MySQL技术内幕读书笔记(四)——表
表
表就是关于特定实体的数据集合,是关系型数据库模型的核心。
索引组织表
在INNODB存储引擎中,表都是根据主键顺序组织存放的。这种存储方式的表称为索引组织表。在INNODB存储引擎表中,每张表都有个主键,如果在创建表时没有显式地定义主键,则INNODB存储引擎会按如下方式选择或创建主键。
-
首先判断表中是否有非空的唯一索引,如果有,则该列为主键。
表中有多个非空唯一索引时候,引擎选择建表时第一个定义的非空唯一索引作为主键。

这个的主键是d。
对于主键只有一个的表,可以使用_rowid查询主键值
SELECT a,b,c,d,_rowid FROM z;
- 如果不符合上述条件,INNODB存储引擎自动创建一个6字节大小的指针。
InnoDB逻辑存储结构
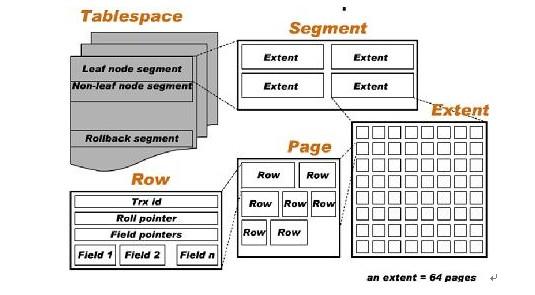
所有数据都放在表空间中。表空间又由段、区、页组成。
表空间
默认情况下,INNODB存储引擎有一个共享表空间ibdata1`,即所有数据存放在这个默认表空间。
通过参数innodb_file_per_table可以将每张表内的数据可以单独放到一个表空间内。但是单独表空间内存放的只是数据、索引和插入缓冲Bitmap页,其他类的数据,如回滚信息,插入缓冲索引页,系统事务信息,二次写缓冲等还是放在原来的默认空间。
段
常见的段有:数据段、索引段、回滚段等。
数据段是B+树的叶子节点,索引段是B+树的非叶子节点。
区
区是由连续页组成的空间,在任何情况下的大小都为1MB。但是页的大小可能不同。
但是有个问题???新创建的表默认大小是96K,区中是64个连续的页,创建表至少是1MB啊。其实因为在每个段开始时,先用32个页大小的碎片也来存放数据,在使用完这些页之后才是64个连续页的申请。目的是,对于一些小表或者undo这类的段,可以在开始时申请较少的空间,节省磁盘容量的开销。
页
是INNODB磁盘管理的最小单位。可以通过innodb_page_size将页的大小设置为4K、8K、16K。若设置完成,则所有表中页的大小都为innodb_page_size,不可以对其再次进行修改。除非通过mysqldump导入和导出操作来产生新的库。
常见页的类型:
- 数据页
B-tree Node - undo页
undo Log Page - 系统页
System Page - 事务数据页
Transaction system Page - 插入缓冲位图页
Insert Buffer Bitmap - 插入缓冲空闲列表页
Insert Buffer Free List - 未压缩的二进制大对象页
Uncompressed BLOB Page - 压缩的二进制大对象页
compressed BLOB Page
行
INNODB存储引擎是面向列的,也就是说数据是按行进行存放的
INNODB行记录格式
记录数据的行格式有两种:
- Compact:新版本
- Redundant:旧版本
# 通过这个,可以查看表使用的行格式,row_format表示行格式。 SHOW TABLE STATUS LIKE 'table_name';
Compact行记录格式

首部,是一个非NULL变长字段长度列表,并且其是按照列的顺序逆序放置的,其长度为:
-
列的长度小于255字节,用1字节表示
-
大于255个字节,用2字节表示
不可超过2字节,因为MYSQL数据库中VARCHAR类型的最大长度为65535.
