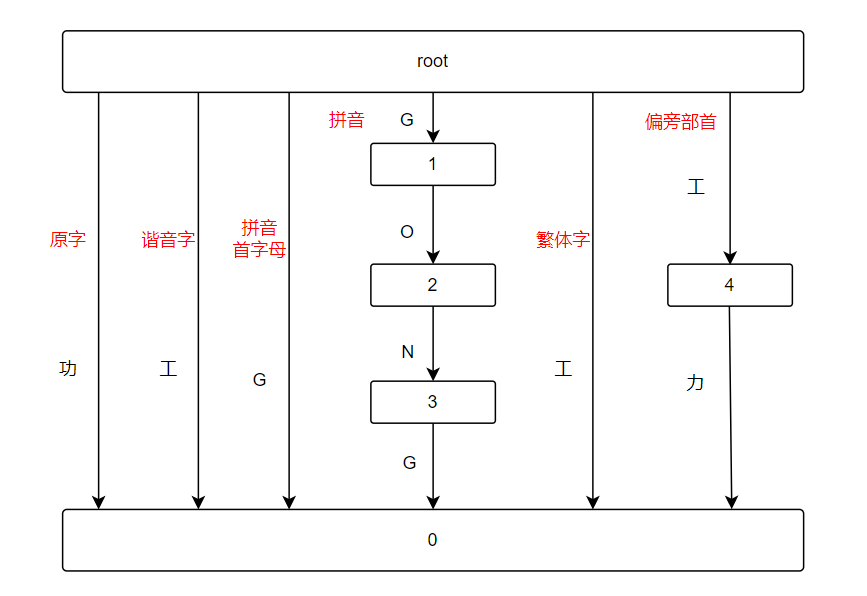
下图为我画的可能需要考虑的情况的图
先说我实现的部分,依旧是分为中文和英文来考虑,其他数字和字符按题目要求在过程中忽略或直接结束。用begin来标记正在检测文本的开头,用position来标记正在检测的那一位(由于中英文分别为3位和1位构成,中间还有不同,都使用一位的说法)。如果找到和begin那一位相同开头的敏感词(树根的子节点),position则从begin这一位开始往后搜索,若position搜索到叶节点(节点类中有一个is_End的数据成员),则保存答案,begin变为position下一位。
可是从上图中可以看到,若引入拼音(谐音字,繁体字应该都能转换成拼音,用map?),就会出现许多问题:
1.读到英文文本时,是要寻找英文敏感词,还是寻找中文敏感词的拼音,若是同时用一个中文敏感词“功”(gong)和英文敏感词“Geek”。我的想法是能不能设计一个回溯函数,多给几次检测机会。
2.拼音和拼音首字母的冲突问题。我的想法是创建前缀树时,将拼音首字母G的路径不指向节点0,而是从拼音这条路径的节点1指向可能存在的节点0的子节点;或者在搜索函数上入手,也回溯一下。
