
scrapy安装与使用
scrapy是python的一个爬虫框架,从网上随意搜索便能得到千篇一律的使用demo(本文也是哟),并且非常容易理解。即便你没看过相关的demo,也一样可以食用本文。我的应用场景大多是列表页,文章页等。如果你的业务需要登录验证,图片验证等,请另寻他法,不要在本篇文章浪费你宝贵的时间。由于我的代码编写,运行几乎都在vscode里进行,所以不同的编辑器可能会有一些差异。
准备:请确保你安装了python,scrapy。
pip install scrapy
win环境下scrapy安装时可能会出现twisted相关的报错问题,点此下一个对应版本的twisted到本地,并在下载目录下用命令行运行如下命令安装twisted(xxxxx是你下载的twisted完整文件名):
pip install xxxxx
完成安装工作后,打开任意一个文件夹,命令行步进到该文件夹路径下,运行如下命令新建一个项目(请注意:执行命令本质上都是绝对的,这意味着你应该也要这样做。所以如果不是很熟悉对应的框架、文件结构、配置文件、文件内容等,不建议手动输出这些文件。如果为了加深印象,你也应该多敲几次这些命令,而不是力求记住那些文件结构,内容。在了解,学习时就这样做的话,会让你看上去有点憨。当然,实际上你可能什么也记不住,不过没关系,在你需要的时候,再去网上查找相关的资料也是完全没有问题的。):
scrapy startproject myScrapy
运行完成后会在当前目录下生成一个myScrapy文件夹。先看一下目录结构:
├─ myScrapy
│ ├─ scrapy.cfg
│ ├─ myScrapy
│ │ └─ items.py
│ │ ├─ middlewares.py
│ │ ├─ pipelines.py
│ │ ├─ settings.py
│ │ ├─ __init__.py
│ │ ├─ __pycache__
│ │ ├─ spiders
│ │ │ └─ __pycache__
│ │ │ ├─ __init__.py
现在,让我们先写一个简单的爬虫吧。
在项目根目录下运行如下命令(www.lypkb.cn是我的域名,由于域名商让必须挂个网站,所以随便下了个模板挂着......刚好可以做scrapy文章的爬取素材。):
scrapy genspider myTest www.lypkb.cn
在spiders目录下,已经生成了一个myTest.py,内容如下(start_urls里的路径结尾如果是/,若这个/不是请求必须的话,需要删除。我在parse方法下加了一行打印代码,response是爬取页面完成后返回的对象,打印它的text属性可以直观看到是否爬取到了数据):
# -*- coding: utf-8 -*-
import scrapy
class MytestSpider(scrapy.Spider):
name = 'myTest'
allowed_domains = ['www.lypkb.cn']
start_urls = ['http://www.lypkb.cn']
def parse(self, response):
self.log(response.text)
pass
接下来在项目根路径运行命令:scrapy crawl myTest,日志输出如下:
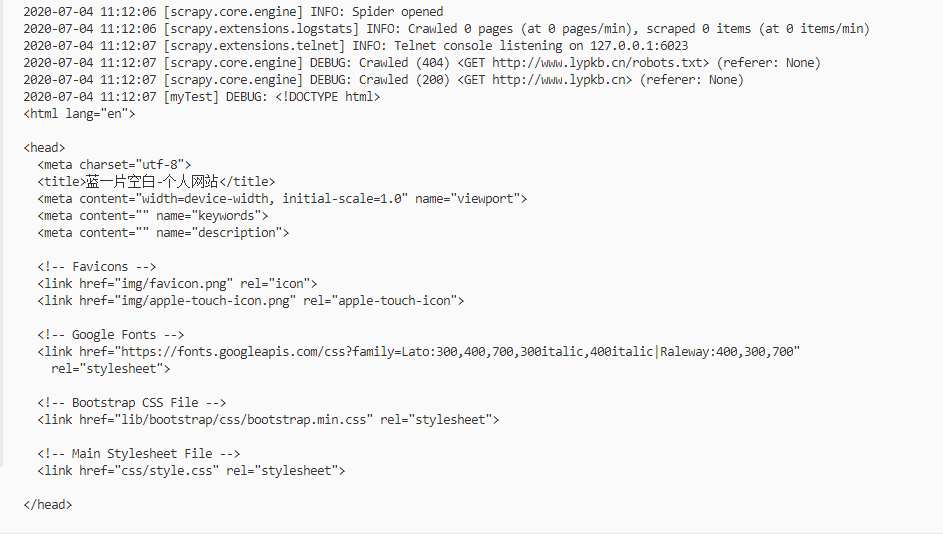
可以看到已经输出网站首页的代码。至此,scrapy已经完整的运行起来了。现在,尝试着获取一些爬取的网页上的信息吧(之后的内容需要需要读者掌握一些XPATH或者正则表达式的相关知识。)。修改一下上面的parse方法,获取网页的title和如下这个段落:
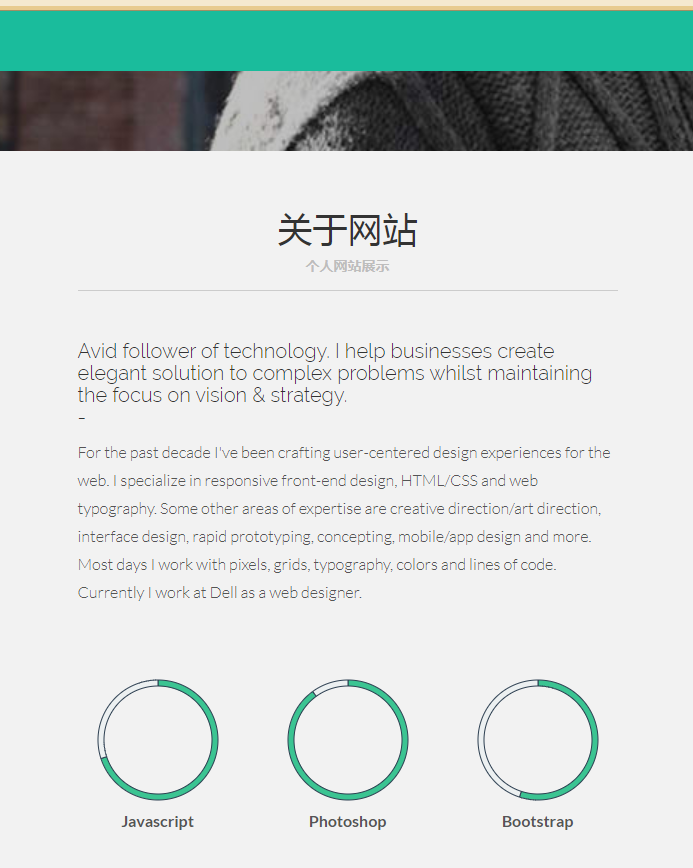