NULL标志位“1”表示该行数据中有NULL值。
记录头信息,固定占用5字节(40位)
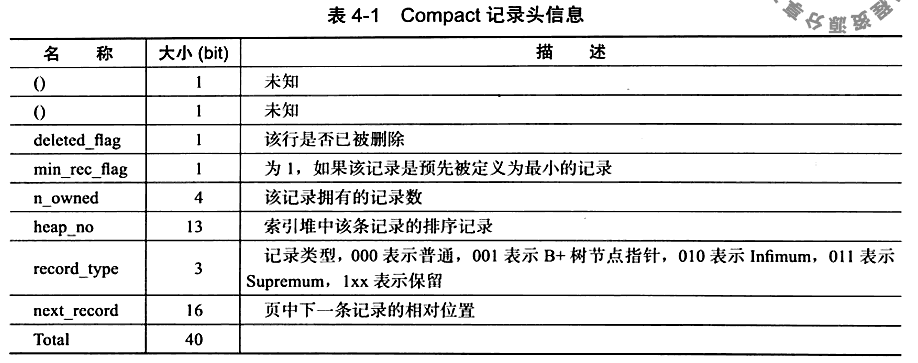
最后的部分是实际存储每个列的数据,NULL不占该部分的任何空间。还有两个隐藏列,事务ID列和回滚指针列。若没有主键,还会增加一个6字节的rowid列。
使用命令可以查看页内容
hexdump -C -v mytest.ibd > mytest.txt



Redundant行记录格式

首部是一个字段长度偏移列表,按照逆序排放。
记录头信息

最后就是列数据了。

行溢出数据
INNODB存储引擎可以将一条记录中的某些数据存储在真正的数据页面之外。
研究下VARCHAR数据类型的行溢出行为~
首先VARCHAR的长度官方说明为65535,但实际上创建表会报错,经测试,最大长度为65532。但是实际上数据库已经将VARCHAR转换为了TEST
但是注意使用的字符类型是latin1,如果改为GBK或者utf-8呢?
也会报错,说明VARCHAR(N)中的N是指字符的长度。且是整个表所有的列的超度综合不能超过N。
但是即使能够存放65532个字节,但是一个页只有16KB(16384字节),因此,在一般情况下,INNDB存储引擎的数据都是存放在页类型为B-tree node中。但是发生行溢出时,数据存放在页类型为Uncompress BLOB页中。对于行移除数据采用存放方式如图:
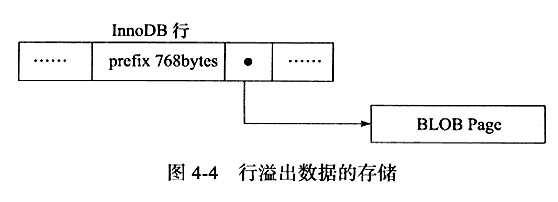
INNODB存储引擎表是索引组织的,即B+Tree机制,所以每个页至少要有两条行记录(否则回退成列表),这个阈值经过测试后是8098。
类比TEXT或者BLOB的数据类型,跟VARCHAR一致,8098长度之后的才存放在Uncompressed BLOB Page中,否则还是存放在数据页中。
Compressed和Dynamic行记录格式
原有的Compact和Redundant统称为Antelope文件格式
新的文件格式Compressed和Dynamic统称为Barracuda
新的两种记录格式对于存放子BLOB中的数据采用了完全的行溢出的方式
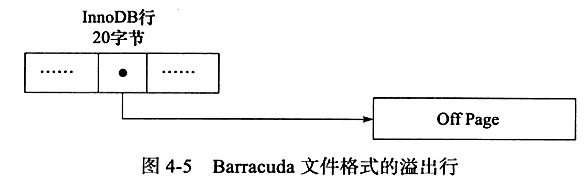
而Compressed的另一个功能就是,存储在其中的行数据会以zlib的算法进行压缩。
CHAR的行结构存储
对于多机子字符编码的CHAR数据类型的存储,INNODB存储引擎在内部视为VARCHAR实现。
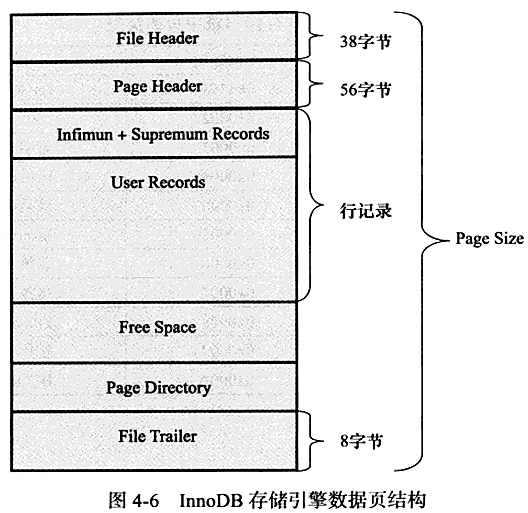
INNODB数据页结构
由以下七个部分组成:
FIle Header文件头Page Header页头Infimun和Supremum RecordsUser Records用户记录,即行记录Free Space空闲空间Page Directory页目录File Tralier文件结尾信息
约束
数据完整性
关系数据库本身能保证存储数据的完整性。使用约束机制来保障完整性。
INNODB保障实体完整性:
- 定义一个
Primary Key或Unique Key约束来保障实体的完整性。 - 还能通过编写一个触发器来保障数据完整性
域完整性保证数据每列的值满足特定的条件。通过一下途径来保障:
- 选择合适的数据类型确保一个数据值满足特定条件
- 外键约束
- 编写触发器
- 使用DEFAULT约束作为强制域完整性的一个方面。
参照完整性保证两张表之间的关系。通过外键来保障。也可以通过触发器来强制执行。
对于INNODB存储引擎本身而言,提供了以下几种约束:
Primary KeyUnique KeyForeign KeyDefaultNOT NULL
约束的创建与查找
创建方式:
- 创建表时定义
- ALTER TABLE命令来创建约束。
创建主键和唯一索引,主键约束名为PRIMARY,唯一索引约束名为列名。
CREATE TABLE u ( id int, name varchar(20), id_card char(18), PRIMIARY KEY(id), UNIQUE KEY (name) ); # 查询约束 select constarint_name, constraint_type from information_schema.TABLE_CONSTRAINTS where table_schema='mytest' AND table_name='u'\G;
但是使用ALTER TABLE的话可以修改唯一索引的约束名。
# uk_id_card为约束名 id_card为列名 ALTER TABLE u ADD UNIQUE KEY uk_id_card (id_card);
创建Foreign Key约束
