《容器实战高手课》 容器存储—— 小记随笔
容器文件系统:我在容器中读写文件怎么变慢了?
这个问题具体是我们在宿主机上,把 Linux 从 ubuntu18.04 升级到 ubuntu20.04 之后发现的。在我们做了宿主机的升级后,启动了一个容器,在容器里用 fio 这个磁盘性能测试工具,想看一下容器里文件的读写性能。结果我们很惊讶地发现,在 ubuntu 20.04 宿主机上的容器中文件读写的性能只有 ubuntu18.04 宿主机上的 1/8 左右了,那这是怎么回事呢?
知识详解
如何理解容器文件系统?
我们在容器里,运行 df 命令,你可以看到在容器中根目录 (/) 的文件系统类型是"overlay",它不是我们在普通 Linux 节点上看到的 Ext4 或者 XFS 之类常见的文件系统。

我们就说过每个容器都需要一个镜像,这个镜像就把容器中程序需要运行的二进制文件,库文件,配置文件,其他的依赖文件等全部都打包成一个镜像文件。
假如有 100 个容器镜像都是基于"ubuntu:18.04"的,每个容器镜像只是额外复制了 50MB 左右自己的应用程序到"ubuntu: 18.04"里,那么就是说在总共 50GB 的数据里,有 90% 的数据是冗余的。
理想情况下,在一个宿主机上只要下载并且存储存一份"ubuntu:18.04",所有基于"ubuntu:18.04"镜像的容器都可以共享这一份通用的部分。这样设置的话,不同容器启动的时候,只需要下载自己独特的程序部分就可以。就像下面这张图展示的这样。
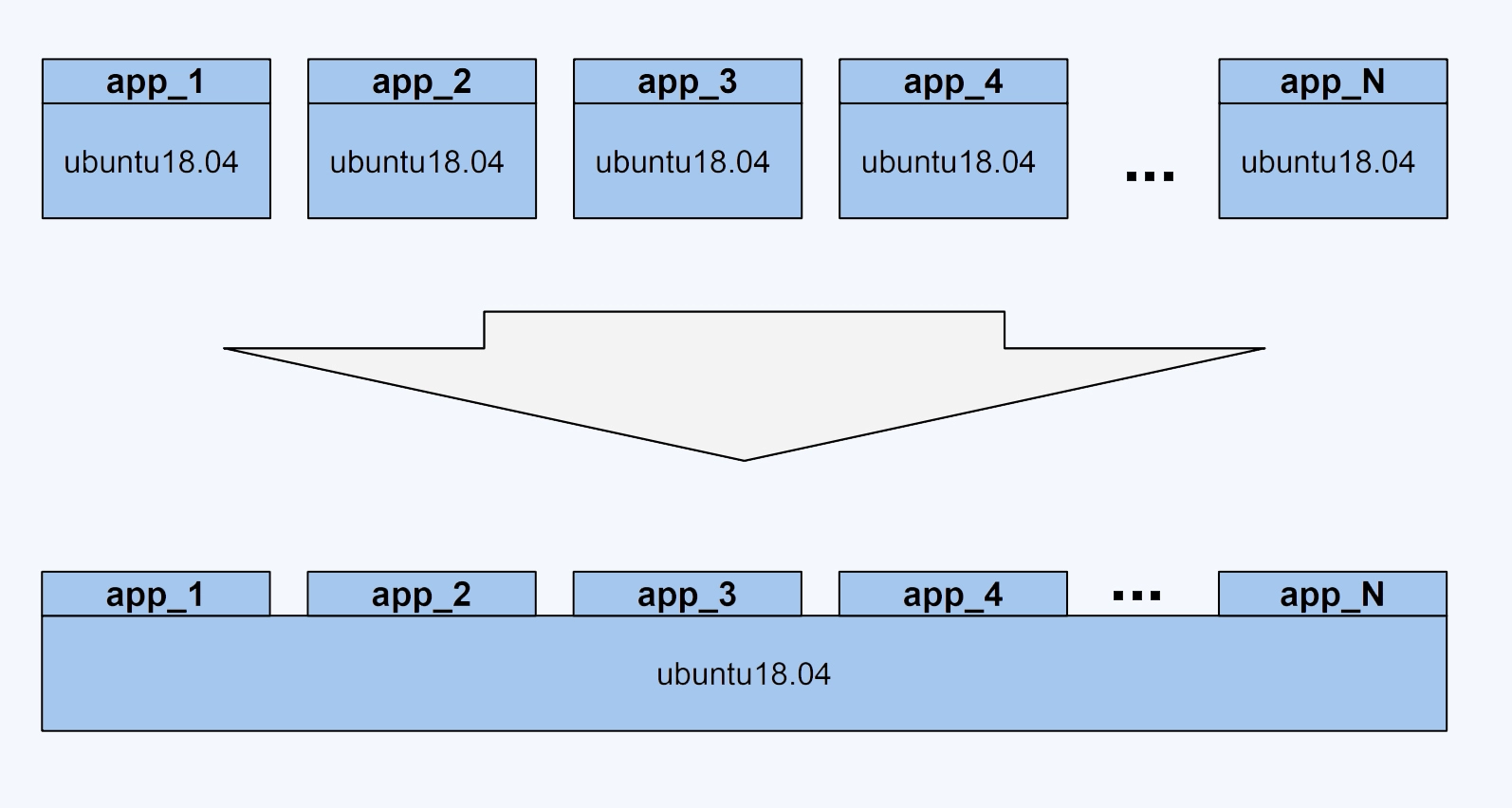
正是为了有效地减少磁盘上冗余的镜像数据,同时减少冗余的镜像数据在网络上的传输,选择一种针对于容器的文件系统是很有必要的,而这类的文件系统被称为 UnionFS。
UnionFS 这类文件系统实现的主要功能是把多个目录(处于不同的分区)一起挂载(mount)在一个目录下。这种多目录挂载的方式,正好可以解决我们刚才说的容器镜像的问题。
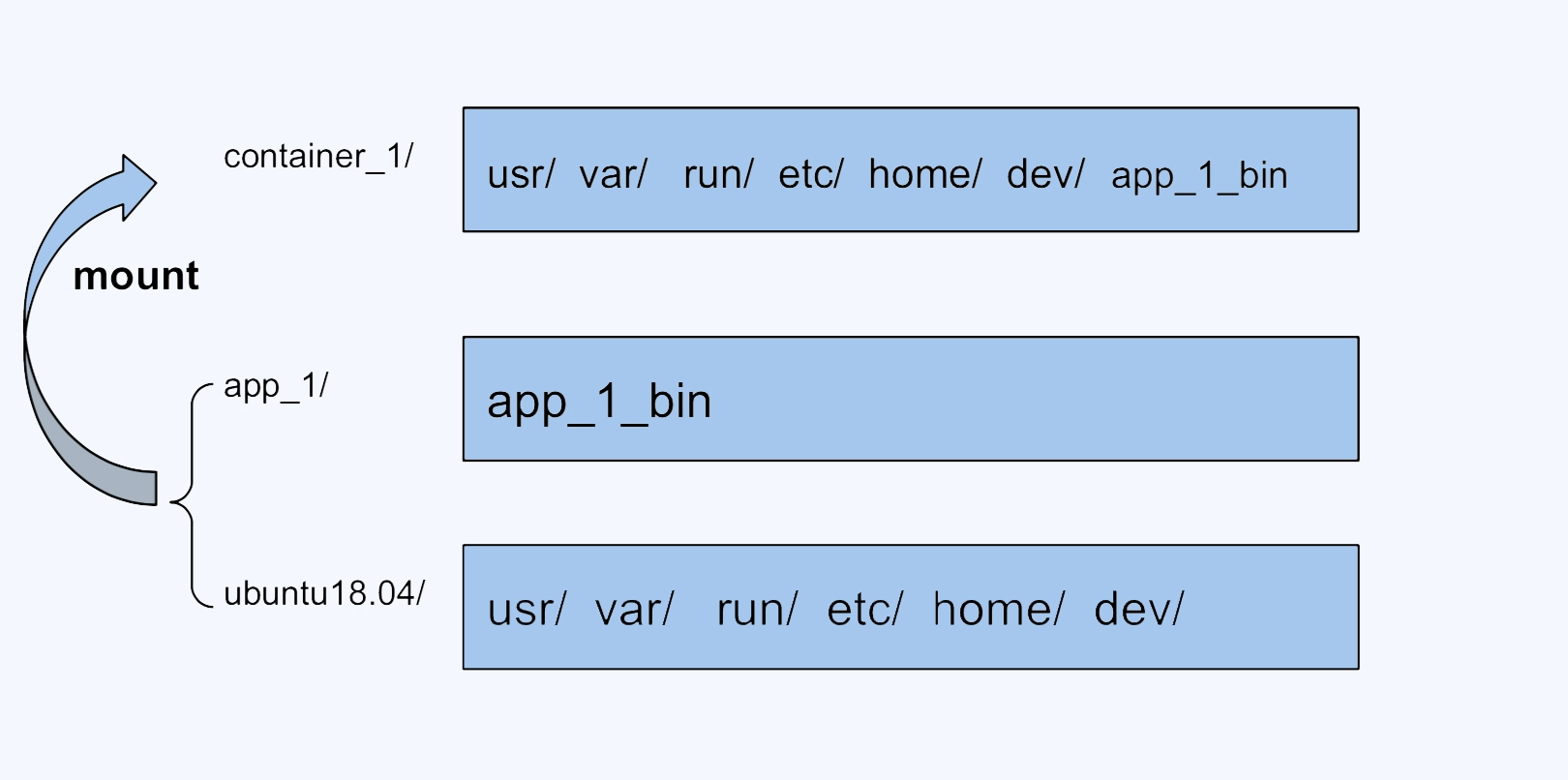
比如,我们可以把 ubuntu18.04 这个基础镜像的文件放在一个目录 ubuntu18.04/ 下,容器自己额外的程序文件 app_1_bin 放在 app_1/ 目录下。
然后,我们把这两个目录挂载到 container_1/ 这个目录下,作为容器 1 看到的文件系统;对于容器 2,就可以把 ubuntu18.04/ 和 app_2/ 两个目录一起挂载到 container_2 的目录下。
这样在节点上我们只要保留一份 ubuntu18.04 的文件就可以了。
OverlayFS
很简单,我们也拿这个例子来理解一下 OverlayFS 的一些基本概念。
#!/bin/bash umount ./merged rm upper lower merged work -r mkdir upper lower merged work echo "I'm from lower!" > lower/in_lower.txt echo "I'm from upper!" > upper/in_upper.txt # `in_both` is in both directories echo "I'm from lower!" > lower/in_both.txt echo "I'm from upper!" > upper/in_both.txt sudo mount -t overlay overlay \ -o lowerdir=./lower,upperdir=./upper,workdir=./work \ ./merged

