JVM五大知识点
1 JVM的基本特性
1.1 基于栈(Stack-based): 不同于Intel x86和ARM等比较流行的计算机处理器都是基于寄存器(register)架构,JVM是基于栈执行的。
1.2 符号引用(Symbolic reference): 编译后的.class文件中,除基本类型外的所有Java类型都是通过符号引用取得关联的,而非显式的基于内存地址的引用。
【符号引用以一组符号来描述所引用的目标,符号可以是任何形式的字面量。例如,在Class文件中它以CONSTANT_Class_info、CONSTANT_Fieldref_info、CONSTANT_Methodref_info等类型的常量出现。
在编译时,java类还没有被加载到内存中,所以并不知道所引用的类的实际地址,因此只能使用符号引用来代替;在解析阶段,Java虚拟机会把类的二进制数据中的符号引用替换为直接引用(指向内存地址)】
1.3 垃圾回收机制: 类的实例通过用户代码进行显式创建,但却通过垃圾回收机制自动销毁。
1.4 通过明确清晰基本类型确保平台无关性: 像C/C++等传统编程语言对于int类型数据在同平台上会有不同的字节长度。JVM却通过明确的定义基本类型的字节长度来维持代码的平台兼容性,从而做到平台无关。
1.5 网络字节序(Network byte order): 是TCP/IP中规定好的一种数据表示格式。Java class文件的二进制表示使用的是网络字节序,即基于big endian的字节序。
【字节序,即字节在电脑中存放时的序列与输入(输出)时的序列是先到的在前还是后到的在前。 Little endian:将低序字节存储在起始地址; Big endian:将高序字节存储在起始地址】
2.Java字节码在JVM中的运行
2.1 编译机制
Java字节码无法直接直接,需要JVM将其翻译成机器码。
在 HotSpot 里面,翻译过程有两种形式:第一种是解释执行,相当于同声传译,即每解析一条字节码,便翻译成机器码并执行;第二种是即时编译(Just-In-Time compilation,JIT),则相当于线下翻译,即将整个方法中所包含的字节码统一翻译成机器码后在执行。前者的优势在于无需等待编译,而后者的优势在于实际运行速度更快。
HotSpot 默认采用混合模式,综合了解释执行和即时编译两者的优点。它会先解释执行字节码,而后将其中反复执行的热点代码,以方法为单位进行即时编译。
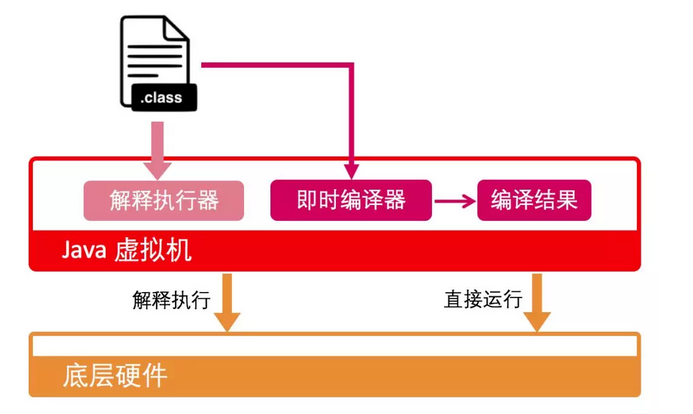
2.2 加载流程

执行 Java 代码首先需要将它编译而成的 class 文件加载到 Java 虚拟机的方法区中。实际运行时,执行引擎会执行方法区内的代码。每当调用一个 Java 方法,Java 虚拟机会在当前线程的 Java 方法栈中生成一个栈帧,用以存放局部变量以及字节码的操作数。这个栈帧的大小是提前计算好的,而且 Java 虚拟机不要求栈帧在内存空间里连续分布。当退出当前执行的方法时,不管是正常返回还是异常返回,JVM均会弹出当前栈帧,并将之舍弃。
3.加载Java类
JVM加载 Java 类的过程可分为三大步骤:加载、链接以及初始化。
3.1 加载
指通过类加载器查找字节流,创建类的过程。类加载器使用双亲委派模型,即接收到加载请求时,会先将请求转发给父类加载器。
3.2 链接
指将创建成的类合并至 JVM中,使之能够执行的过程。