CREATE TABLE p( id int, u_id int, primary key (id), foreign key (u_id) references p (id) );
还可以通过查看表REFERENTIAL_CONSTRAINTS,并且可以详细地了解外键的属性。
SELECT * FROM information_schema.REFERNTIAL_CONSTRAINTS WHRER constraint_schema='mytest'\G;
对错误数据的约束
在某些默认设置下,MYSQL数据库允许非法的或者不正确的数据的插入或更新,又或者可以在数据库内部转换为一个合法的值,例如像对NOT NULL的字段插入一个NULL值,MYSQL数据库会将其改为0再进行插入,因此数据库本身没有对数据的正确性进行约束。
但是上述情况MYSQL会发出警告,但是想设置为报错,必须设置参数sql_mode来严格审核输入的参数。
SET sql_mode = 'STRICT_TRANS_TABLES';
ENUM和SET约束
MYSQL数据库不支持传统的CHECK约束,但是通过ENUM和SET类型可以解决部分这样的约束需求
依旧可以设置参数sql_mode来严格要求
触发器与约束
创建触发器的语法
CREATE [DEFINER = {user | CURRENT_USER}] TRIGGER trigger_name BEFORE|AFTER INSERT|UPDATE|DELETE ON tb1_name FOR EACH ROW trigger_stmt
一个表最多创建6个触发器,也仅支持按每行记录进行触发。
可以通过创建触发器实现约束的一种手段和方法。
外键约束
CREATE TABLE parent( id INT NOT NULL PRIMARY KEY(id) )ENGINE = INNODB; CREATE TABLE child( id INT, parent_id INT, FOREIGN KEY(parent_id) REFERENCES parent(id) ON DELETE RESTRICT )ENGINE = INNODB
被引用的表为父表,引用的表称为子表。外键定义时的ON DELETE 和 ON UPDATE表示在对父表进行DELETE 和 UPDATE操作时,对子表做的操作,可以定义的子表操作有:
- CASCADE:父表进行UPDATE或者DELETE操作时,子表也进行这种操作
- SET NULL:父表发生UPDATE或者DELETE操作时,子表对应的数据设置为NULL
- NO ACTION:父表发生DELETE或者UPDATE操作时,抛出错误,不允许这类操作发生。
- RESTRICT:父表发生DELETE或者UPDATE操作时,抛出错误,不允许这类操作发生。
视图
在MYSQL中,视图是一个命名的虚表,它由一个SQL查询定义,可以当做表使用。与持久表不同的是,视图中的数据没有实际的物理存储。
视图的作用
语法:
CREATE VIEW v_t AS SELECT * FROM t WHERE id < 0;
被用作一个抽象装置,也可以起到一个安全层的作用。
分区表
概述
分区的过程是将一个表或索引分解为多个更小、更可管理的部分。就访问数据库的应用而言,从逻辑上只有一个表或者索引,但是在物理上这个表或者索引可能由数十个物理分区组成。没个分区都是独立的对象,可以独自处理,也可以作为一个更大对象的一部分进行处理。
MYSQL数据库支持的分区类型为水平分区,即将同一张表中不同行的记录分配到不同的物理文件中。MYSQL的分区都是局部分区索引,一个分区中既存放了数据又存放了索引。而全局分区是指,数据存放在各个分区中,但是所有数据的索引放在一个对象中。
查看数据库是否启动了分区功能
SHOW VARIABLES LIKE '%partition%'\G; SHOW PLUGINS\G;
使用分区,并不一定会是使得数据运行的更快。分区可能会给某些SQL语句性能提高,但是主要用于数据库高可用性的管理。
MYSQL支持的分区
-
RANGE分区:行数据基于属于一个给定连续区间的列值被放入分区。
-
LIST分区:LIST分区面向的是离散的值
-
HASH分区:根据用户自定义表达式返回值来进行分区
-
KEY分区:根据MYSQL提供的哈希函数来进行分区。
不论使用何种分区,表中存在在主键或者唯一索引时,分区列必须是唯一索引的一个组成部分。
分区类型
-
RANGE分区
# id小于10 数据插入到p0分区, id大于等于10小于20,输入插入到p1分区 CREATE TABLE t ( id INT )ENGINE=INNODB PARTITION BY RANGE(id)( PARTITION p0 VALUES LESS THAN(10), PARTITION p1 VALUES LESS THAN(20) ); 分区之后,表不再由一个ibd文件组成了,而是由多个分区Ibd文件组成。
可以通过查询