3.汉字的偏旁部首和谐音字存在相同问题,如敏感词“功”的偏旁部首“工力”和其谐音字“工”。我的想法是都转为拼音先检测,可以多次回溯,同时可以设置一个顺序来减少浪费。虽然我没能将所有功能实现,但还是想了一些要是继续实现可能遇到的问题,要是未来学习了一些知识,跨越了目前的这道坎,也能有一个接下去的规划。
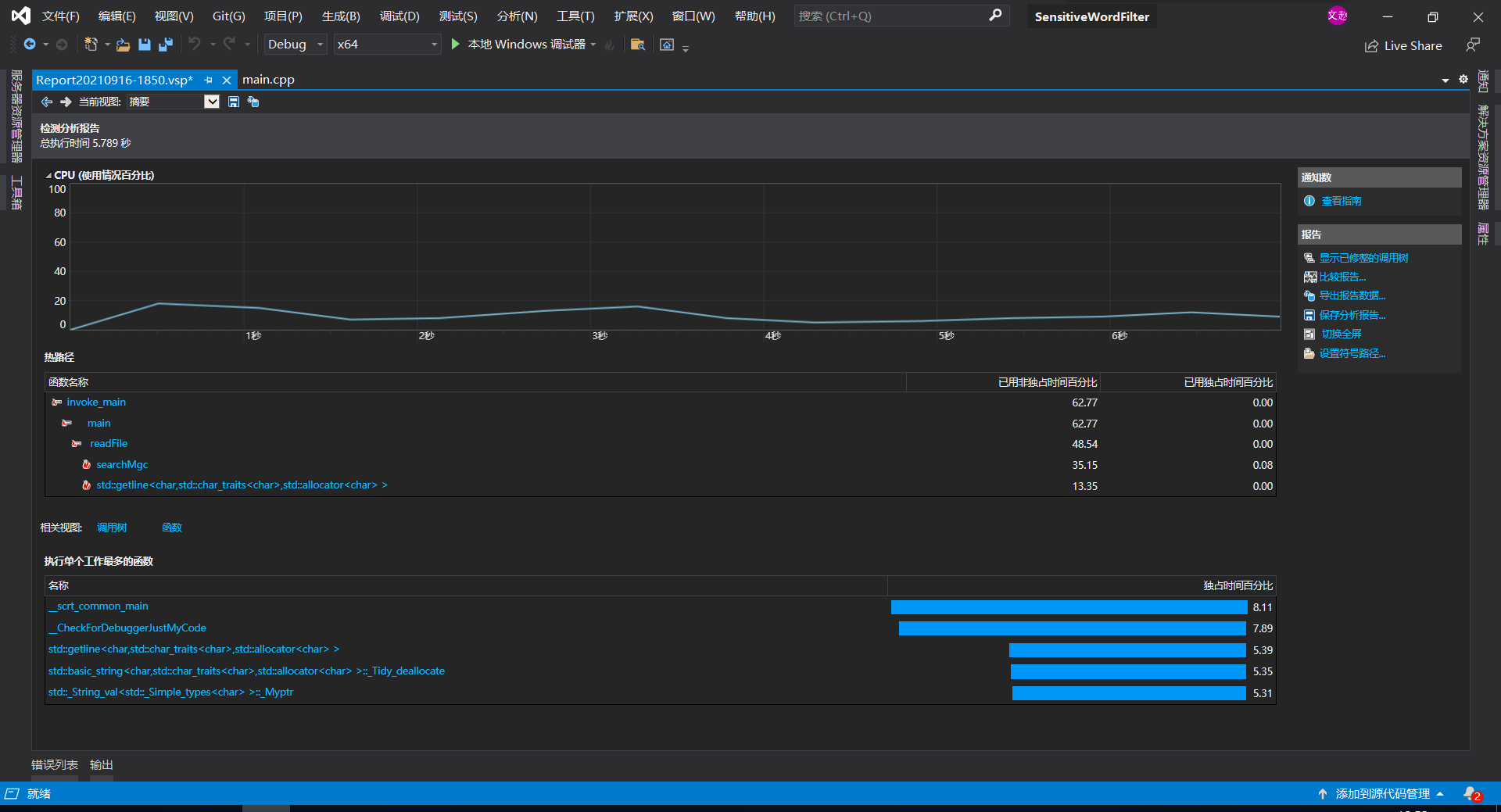
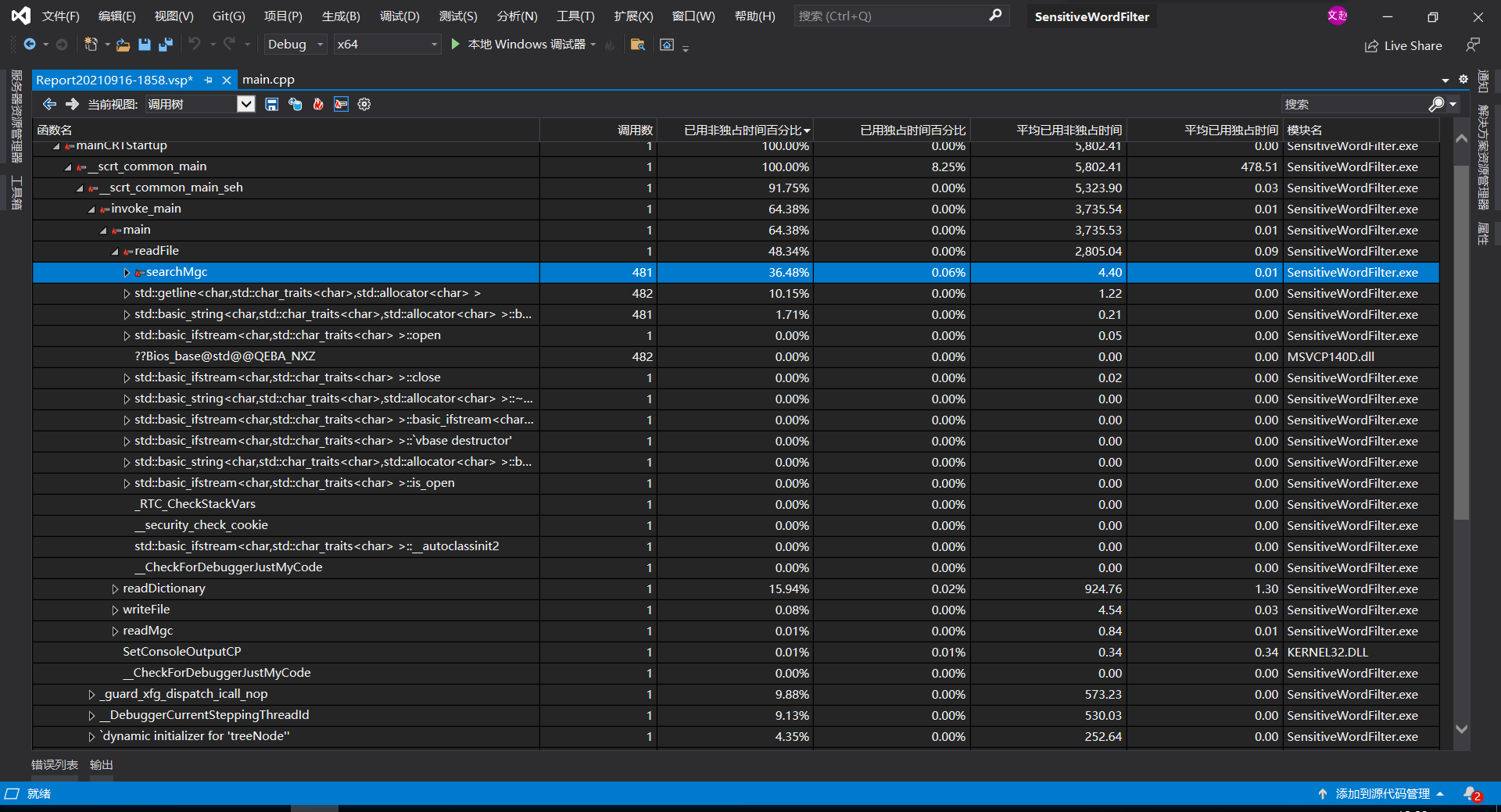
- 2、计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2019、JProfiler或者Jetbrains系列IDE自带的Profiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。
下图可以看到消耗最大的函数是从文本中搜索敏感词的函数searchMgc(),也在预料之中吧,毕竟几乎要遍历整个文本
写代码的时候也有意考虑如何加快检测速度,一开始创建前缀树时我是将用一位char来关联树节点,这样一个汉字就要搜索3位。后来我改成用string来关联,遇到中文直接合并后两位,搜索函数中也改为通过string寻找对比,目的是跳过汉字的3次搜索。还有一些改动,在代码的时候感觉很牛,花了很多时间,但现在回过头来看,还是自身能力开始不足(