-
首先,最下面的"lower/",也就是被 mount 两层目录中底下的这层(lowerdir)。在 OverlayFS 中,最底下这一层里的文件是不会被修改的,你可以认为它是只读的。我还想提醒你一点,在这个例子里我们只有一个 lower/ 目录,不过 OverlayFS 是支持多个 lowerdir 的。
-
然后我们看"uppder/",它是被 mount 两层目录中上面的这层 (upperdir)。在 OverlayFS 中,如果有文件的创建,修改,删除操作,那么都会在这一层反映出来,它是可读写的。
-
接着是最上面的"merged" ,它是挂载点(mount point)目录,也是用户看到的目录,用户的实际文件操作在这里进行。
-
其实还有一个"work/",这个目录没有在这个图里,它只是一个存放临时文件的目录,OverlayFS 中如果有文件修改,就会在中间过程中临时存放文件到这里。
从这个例子我们可以看到,OverlayFS 会 mount 两层目录,分别是 lower 层和 upper 层,这两层目录中的文件都会映射到挂载点上。从挂载点的视角看,upper 层的文件会覆盖 lower 层的文件,比如"in_both.txt"这个文件,在 lower 层和 upper 层都有,但是挂载点 merged/ 里看到的只是 upper 层里的 in_both.txt.
如果我们在 merged/ 目录里做文件操作,具体包括这三种。
- 第一种,新建文件,这个文件会出现在 upper/ 目录中。
- 第二种是删除文件,如果我们删除"in_upper.txt",那么这个文件会在 upper/ 目录中消失。如果删除"in_lower.txt", 在 lower/ 目录里的"in_lower.txt"文件不会有变化,只是在 upper/ 目录中增加了一个特殊文件来告诉 OverlayFS,"in_lower.txt'这个文件不能出现在 merged/ 里了,这就表示它已经被删除了。
- 还有一种操作是修改文件,类似如果修改"in_lower.txt",那么就会在 upper/ 目录中新建一个"in_lower.txt"文件,包含更新的内容,而在 lower/ 中的原来的实际文件"in_lower.txt"不会改变。
从系统的 mounts 信息中,我们可以看到 Docker 是怎么用 OverlayFS 来挂载镜像文件的。容器镜像文件可以分成多个层(layer),每层可以对应 OverlayFS 里 lowerdir 的一个目录,lowerdir 支持多个目录,也就可以支持多层的镜像文件。在容器启动后,对镜像文件中修改就会被保存在 upperdir 里了。

问题解决
ubuntu 18.04 和 ubuntu 20.04 在内核函数调用上的不同。,Linux 为了完善 OverlayFS,增加了 OverlayFS 自己的 read/write 函数接口,从而不再直接调用 OverlayFS 后端文件系统(比如 XFS,Ext4)的读写接口。但是它只实现了同步 I/O(sync I/O),并没有实现异步 I/O。
而在 fio 做文件系统性能测试的时候使用的是异步 I/O,这样才可以得到文件系统的性能最大值。所以,在内核 5.4 上就无法对 OverlayFS 测出最高的性能指标了。
容器文件Quota:容器为什么把宿主机的磁盘写满了?