infomation_scheme架构下的PARTITIONS表来查看每个分区的具体信息SELECT * FROM information_scheme.PARTITIONS WHERE table_schema=database() AND table_name='t'\G; 如果我们插入id为30的数值,会抛出异常,不让添加。所以我们需要再添加一个MAXVALUE的值的分区。
ALTER TABLE t ADD PARTITION( partition p2 values less than maxvalue); ) RANGE主要用于日期列的分区,一个demo
CREATE TABLE sales( money INT UNSIGNED NOT NULL date DATETIME )ENGINE = INNODB PARTITION by RANGE(YEAR(date)) ( PARTITION p2008 VALUES LESS THAN (2009), PARTITION p2009 VALUES LESS THAN (2010), PARTITION p2010 VALUES LESS THAN (2011) ); 这样创建的好处是,管理sales这样表,如果要删除2008年的数据,不用执行SQL,只需删除2008年数据所在的分区即可。查询2008年的数据也会变快。
对于sales这张分区表,设计按照每年每月进行分区
CREATE TABLE sales( money INT UNSIGNED NOT NULL, date DATETIME )ENGINE = INNODB PARTITION by RANGE(YEAR(date)*100+MONTH(date)) ( PARTITION p201001 VALUES LESS THAN (201001), PARTITION p201002 VALUES LESS THAN (201002), PARTITION p201003 VALUES LESS THAN (201003) ); 但是执行先SQL的时候还是去查找了3个分区
EXPLAIN PARTITIONS SELECT * FROM sales WHERE date>='2010-01-01' AND date<='2010-01-31'\G; 这个是由于对RANGE分区的查询,优化器只能对
YEAR(),TO_DAYS(),TO_SECONDS(),UNIX_TIMESTAMP()这类函数进行优化选择。因此对于上述需求,应该更改为:CREATE TABLE sales( money INT UNSIGNED NOT NULL, date DATETIME )ENGINE = INNODB PARTITION by RANGE(TO_DAYS(date)) ( PARTITION p201001 VALUES LESS THAN (TO_DAYS('2010-02-01')), PARTITION p201002 VALUES LESS THAN (TO_DAYS('2010-03-01')), PARTITION p201003 VALUES LESS THAN (TO_DAYS('2010-04-01')) ); -
LIST分区
与RANGE分区很相似,只是分区列的值是离散的,而非连续的。
CREATE TABLE t ( a INT, b INT )ENGINE = INNODB PARTITION BY LIST(b) ( PARTITION P0 VALUES IN (1,3,5,7,9), PARTITION P1 VALUES IN (0,2,4,6,8) ); -
HASH分区
目的是将数据均匀地分布到预先定义的各个分区中,保证各分区的数据数量大致一样的。
用户不需要指定列值,只要基于将要进行哈希分区的列值指定一个列值或者表达式,以及指定分区的表要被分割成的分区数量。
CREATE TABLE t_hash( a INT, b DATETIME )ENGING=INNODB # expr返回一个整数的表达式。仅仅是字段类型为MYSQL整形的列名 PARTITION BY HASH (YEAR(b)) # 划分分区的数量 PARTITIONS 4 其实就是使用取余的方式分配到不同的分区中。
mod(YEAR(b), 4)
还支持一种LINEAR HASH的分区,语法与HASH一致。但是进行分区的判断算法不同
-
取大于分区数量的下一个2的幂值V,
V=POWER(2, CEILING(LOG(2, num))) -
所在分区
N=YEAR('2010-04-01')&(V-1)优势在于增加、删除、合并和拆分分区变得更加快捷,这有利于处理含有大量数据的表。缺点是,数据分布可能不是太均衡。