该段落浏览器源代码显示如下:

parse代码修改如下:
# -*- coding: utf-8 -*-
import scrapy
import re
class MytestSpider(scrapy.Spider):
name = 'myTest'
allowed_domains = ['www.lypkb.cn']
start_urls = ['http://www.lypkb.cn']
def parse(self, response):
print('#####################XPATH方式#########################')
# response提供xpath方法供xpath检索
titleXpath = response.xpath('//title/text()').extract()
print(titleXpath[0])
contentXpath = response.xpath(
'//div[@class="container about"]/div/h4/text()').extract()
contentXpath2 = response.xpath(
'//div[@class="container about"]/div/p/text()').extract()
print('{}\n{}'.format(contentXpath[0], contentXpath2[0]))
print('#####################正则表达式#########################')
text = response.text
# 正则表达式需要import re,通过re进行操作
parttenTitle = re.compile(r'<title>(.+)</title>')
print(parttenTitle.findall(text)[0])
parttenContent = re.compile(r'<h4>(.+\r\n.+)</h4>')
parttenContent2 = re.compile(r'<p>(.+\r\n.+\r\n.+\r\n.+\r\n.+)</p>')
content = parttenContent.findall(text)
content2 = parttenContent2.findall(text)
print('{}\n{}'.format(content[0], content2[0]))
pass
再次执行运行代码:scrapy crawl myTest,控制台输出如下:
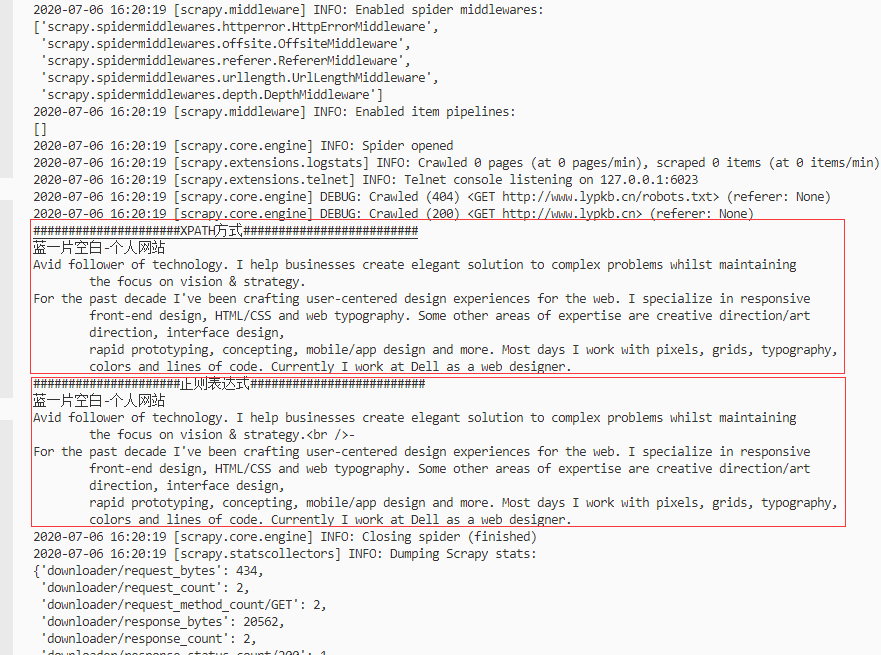
可以看到XPATH、正则都得到了几乎相同的数据。关于XPATH和正则,建议都掌握,虽然笔者正则很渣就是了。XPATH在获取层级明了的界面时绝对是非常直观明了的方式,可以很迅速的解决你的问题(这个过程甚至只需要1分钟)。但是XPATH也只能应对层级明了,比较简单的页面。大多数时候你需要得到的可能是某个段落里的值、拼接在js里的数据、通过转译字符包裹的文本等。本质上你可以通过XPATH取出这些段落然后用处理字符串的方式清洗掉你不需要的部分,但仔细想一想你操作字符串的代码的样子,我相信你已经吐了,如果多个网站,多种不同的业务逻辑,你的代码肯定会发展的臃肿冗长。这个时候正则就是你的杀手锏了,只要正则能力强,随便获取任意文本任意部分任意段落。但是笔者并不推荐都用正则,正则其实要花更多时间调试的(当然这也和个人正则水平有关,留下了正则水平很渣的泪水)。当然不管是正则还是XPATH,都要根据自己的业务需求来进行选择。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号