问题再现
在容器中对于 OverlayFS 中写入数据,其实就是往宿主机的一个目录(upperdir)里写数据。我们现在已经写了 10GB 的数据,如果继续在容器中写入数据,结果估计你也知道了,就是会写满宿主机的磁盘。
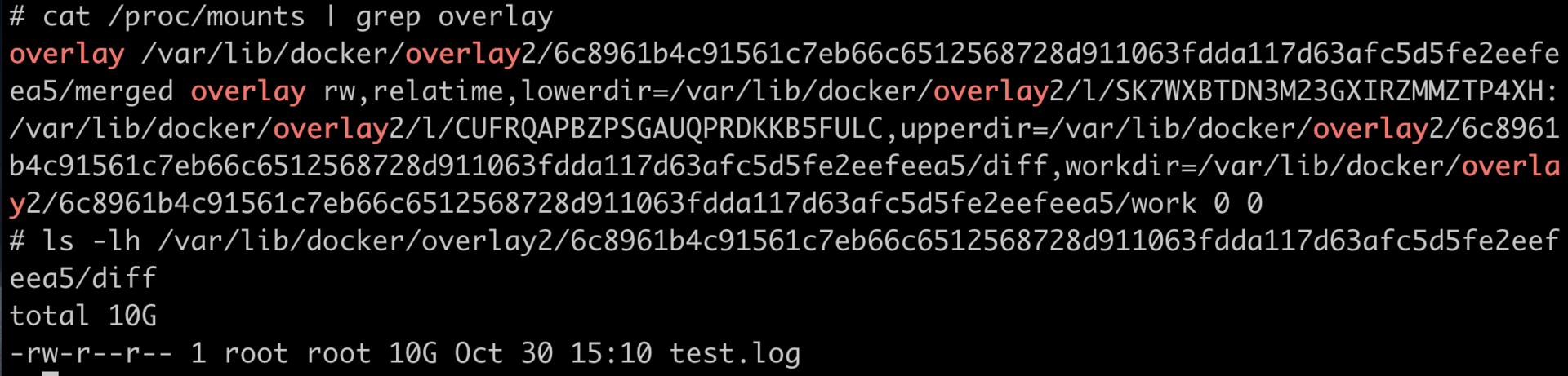
知识详解
那我们是不是可以通过限制 upperdir 目录容量的方式,来限制一个容器 OverlayFS 根目录的写入数据量呢?沿着这个思路继续往下想,因为 upperdir 在宿主机上也是一个普通的目录,这样就要看宿主机上的文件系统是否可以支持对一个目录限制容量了。对于 Linux 上最常用的两个文件系统 XFS 和 ext4,它们有一个特性 Quota。
XFS Quota
首先我们要使用 XFS Quota 特性,必须在文件系统挂载的时候加上对应的 Quota 选项,比如我们目前需要配置 Project Quota,那么这个挂载参数就是"pquota"。对于根目录来说,这个参数必须作为一个内核启动的参数"rootflags=pquota",这样设置就可以保证根目录在启动挂载的时候,带上 XFS Quota 的特性并且支持 Project 模式。
我们可以从 /proc/mounts 信息里,看看根目录是不是带"prjquota"字段。如果里面有这个字段,就可以确保文件系统已经带上了支持 project 模式的 XFS quota 特性。

下一步,我们还需要给一个指定的目录打上一个 Project ID。这个步骤我们可以使用 XFS 文件系统自带的工具 xfs_quota 来完成,然后执行下面的这个命令就可以了。
# mkdir -p /tmp/xfs_prjquota # xfs_quota -x -c 'project -s -p /tmp/xfs_prjquota 101' / Setting up project 101 (path /tmp/xfs_prjquota)... Processed 1 (/etc/projects and cmdline) paths for project 101 with recursion depth infinite (-1).
- 第一点,新建的目录 /tmp/xfs_prjquota,我们想对它做 Quota 限制。所以在这里要对它打上一个 Project ID。
- 第二点,通过 xfs_quota 这条命令,我们给 /tmp/xfs_prjquota 打上 Project ID 值 101,这个 101 是我随便选的一个数字,就是个 ID 标识,你先有个印象。在后面针对 Project 进行 Quota 限制的时候,我们还会用到这个 ID。
- 最后,我们还是使用 xfs_quota 命令,对 101(我们刚才建立的这个 Project ID)做 Quota 限制。
# xfs_quota -x -c 'limit -p bhard=10m 101' /
解决问题
对 OverlayFS 的 upperdir 目录做 XFS Quota 的限流,没错,就是这个解决办法!其实 Docker 也已经实现了限流功能,也就是用 XFS Quota 来限制容器的 OverlayFS 大小。
我们在用 docker run 启动容器的时候,加上一个参数 --storage-opt size= ,就能限制住容器 OverlayFS 文件系统可写入的最大数据量了。
容器磁盘限速:我的容器里磁盘读写为什么不稳定?
我们可以看到多个容器同时写一块磁盘的时候,它的性能受到了干扰。那么有什么办法可以保证每个容器的磁盘读写性能呢?