现在也没有足)导致的错误,像是一开始在使用tempNode时定义为对象,一直没指向正确的节点,中间想了好久,最终改为定位为指针才可以了。
- 3、计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。
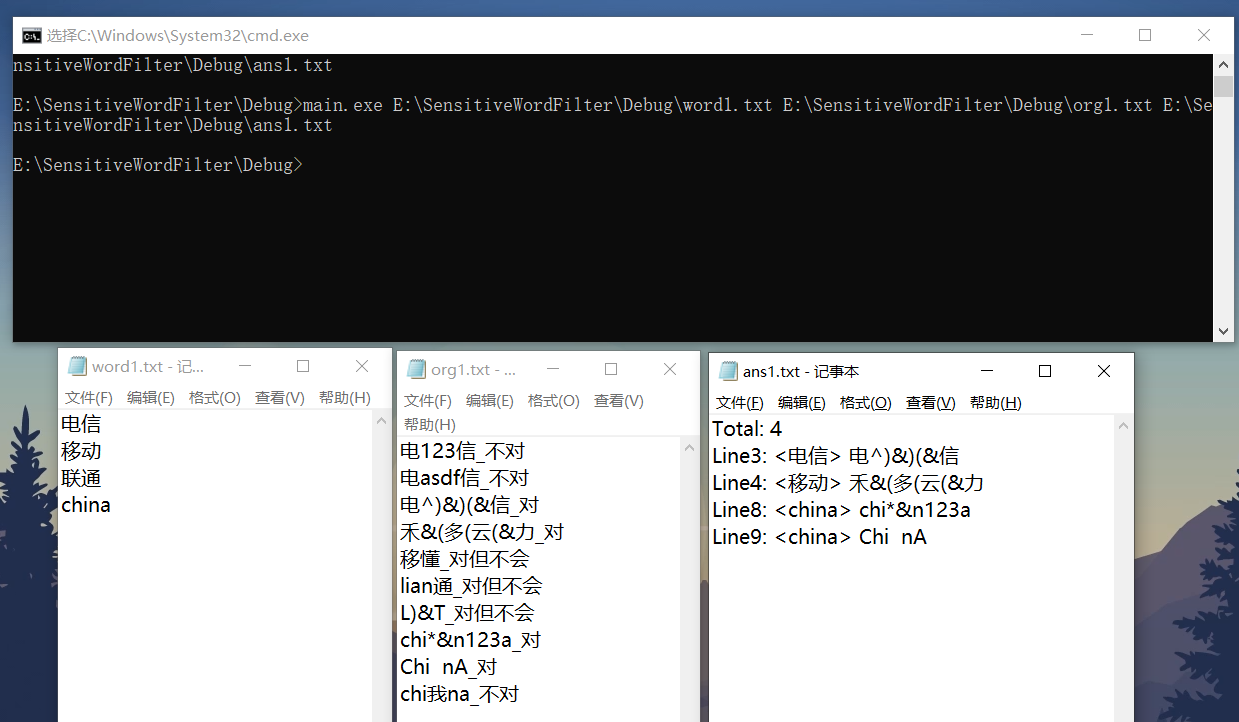
VS2019的单元测试不会用,就只能自己手打一些来测试了
用GitHub来和标答比较,可以看到就是差拼音变形的情况了。
添加了偏旁部首的检测后,只多了几个......
在实际写代码的时候其实我也有加上一些cout来观察某个函数功能是否正常实现,出现问题时也会逐行编译调试时也会看VS2019的有关窗口,但如何使用单元测试不知道怎么实现,只能先这样了。

- 4、计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。
1.在一开始读入、输出文件测试时,cout出来的字符串都是乱码。后来添加了“SetConsoleOutputCP(65001);”代码将命令行设置为Utf-8编码就可以了,同时也知道了Utf-8编码中的汉字是3字节而不是2字节,为后续函数书写埋下伏笔。
2.命令行输入时不知道为什么不能直接“ifstream inMgc(words);”,最终改为“ifstream inMgc;inMgc.open(words);”就可以了。
3.在实现偏旁部首变形时,构造前缀树时,rootNode通过“功”指向子节点0,在写另一条路径时写成了rootNode从“工”到节点1,节点1从“力”到节点2,再连接节点2和节点0,无法正确实现;后改为节点1从“力”直接到节点0。
三、心得
- 在完成本次作业过程的心得体会
意识到自身有许多不足,甚至连使用VS2019这个工具都不熟练,一开始研究Github和VS2019配合使用就花了好久。平时写代码的习惯也不是很好,很多时候都是写到最后发现有更合适的方法,最后又改半天,要是一开始能完整的设计出开发的路线(这个应该不容易),那么开始写的时候就有个大体的方法。还有就是看到大多同学都是用Python写的程序,让我有种难过的感觉(
抄也没地方抄),大伙都会我不会,这就计划着去学了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号