链接还分验证(验证被加载类是否满足 JVM约束)、准备(为被加载类静态字段分配内存)和解析(将被加载类中的符号引用解析成为实际引用)三个阶段。其中,JVM规范并不要求解析阶段一定要在链接步骤中完成。
3.3 初始化
为常量赋值,以及执行 <clinit> 方法的过程。类的初始化仅会被执行一次,这个特性被用来实现单例的延迟初始化。
4.垃圾回收
垃圾回收器采用可达性分析来探索所有存活的对象。它从一系列根对象出发,标记所有被引用的对象。为了防止在标记过程中堆栈的状态发生改变,JVM采取STW(Stop-The-World) 操作,暂停其他非垃圾回收线程。
通常来说,JVM采用分代回收的思想,将堆划分为新生代和老年代,并且在不同代中应用不同的垃圾回收算法。新生代再划分为 Eden 区和两个大小一致的 Survivor 区。在Minor GC 中,Eden 区和非空 Survivor 区的存活对象会被复制到空的 Survivor 区中,当 Survivor 区中的存活对象复制次数超过一定数值时,它将被晋升至老年代。因为 Minor GC 只针对新生代进行垃圾回收,所以需要考虑从老年代到新生代的引用。为了避免扫描整个老年代,Java 虚拟机引入了名为卡表的技术,标出老年代对新生代引用的内存区域。
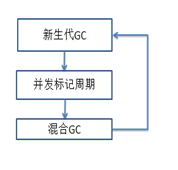
G1 垃圾回收器包含三个阶段(新生代GC、并发标记周期、混合GC);G1将堆划分为多个等大的区域,优先收集垃圾最多的区域,从而最大化垃圾回收的效益。
Java 11 中引入的实验性垃圾回收器 ZGC,仅在扫描可达对象时请求 Stop-The-World,暂停应用线程。因此,它宣称可将 GC 暂停时间控制在 10ms 以下。ZGC 暂时没有应用分代回收的思路,将整个堆空间看成一块,其代价是垃圾回收 CPU 消耗较高。
5.Java内存模式
在现代计算机系统中,代码通常不会按照书写顺序执行。造成这一情况的原因有三个,分别为编译器的重排序,处理器的乱序执行,以及内存系统的重排序。
以内存系统重排序为例,在多处理器体系架构下,每个处理器都可能缓存了一部分数据。由于时刻保持缓存数据与内存数据同步的性能代价太大,因此部分体系架构可能允许缓存数据与内存数据不同步。这对 Java 程序的影响便是,两个不同的 Java 线程在同一时间内看到的同一块内存地址中的值可能不同。
Java 内存模型是针对上述问题而提出的一套规范,用以允许 Java 程序员更为细致地定义 Java 程序的内存行为。它通过定义了一系列的 happens-before 操作,让应用程序开发者能够轻易地表达不同线程的操作之间的内存可见性。
在遵守 Java 内存模型的前提下,即时编译器以及底层体系架构能够调整内存访问操作,以达到性能优化的效果。如果开发者没有正确地利用 happens-before 规则,那么将可能导致数据竞争。
Java 内存模型是通过内存屏障来禁止重排序的。对于即时编译器来说,内存屏障将限制它所能做的重排序优化。对于处理器来说,内存屏障会导致缓存的刷新操作。
6. 参考文献
6.1 狼小战的博客《Java虚拟机必学之四大知识要点》
6.2 hello_史努比《java -- JVM的符号引用和直接引用》
6.3 百度百科《字节序》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号