在 Cgroup v1 中有 blkio 子系统,它可以来限制磁盘的 I/O。
知识详解
衡量磁盘性能的两个常见的指标 IOPS 和吞吐量(Throughput)
-
IOPS 是 Input/Output Operations Per Second 的简称,也就是每秒钟磁盘读写的次数,这个数值越大,当然也就表示性能越好。
-
吞吐量(Throughput)是指每秒钟磁盘中数据的读取量,一般以 MB/s 为单位。这个读取量可以叫作吞吐量,有时候也被称为带宽(Bandwidth)。刚才我们用到的 fio 显示结果就体现了带宽。
Blkio Cgroup
blkio Cgroup 也是 Cgroups 里的一个子系统。 在 Cgroups v1 里,blkio Cgroup 的虚拟文件系统挂载点一般在"/sys/fs/cgroup/blkio/"。
在 blkio Cgroup 中,有四个最主要的参数,它们可以用来限制磁盘 I/O 性能,我列在了下面。
blkio.throttle.read_iops_device blkio.throttle.read_bps_device blkio.throttle.write_iops_device blkio.throttle.write_bps_device
如果我们要对一个控制组做限制,限制它对磁盘 /dev/vdb 的写入吞吐量不超过 10MB/s,那么我们对 blkio.throttle.write_bps_device 参数的配置就是下面这个命令。
echo "252:16 10485760" > $CGROUP_CONTAINER_PATH/blkio.throttle.write_bps_device
在这个命令中,"252:16"是 /dev/vdb 的主次设备号,你可以通过 ls -l /dev/vdb 看到这两个值,而后面的"10485760"就是 10MB 的每秒钟带宽限制。
# ls -l /dev/vdb -l brw-rw---- 1 root disk 252, 16 Nov 2 08:02 /dev/vdb
了解了 blkio Cgroup 的参数配置,我们再运行下面的这个例子,限制一个容器 blkio 的读写磁盘吞吐量,然后在这个容器里运行一下 fio,看看结果是什么。
mkdir -p /tmp/test1 rm -f /tmp/test1/* docker stop fio_test1;docker rm fio_test1 docker run -d --name fio_test1 --volume /tmp/test1:/tmp registery/fio:v1 sleep 3600 sleep 2 CONTAINER_ID=$(sudo docker ps --format "{{.ID}}\t{{.Names}}" | grep -i fio_test1 | awk '{print $1}') echo $CONTAINER_ID CGROUP_CONTAINER_PATH=$(find /sys/fs/cgroup/blkio/ -name "*$CONTAINER_ID*") echo $CGROUP_CONTAINER_PATH # To get the device major and minor id from /dev for the device that /tmp/test1 is on. echo "253:0 10485760" > $CGROUP_CONTAINER_PATH/blkio.throttle.read_bps_device echo "253:0 10485760" > $CGROUP_CONTAINER_PATH/blkio.throttle.write_bps_device docker exec fio_test1 fio -direct=1 -rw=write -ioengine=libaio -bs=4k -size=100MB -numjobs=1 -name=/tmp/fio_test1.log docker exec fio_test1 fio -direct=1 -rw=read -ioengine=libaio -bs=4k -size=100MB -numjobs=1 -name=/tmp/fio_test1.log