-
-
KEY分区
和HASH分区相似,不同之处HASH使用用户定义的函数进行分区,KEY分区使用MYSQL数据库提供的函数进行分区,INNODB使用哈希函数。
CREATE TABLE t_hash( a INT, b DATETIME )ENGING=INNODB PARTITION BY KEY (b) PARTITIONS 4 -
COLUMNS分区
可以对多个列的值进行分区,可以支持的数据类型为:
-
所有整型类型,浮点型不支持
-
日期类型:DATE和DATETIME
-
字符串类型:CHAR 、VARCHAR、BINARY、VARBINARY,不支持BLOB和TEXT
可以用来替代RANGE 和LIST分区
CREATE TABLE t_hash( a INT, b DATETIME )ENGING=INNODB PARTITION BY RANGE COLUMNS(b)( partition p0 values less than ('2009-01-01'), partition p1 values less than ('201--01-01'), ) PARTITIONS 4
-
子分区
子分区是在分区的基础上再进行分区,有时也称这种分区为复合分区。MYSQL允许数据库在RANGE和LIST的分区上再进行HASH或KEY的子分区。
CREATE TABLE ts(a INT, b DATE) PARTITION BY RANGE(YEAR(b)) SUBPARTITION BY HASH(TO_DAYS(b)) ( PARTITION p0 VALUES LESS THAN (1990) ( SUBPARTITION S0, SUBPARTITION s1 ) PARTITION p1 VALUES LESS THAN (2000) ( SUBPARTITION S2, SUBPARTITION s3 ) PARTITION p2 VALUES LESS THAN MAXVALUE ( SUBPARTITION S4, SUBPARTITION s5 ) );
注意点:
- 每个子分区的数量必须相同
- 要在一个分区表的任何分区上使用
SUBPARTITION来明确定义任何子分区,就必须定义所有的子分区。 - 每个
SUBPARTITION子句必须包括子分区的一个名字。 - 子分区的名必须是唯一的。
分区中的NULL值
MYSQL允许对NULL值做分区,在MYSQL中,NULL值视为小于任何一个非NULL值。
-
对于RANGE分区,如果插入了NULL值,会放在最左边的分区。
-
对于LIST分区,如果要是用NULL值,必须显式地指出哪个分区中放入NULL值,否则会报错。、
CREATE TABLE t_list( a INT, b INT )ENGINE=INNODB PARTITION BY LIST(b)( PARTITION p0 VALUES IN (1,3,5,7,9, NULL), PARTITION p1 VALUES IN (0,2,4,6,8) ) -
对于HASH和KEY分区,任何分区函数都会将含有NULL值的记录返回为0.
分区和性能
分区不一定会提升查询速度。
数据库的应用分为两类:
- 在线事务处理
OLTP - 在线分析处理
OLAP
对于OLAP应用,分区可以提升查询性能。因为OLAP大多数查询需要频繁扫描一张很大的表。假设有一个一亿行的表,其中有时间戳属性,用户的查询需要从这张表中获取一年的数据。如果按时间戳进行分区。则只需要扫响应分区即可。
对于OLTP应用,通常不会获取一张大表中10%的数据,大部分是通过索引返回几条记录即可。而根据B+树索引的原理可知,对于一张大表,一般的B+树需要2~3次的磁盘IO。因此B+树可以很好的完成操作,不需要分区的帮助。
在表和分区间交换数据
ALTER TABLE ... EXCHANGE PARTITION可以让分区或子分区中的数据与另外一个非分区的表中的数据进行交换。
- 要交换的表需和分区表有着相同的表结构,但是表不能含有分区
- 在非分区表中的数据必须和在交换的分区定义内
- 被交换的表中不能含有外键,或者其他的表含有对该表的外键引用。
- 用户除了需要ALTER INSERT和CREATE权限外,还需要DROP权限
- 使用该语句时,不会触发交换表和被交换表上的触发器
- AUTO_INCREMENT列会被重置。
ALTER TABLE e EXCHANGE PARTITION p0 WITH TABLE e2;
本文作者:Blue Mountain
本文链接:https://www.cnblogs.com/BlueMountain-HaggenDazs/p/9299250.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步