在加了 blkio Cgroup 限制 10MB/s 后,从 fio 运行后的输出结果里,我们可以看到这个容器对磁盘无论是读还是写,它的最大值就不会再超过 10MB/s 了。


在给每个容器都加了 blkio Cgroup 限制,限制为 10MB/s 后,即使两个容器同时在一个磁盘上写入文件,那么每个容器的写入磁盘的最大吞吐量,也不会互相干扰了。
把前面脚本里 fio 命令中的 “-direct=1” 给去掉,也就是不让 fio 运行在 Direct I/O 模式了,而是用 Buffered I/O 模式再运行一次,看看 fio 执行的输出。同时我们也可以运行 iostat 命令,查看实际的磁盘写入速度。这时候你会发现,即使我们设置了 blkio Cgroup,也根本不能限制磁盘的吞吐量了。
Direct I/O 和 Buffered I/O
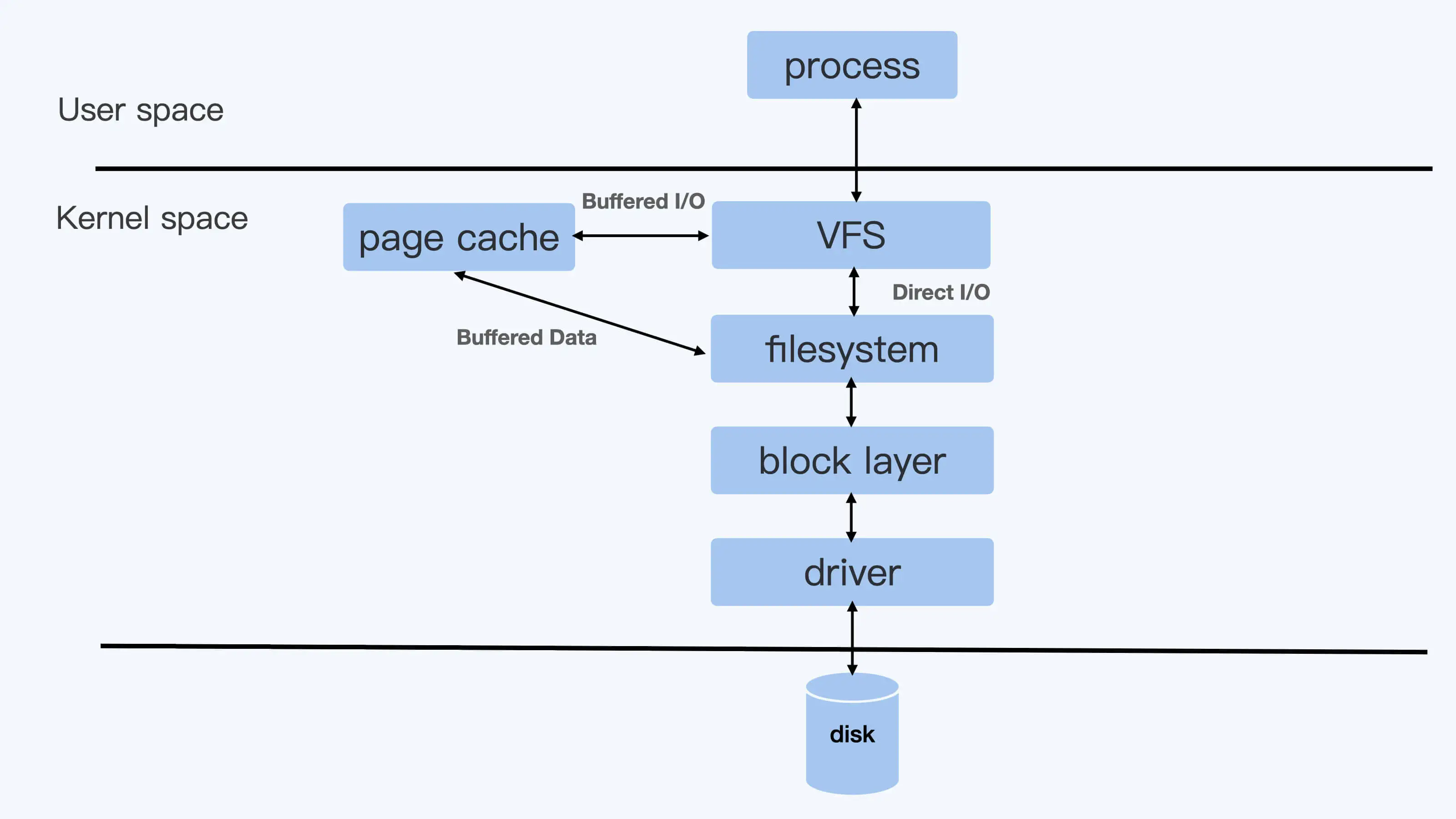
Direct I/O 模式,用户进程如果要写磁盘文件,就会通过 Linux 内核的文件系统层 (filesystem) -> 块设备层 (block layer) -> 磁盘驱动 -> 磁盘硬件,这样一路下去写入磁盘。
而如果是 Buffered I/O 模式,那么用户进程只是把文件数据写到内存中(Page Cache)就返回了,而 Linux 内核自己有线程会把内存中的数据再写入到磁盘中。在 Linux 里,由于考虑到性能问题,绝大多数的应用都会使用 Buffered I/O 模式。
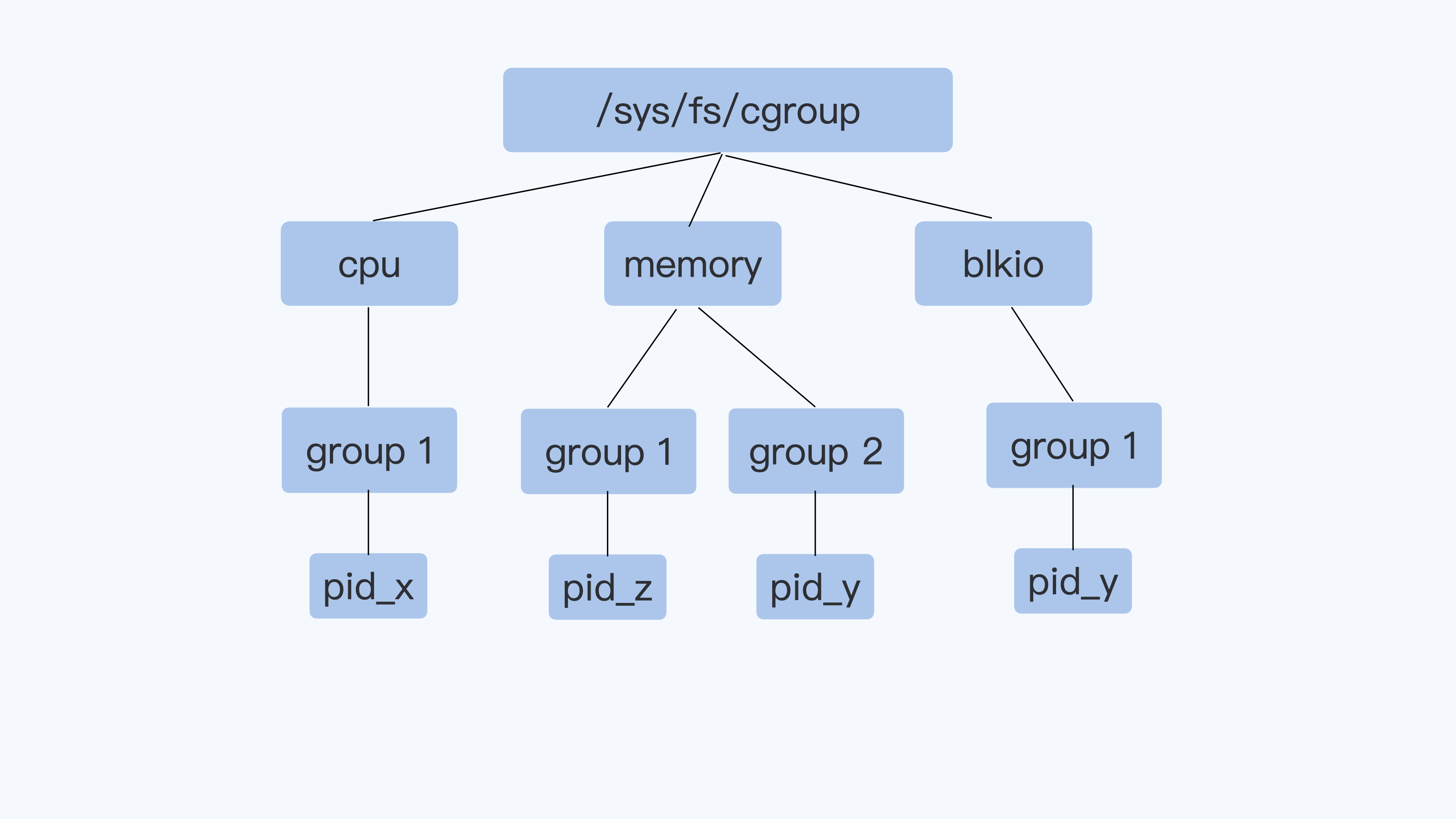
我们已经学习过了 v1 的 CPU Cgroup,memory Cgroup 和 blkio Cgroup,那么 Cgroup v1 的一个整体结构,你应该已经很熟悉了。它的每一个子系统都是独立的,资源的限制只能在子系统中发生。
就像下面图里的进程 pid_y,它可以分别属于 memory Cgroup 和 blkio Cgroup。但是在 blkio Cgroup 对进程 pid_y 做磁盘 I/O 做限制的时候,blkio 子系统是不会去关心 pid_y 用了哪些内存,哪些内存是不是属于 Page Cache,而这些 Page Cache 的页面在刷入磁盘的时候,产生的 I/O 也不会被计算到进程 pid_y 上面。
就是这个原因,导致了 blkio 在 Cgroups v1 里不能限制 Buffered I/O。
这个 Buffered I/O 限速的问题,在 Cgroup V2 里得到了解决,其实这个问题也是促使 Linux 开发者重新设计 Cgroup V2 的原因之一。
Cgroup V2
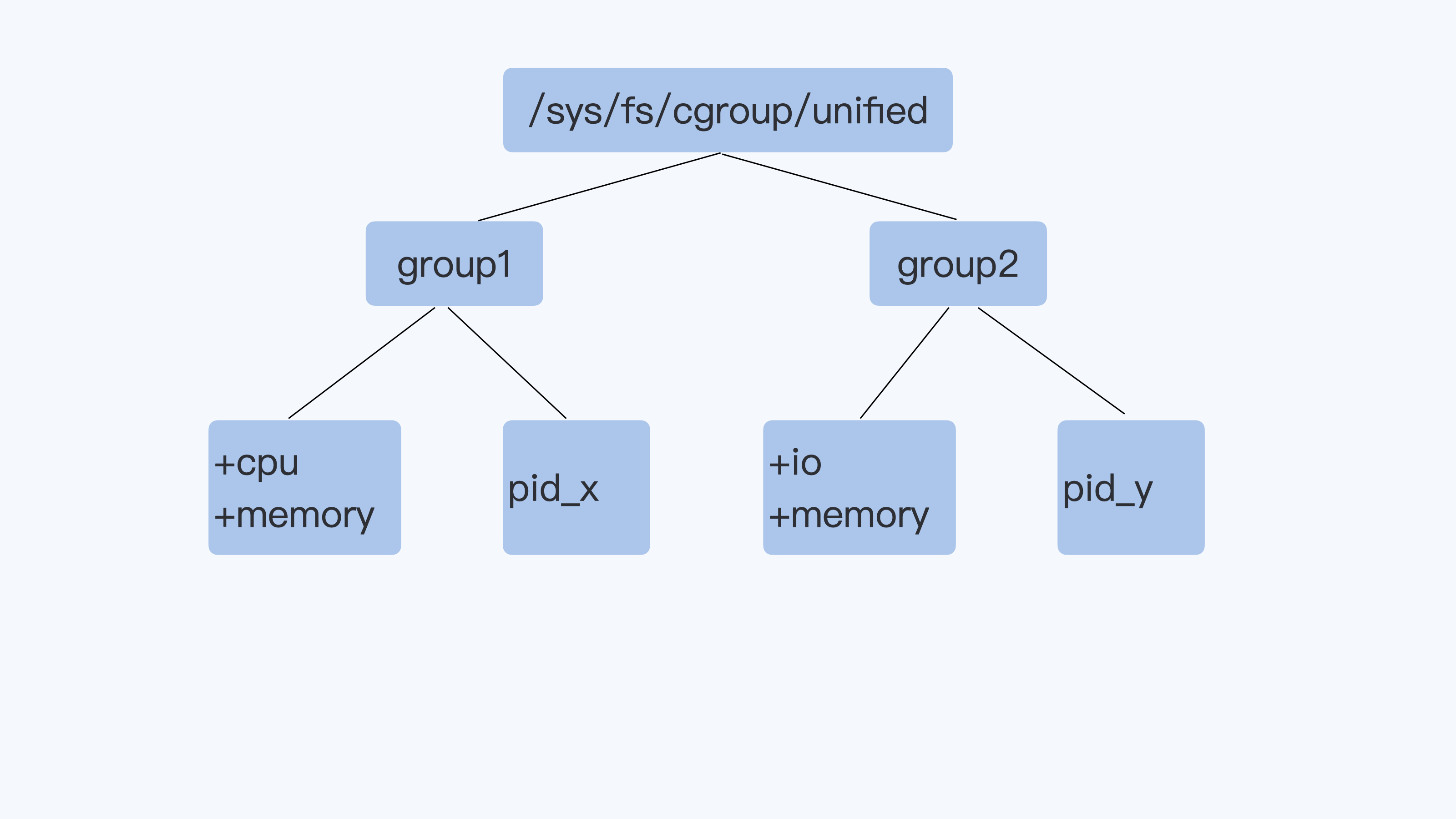
Cgroup v2 相比 Cgroup v1 做的最大的变动就是一个进程属于一个控制组,而每个控制组里可以定义自己需要的多个子系统。
比如下面的 Cgroup V2 示意图里,进程 pid_y 属于控制组 group2,而在 group2 里同时打开了 io 和 memory 子系统 (Cgroup V2 里的 io 子系统就等同于 Cgroup v1 里的 blkio 子系统)。那么,Cgroup 对进程 pid_y 的磁盘 I/O 做限制的时候,就可以考虑到进程 pid_y 写入到 Page Cache 内存的页面了,这样 buffered I/O 的磁盘限速就实现了。
系统重启后,我们会看到 Cgroup v2 的虚拟文件系统被挂载到了 /sys/fs/cgroup/unified 目录下。然后,我们用下面的这个脚本做 Cgroup v2 io 的限速配置,并且运行 fio,看看 buffered I/O 是否可以被限速。
# Create a new control group mkdir -p /sys/fs/cgroup/unified/iotest # enable the io and memory controller subsystem echo "+io +memory" > /sys/fs/cgroup/unified/cgroup.subtree_control # Add current bash pid in iotest control group. # Then all child processes of the bash will be in iotest group too, # including the fio echo $$ >/sys/fs/cgroup/unified/iotest/cgroup.procs # 256:16 are device major and minor ids, /mnt is on the device. echo "252:16 wbps=10485760" > /sys/fs/cgroup/unified/iotest/io.max cd /mnt #Run the fio in non direct I/O mode fio -iodepth=1 -rw=write -ioengine=libaio -bs=4k -size=1G -numjobs=1 -name=./fio.test
在这个例子里,我们建立了一个名叫 iotest 的控制组,并且在这个控制组里加入了 io 和 Memory 两个控制子系统,对磁盘最大吞吐量的设置为 10MB。运行 fio 的时候不加"-direct=1",也就是让 fio 运行在 buffered I/O 模式下。
运行 fio 写入 1GB 的数据后,你会发现 fio 马上就执行完了,因为系统上有足够的内存,fio 把数据写入内存就返回了,不过只要你再运行”iostat -xz 10” 这个命令,你就可以看到磁盘 vdb 上稳定的写入速率是 10240wkB/s,也就是我们在 io Cgroup 里限制的 10MB/s。
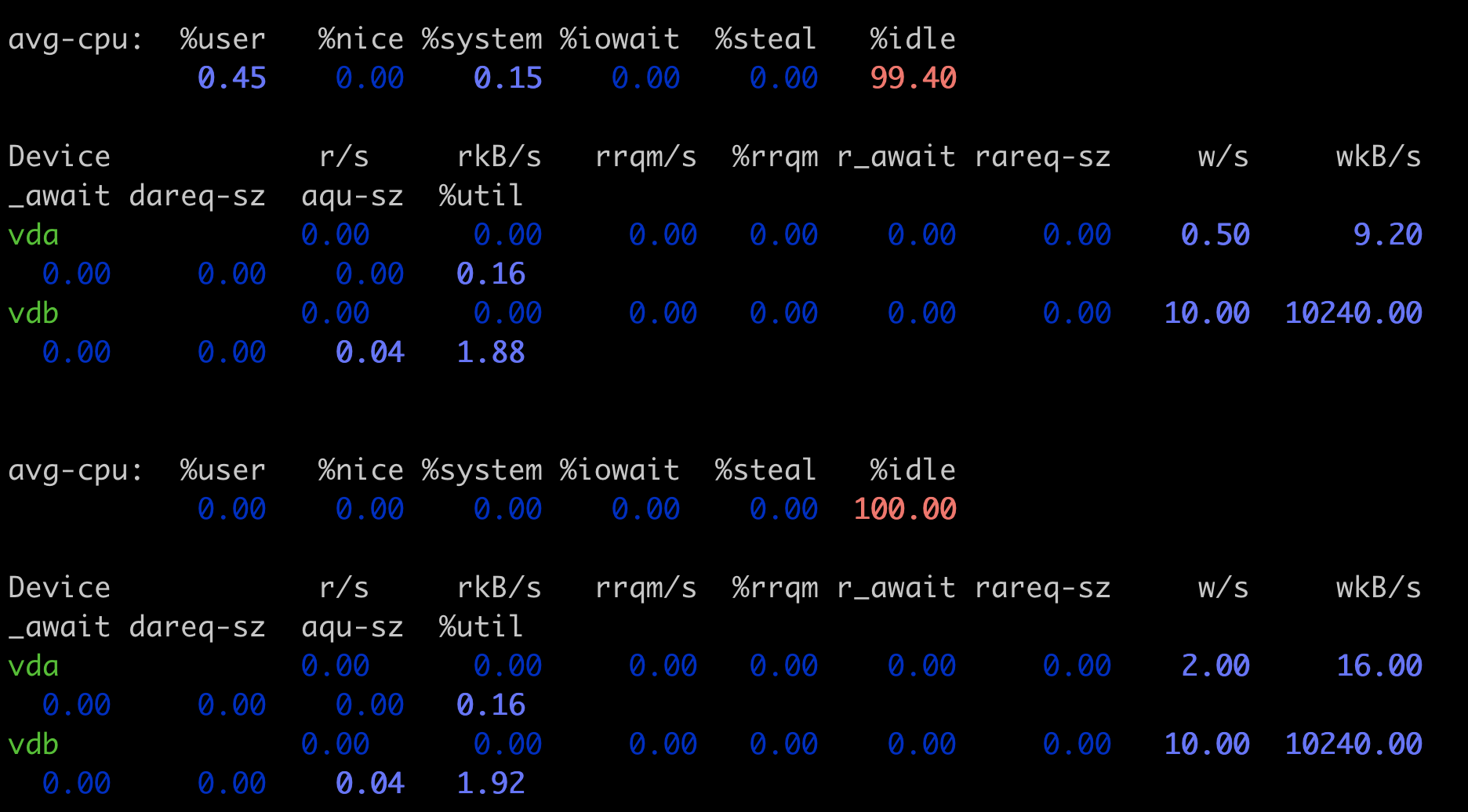
看到这个结果,我们证实了 Cgoupv2 io+Memory 两个子系统一起使用,就可以对 buffered I/O 控制磁盘写入速率。
容器中的内存与I/O:容器写文件的延时为什么波动很大?
当使用 Buffered I/O 的应用程序从虚拟机迁移到容器,这时我们就会发现多了 Memory Cgroup 的限制之后,write() 写相同大小的数据块花费的时间,延时波动会比较大。
时间波动是因为 Dirty Pages 的影响么?
我们对文件的写入操作是 Buffered I/O。在前一讲中,我们其实已经知道了,对于 Buffer I/O,用户的数据是先写入到 Page Cache 里的。而这些写入了数据的内存页面,在它们没有被写入到磁盘文件之前,就被叫作 dirty pages。
Linux 内核会有专门的内核线程(每个磁盘设备对应的 kworker/flush 线程)把 dirty pages 写入到磁盘中。那我们自然会这样猜测,也许是 Linux 内核对 dirty pages 的操作影响了 Buffered I/O 的写操作?
想要验证这个想法,我们需要先来看看 dirty pages 是在什么时候被写入到磁盘的。这里就要用到 /proc/sys/vm 里和 dirty page 相关的内核参数了,我们需要知道所有相关参数的含义,才能判断出最后真正导致问题发生的原因。
现在我们挨个来看一下。为了方便后面的讲述,我们可以设定一个比值 A,A 等于 dirty pages 的内存 / 节点可用内存 *100%。
-
第一个参数,dirty_background_ratio,这个参数里的数值是一个百分比值,缺省是 10%。如果比值 A 大于 dirty_background_ratio 的话,比如大于默认的 10%,内核 flush 线程就会把 dirty pages 刷到磁盘里。
-
第二个参数,是和 dirty_background_ratio 相对应一个参数,也就是 dirty_background_bytes,它和 dirty_background_ratio 作用相同。区别只是 dirty_background_bytes 是具体的字节数,它用来定义的是 dirty pages 内存的临界值,而不是比例值。
这里你还要注意,dirty_background_ratio 和 dirty_background_bytes 只有一个可以起作用,如果你给其中一个赋值之后,另外一个参数就归 0 了。
- 接下来我们看第三个参数,dirty_ratio,这个参数的数值也是一个百分比值,缺省是 20%。
如果比值 A,大于参数 dirty_ratio 的值,比如大于默认设置的 20%,这时候正在执行 Buffered I/O 写文件的进程就会被阻塞住,直到它写的数据页面都写到磁盘为止。
-
同样,第四个参数 dirty_bytes 与 dirty_ratio 相对应,它们的关系和 dirty_background_ratio 与 dirty_background_bytes 一样。我们给其中一个赋值后,另一个就会归零。
-
然后我们来看 dirty_writeback_centisecs,这个参数的值是个时间值,以百分之一秒为单位,缺省值是 500,也就是 5 秒钟。它表示每 5 秒钟会唤醒内核的 flush 线程来处理 dirty pages。
-
最后还有 dirty_expire_centisecs,这个参数的值也是一个时间值,以百分之一秒为单位,缺省值是 3000,也就是 30 秒钟。它定义了 dirty page 在内存中存放的最长时间,如果一个 dirty page 超过这里定义的时间,那么内核的 flush 线程也会把这个页面写入磁盘。
调试问题
第一步,我们要找到内核中 write() 这个系统调用函数下,又调用了哪些子函数。想找出主要的子函数我们可以查看代码,也可以用 perf 这个工具来得到。
然后是第二步,得到了 write() 的主要子函数之后,我们可以用 ftrace 这个工具来 trace 这些函数的执行时间,这样就可以找到花费时间最长的函数了。
perf record -a -g -p <pid>
等写磁盘的进程退出之后,这个 perf record 也就停止了。这时我们再执行 perf report 查看结果。把 vfs_write() 函数展开之后,我们就可以看到,write() 这个系统调用下面的调用到了哪些主要的子函数,到这里第一步就完成了。
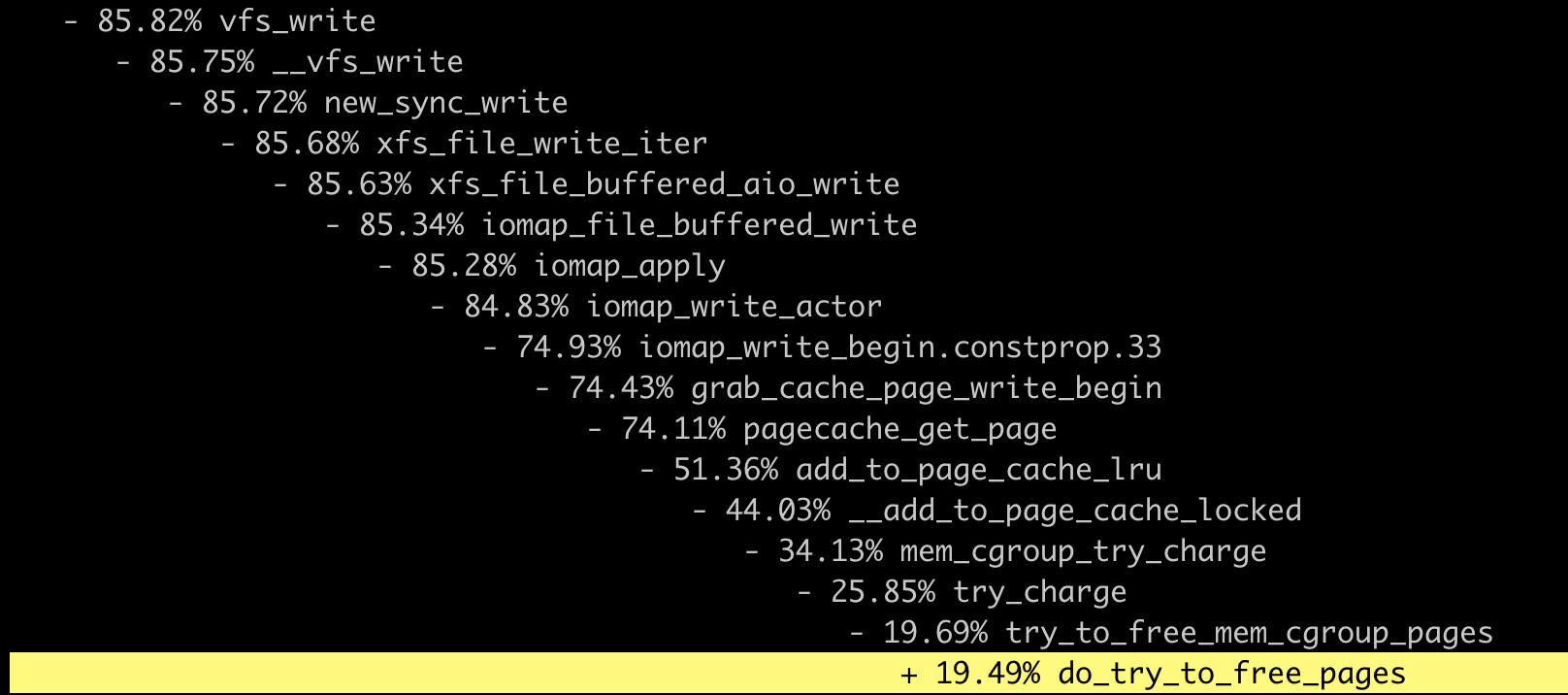
下面再来做第二步,我们把主要的函数写入到 ftrace 的 set_ftrace_filter 里,然后把 ftrace 的 tracer 设置为 function_graph,并且打开 tracing_on 开启追踪。
# cd /sys/kernel/debug/tracing # echo vfs_write >> set_ftrace_filter # echo xfs_file_write_iter >> set_ftrace_filter # echo xfs_file_buffered_aio_write >> set_ftrace_filter # echo iomap_file_buffered_write # echo iomap_file_buffered_write >> set_ftrace_filter # echo pagecache_get_page >> set_ftrace_filter # echo try_to_free_mem_cgroup_pages >> set_ftrace_filter # echo try_charge >> set_ftrace_filter # echo mem_cgroup_try_charge >> set_ftrace_filter # echo function_graph > current_tracer # echo 1 > tracing_on
这些设置完成之后,我们再运行一下容器中的写磁盘程序,同时从 ftrace 的 trace_pipe 中读取出追踪到的这些函数。
这时我们可以看到,当需要申请 Page Cache 页面的时候,write() 系统调用会反复地调用 mem_cgroup_try_charge(),并且在释放页面的时候,函数 do_try_to_free_pages() 花费的时间特别长,有 50+us(时间单位,micro-seconds)这么多。
1) | vfs_write() { 1) | xfs_file_write_iter [xfs]() { 1) | xfs_file_buffered_aio_write [xfs]() { 1) | iomap_file_buffered_write() { 1) | pagecache_get_page() { 1) | mem_cgroup_try_charge() { 1) 0.338 us | try_charge(); 1) 0.791 us | } 1) 4.127 us | } … 1) | pagecache_get_page() { 1) | mem_cgroup_try_charge() { 1) | try_charge() { 1) | try_to_free_mem_cgroup_pages() { 1) + 52.798 us | do_try_to_free_pages(); 1) + 53.958 us | } 1) + 54.751 us | } 1) + 55.188 us | } 1) + 56.742 us | } … 1) ! 109.925 us | } 1) ! 110.558 us | } 1) ! 110.984 us | } 1) ! 111.515 us | }
看到这个 ftrace 的结果,你是不是会想到,我们在容器内存那一讲中提到的 Page Cahe 呢?是的,这个问题的确和 Page Cache 有关,Linux 会把所有的空闲内存利用起来,一旦有 Buffered I/O,这些内存都会被用作 Page Cache。
当容器加了 Memory Cgroup 限制了内存之后,对于容器里的 Buffered I/O,就只能使用容器中允许使用的最大内存来做 Page Cache。
那么如果容器在做内存限制的时候,Cgroup 中 memory.limit_in_bytes 设置得比较小,而容器中的进程又有很大量的 I/O,这样申请新的 Page Cache 内存的时候,又会不断释放老的内存页面,这些操作就会带来额外的系统开销了。
重点总结
根据 ftrace 的结果,我们发现写数据到 Page Cache 的时候,需要不断地去释放原有的页面,这个时间开销是最大的。造成容器中 Buffered I/O write() 不稳定的原因,正是容器在限制内存之后,Page Cache 的数量较小并且不断申请释放。
其实这个问题也提醒了我们:在对容器做 Memory Cgroup 限制内存大小的时候,不仅要考虑容器中进程实际使用的内存量,还要考虑容器中程序 I/O 的量,合理预留足够的内存作为 Buffered I/O 的 Page Cache。
还有一个解决思路是,我们在程序中自己管理文件的 cache 并且调用 Direct I/O 来读写文件,这样才会对应用程序的性能有一个更好的预期。
本文作者:Blue Mountain
本文链接:https://www.cnblogs.com/BlueMountain-HaggenDazs/p/18141142
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步